本文介绍: 和的常用算法。它用于评估一个词对于一个文档集合中某个文档的重要性。这个算法的基本思想是:如果一个词在一个文档中频繁出现,并且在整个文档集合中很少出现,那么这个词对于这个文档的重要性较高。。
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用算法。它用于评估一个词对于一个文档集合中某个文档的重要性。
这个算法的基本思想是:如果一个词在一个文档中频繁出现,并且在整个文档集合中很少出现,那么这个词对于这个文档的重要性较高。TF-IDF的计算涉及两个部分:词频(TF)和逆文档频率(IDF)。
1. 词频(TF)
词频(TF):用于衡量一个词在文档中的出现频率。计算方式是指定词在文档中出现的次数除以文档的总词数。

2. 逆文档频率(IDF)
逆文档频率(IDF):用于衡量一个词在整个文档集合中的普遍程度。计算方式是文档集合中文档总数除以包含该词的文档数量的对数。

其中,分母加1是为了避免分母为零。
3. TF-IDF
TF-IDF:将词频和逆文档频率相乘得到最终的TF-IDF值。
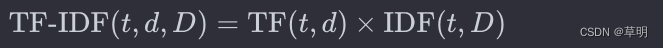
TF-IDF的应用场景包括文本相似性计算、搜索引擎排名、文本分类等。
在实际使用中,TF-IDF算法有一些变种和优化,例如考虑归一化、平滑等因素,具体实现可能会因应用场景而有所不同。
原文地址:https://blog.csdn.net/galoiszhou/article/details/135332669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52482.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)
![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)



