本文介绍: 2、使用 torch.no_grad(): 在该上下文管理器中执行的所有操作都不会追踪梯度。torchvision.datasets所支持的所有数据集,它都内置了相应的数据集接口。Torchvision 库就是常用数据集 + 常见网络模型 + 常用图像处理方法。张量 ,最基础的运算单位 ,一个多维矩阵,一个可以运行在gpu上的多维数据。1、使用 .detach(): 创建一个内容相同但不需要梯度的新张量。
12.28 Learn Pytorch
一、神经网络
二、pytorch的整体框架
1.torch
(1).Tensor概念
张量 ,最基础的运算单位 ,一个多维矩阵,一个可以运行在gpu上的多维数据
(2).Tensor的创建
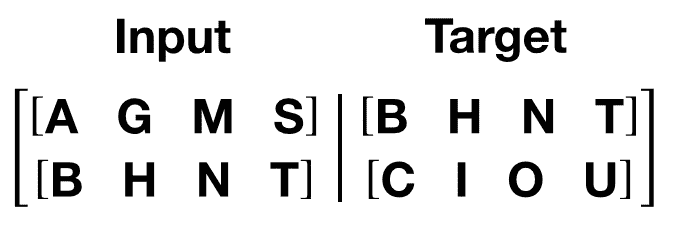
(3).Tensor的运算
2.torch数据读取
(1).dataset类
自定义数据集
调用数据集
(2).dataloader类
3…torchvision
数据调用
Torchvision 库就是常用数据集 + 常见网络模型 + 常用图像处理方法
torchvision.datasets所支持的所有数据集,它都内置了相应的数据集接口
torchvision.transforms
图像处理工具
数据类型变换
图像变换操作
例:
多变换操作组合
4.卷积神经网络 Torch.nn
4.torch.autograd
(1).相关概念
(2).基本使用
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


![[pytorch入门] 2. tensorboard](https://img-blog.csdnimg.cn/direct/08e3c80aa9844665827398aeedc175a2.png)

