An Extractive-and-Abstractive Framework for Source Code Summarization
1. Introduction
代码摘要可以细分为抽取式代码摘要(抽取方法)和抽象代码摘要(抽象方法):
- 提取方法:使用检索技术从代码片段中提取重要语句和关键字的子集,并生成保留重要语句和关键字中事实细节的摘要。然而,这样的子集可能会丢失标识符或实体命名,因此生成的摘要的自然度通常很差。
- 抽象方法:抽象方法广泛采用基于编码器-解码器架构的神经网络模型,然后在大型代码评论语料库上训练模型。编码器首先将代码片段转换为嵌入表示(也称为上下文向量),然后解码器将上下文向量解码为简短的自然语言摘要。然而,生成的摘要常常会遗漏重要的事实细节。
本文提出了一种用于代码摘要的提取和抽象框架,该框架继承了提取和抽象方法的优点并屏蔽了它们各自的缺点。具体来说,我们利用成对的代码片段和注释来训练提取器(提取方法)和抽象器(抽象方法)。训练有素的提取器可用于预测代码片段中的重要语句。这些重要的语句和整个代码片段被输入到抽象器中以生成简短的自然语言摘要。训练有素的抽象器首先利用两个单独的编码器将重要语句和整个代码片段转换为两个上下文向量。然后,将两个上下文向量融合以产生融合向量,该融合向量将被传递到解码器以生成自然语言摘要。与现有的抽象方法相比,我们的框架配备了提取器,基本上平衡了对重要信息和全局上下文信息的关注,降低了丢失重要事实细节的风险并提高了整体性能。
2. Model
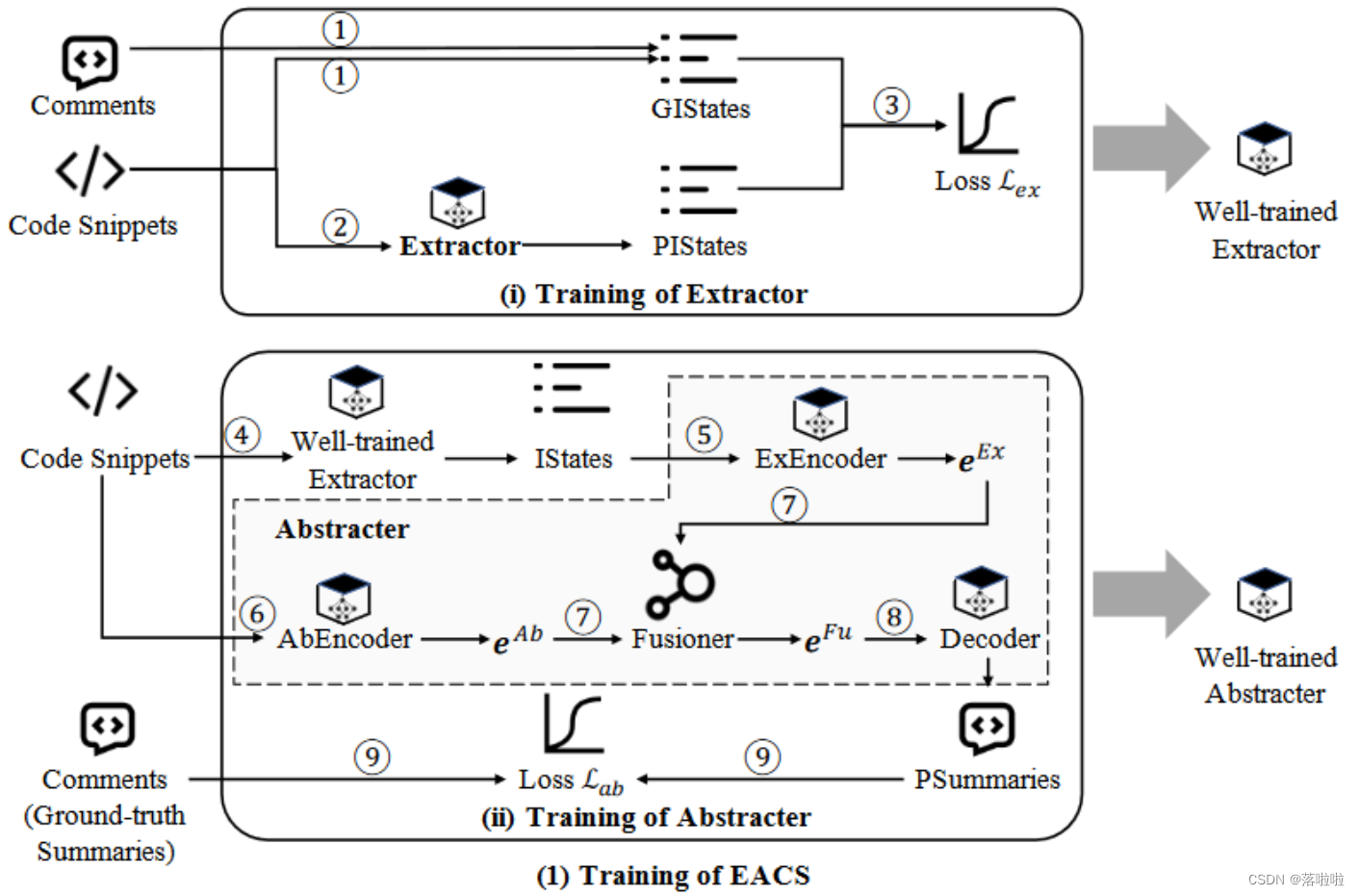
2.1 Overview
阶段 (i) 的目标是训练一个能够从给定代码片段中提取重要语句的提取器。为了训练这样的提取器,EACS 首先根据代码片段中每个语句的信息性生成真实的重要语句 (GIStates)。然后,EACS 使用提取器提取预测的重要语句 (PIStates)。在此阶段,提取器的模型参数被随机初始化并根据损失
L
E
x
L_{Ex}
LEx 迭代更新。
L
E
x
L_{Ex}
LEx 是根据 PIStates 和 GIStates 计算的。
阶段(ii)的目标是训练一个能够为给定代码片段生成简洁自然语言摘要的抽象器。为了训练这样的抽象器,给定一个代码片段,EACS 首先使用训练好的提取器来提取重要的语句 (IState)。 IStates 将通过名为 ExEncoder 的编码器进一步转换为嵌入表示
e
E
x
e^{Ex}
eEx。同时,EACS 使用另一个名为 AbEncoder 的编码器将整个代码片段转换为嵌入表示
e
A
b
e^{Ab}
eAb。然后,EACS 通过融合
e
E
x
e^{Ex}
eEx和
e
A
b
e^{Ab}
eAb生成融合嵌入表示
e
F
u
e^{Fu}
eFu。进一步,
e
F
u
e^{Fu}
eFu将被传递到解码器(Decoder)以生成预测摘要(PSummaries)。在此阶段,抽象器的模型参数(包括ExEncoder、AbEncoder和Decoder)也被随机初始化。 EACS根据损失
L
A
b
L_{Ab}
LAb迭代更新抽象器的参数。
L
A
b
L_{Ab}
LAb是根据 PSummaries 和真实摘要计算的。
2.2 Training of EACS
2.2.1 Part i : Training of Extractor
令 c 表示包含一组语句 stat = [stat1, stat2, …, statn] 的代码片段,其中
s
t
a
t
i
stat_i
stati 是 c 中的第 i 个语句。提取代码摘要可以定义为为每个
s
t
a
t
i
stat_i
stati分配标签
l
i
∈
{
0
,
1
}
l_i ∈ {0, 1}
li∈{0,1} 的任务。该标签表示语句
s
t
a
t
i
stat_i
stati 中包含的事实细节是否应该被包含在摘要中。假设摘要代表了代码片段的重要内容。因此,我们可以将提取器视为一个分类器,它接收代码片段的所有语句并预测重要的语句。
提取器的训练通过三个步骤完成:➀ 生成真实的重要语句(GIStates),➁ 生成预测的重要语句(PIStates),➂ 基于 GIStates 和 PIStates 计算损失(
L
E
x
L_{Ex}
LEx)并更新模型参数。
-
生成真实的重要语句
如前所述,我们的目标是训练一个提取器,可以预测代码片段 c 中的重要语句。我们将 c 中语句的标签表示为
l
=
[
l
1
,
l
2
,
⋅
⋅
⋅
,
l
n
]
l = [l_1, l_2, · · · , l_n]
l=[l1,l2,⋅⋅⋅,ln]。
l
i
∈
{
0
,
1
}
li ∈ {0, 1}
li∈{0,1} 是语句
s
t
a
t
i
stat_i
stati 的标签。
l
i
=
1
l_i = 1
li=1 表示该
s
t
a
t
i
stat_i
stati 是一个信息丰富(重要)的陈述;否则,就不是。
我们构建一个训练数据集,其中每个样本都是一对 stat 和相应的标签
l
^
hat{l}
l^。我们将
l
^
hat{l}
l^ 视为 stat 的真实标签。
为了获得真实标签,我们首先测量每个语句
s
t
a
t
i
∈
s
t
a
t
stat_i ∈ stat
stati∈stat 的信息量
i
n
f
o
r
m
a
t
i
v
i
t
y
informativity
informativity。具体来说,信息量是通过语句
s
t
a
t
i
stat_i
stati 和参考语句(reference statements)之间的 ROUGE-L 分数来衡量的。我们将代码片段的注释视为参考语句。然后,我们根据信息量对语句进行排序,并按照信息量从高到低的顺序选择它们。我们每次选择一个语句。如果新选择的语句可以增加所有所选语句的信息量,则它将被视为真实的重要语句。最后,我们获得真实的标签,即所有真实的重要陈述(GIStates)。
-
生成预测的重要语句
我们使用提取器(Extractor)来预测代码片段中的重要语句。提取器是由编码器和分类层组成的神经网络模型。编码器将语句转换为嵌入表示。分类层根据语句的嵌入表示来预测语句的标签。
编码器本质上执行将复杂源代码转换为数字(嵌入)表示的代码表示任务,同时保留语义。这种嵌入表示对于程序计算来说很方便。因此,我们的EACS可以采用大量现有的基于深度学习的代码表示技术来设计编码器。具体来说,语句
e
s
t
a
t
e^{stat}
estat 的嵌入表示可以形式化为
e
s
t
a
t
=
e
n
c
o
d
e
r
(
s
t
a
t
)
e^{stat}=encoder(stat)
estat=encoder(stat)。
e
n
c
o
d
e
r
(
⋅
)
encoder(·)
encoder(⋅) 是一种神经网络架构(例如 LSTM)或预训练模型(例如 CodeBERT),可以在保留语义(即嵌入表示)的情况下对代码语句序列进行数值化。我们通过实验发现,在代码摘要任务中,通过微调预训练模型获得的编码器比基于神经网络架构从头开始训练的编码器表现更好。
分类层与嵌入表示
e
s
t
a
t
e^{stat}
estat 相连接。在实践中,我们采用
s
o
f
t
m
a
x
softmax
softmax 作为分类层,即
l
=
s
o
f
t
m
a
x
(
e
s
t
a
t
)
l = softmax (e^{stat})
l=softmax(estat)。
-
模型训练
在训练过程中,我们根据 sigmoid 交叉熵损失更新提取器的模型参数 θ,即
L
E
x
(
θ
)
L_{Ex} (θ)
LEx(θ),计算如下:
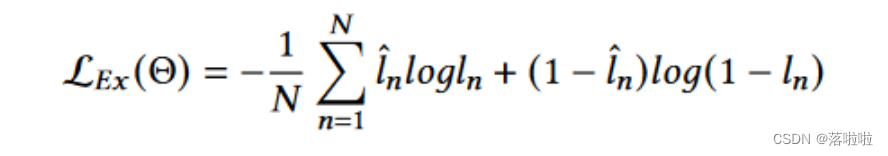
其中
l
^
n
∈
0
,
1
hat{l}_n ∈ 0, 1
l^n∈0,1 是第 n 个语句的真实标签,N 是语句的数量。
l
^
n
=
1
hat{l}_n = 1
l^n=1 表示模型应关注第 n 个语句中包含的 事实细节,以利于最终生成摘要。
一旦生成训练好的提取器,我们就可以使用它从给定的代码片段中提取重要的语句。
2.2.2 Part ii : Training of Abstracter
抽象器的训练通过六个步骤完成:➃ 提取重要语句(IState),➄ 和 ➅ 生成重要语句和整个代码的嵌入表示(
e
E
x
e^{Ex}
eEx 和
e
A
b
e^{Ab}
eAb) ➆ 基于
e
E
x
e^{Ex}
eEx 和
e
A
b
e^{Ab}
eAb 生成融合表示
e
F
u
e^{Fu}
eFu,➇ 生成预测摘要,以及 ➈ 根据预测摘要(PSummaries)和真实摘要(注释)计算损失 {L_Ab} 以更新模型参数。
-
提取重要语句
为了生成摘要而不遗漏事实细节,我们的 EACS 更加关注代码片段的重要语句。这些重要的语句包在最终生成的摘要中的事实细节。因此,与现有抽象代码摘要技术中的抽象器不同,EACS的抽象器将重要语句视为输入的一部分。在此步骤中,我们首先使用训练好的提取器来预测给定代码片段的语句标签。然后,标签为1的语句将被选择为重要语句(IStates)。
-
- 生成嵌入表示
步骤 ➄ 和步骤 ➅ 做了类似的事情,即利用编码器将源代码转换为嵌入表示。不同之处在于,步骤 ➄ 处理提取器选择的重要语句,而步骤 ➅ 处理整个代码片段。因此,在EACS中,我们可以使用相同的神经网络架构或预训练模型来设计ExEncoder和AbEncoder。给定一个代码片段 c = [stat1, stat2, · · · , statn],让 c′ ⊆ c 表示提取器从 c 中选择的一组重要语句,ExEncoder 和 AbEncoder 执行的任务可以形式化如下:
e
E
x
=
e
n
c
o
d
e
r
(
c
′
)
,
e
A
b
=
e
n
c
o
d
e
r
(
c
)
e^{Ex}=encoder(c’), e^{Ab}=encoder(c)
eEx=encoder(c′),eAb=encoder(c)
其中
e
E
x
e^{Ex}
eEx 和
e
A
b
e^{Ab}
eAb 表示 c’ 和 c 的嵌入表示;
e
n
c
o
d
e
r
(
.
)
encoder(.)
encoder(.) 是一种可以处理顺序输入的神经网络架构(例如 LSTM 、Transformer)或预训练模型(例如 CodeBERT)。 ExEncoder 和 AbEncoder 执行类似的任务 – 生成代码的嵌入表示,因此我们使用与提取器的编码器相同的代码表示技术来设计它们。
-
生成融合表示
在此步骤中,EACS 通过 Fusioner 组件融合
e
E
x
e^{Ex}
eEx 和
e
A
b
e^{Ab}
eAb ,生成融合嵌入表示
e
F
u
e^{Fu}
eFu。考虑到
e
E
x
e^{Ex}
eEx 和
e
A
b
e^{Ab}
eAb 没有对齐,我们以串联方式融合它们。我们尝试两种串联方式如下:
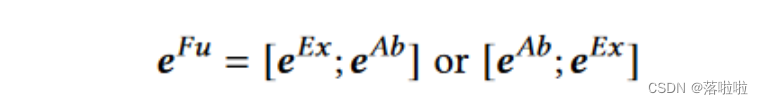
-
生成预测摘要
我们利用解码器来生成自然语言摘要。解码器接收融合嵌入表示
e
F
u
e^{Fu}
eFu 并预测单词。具体来说,基于神经网络的解码器是将上下文向量eFu展开为目标序列(即摘要的单词序列),通过以下动态模型,
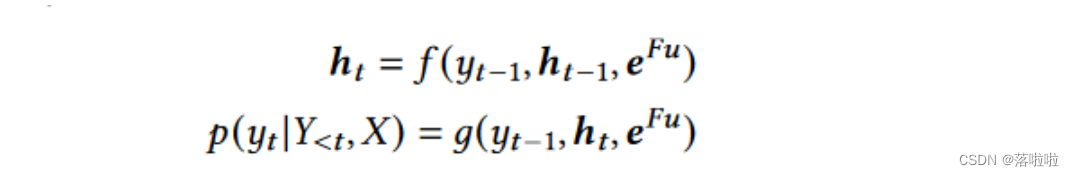
其中 f (·) 和 g(·) 是激活函数;
h
t
h_t
ht 是神经网络在时间 t 的隐藏状态;
y
t
y_t
yt 是从 t 到 g(·) 的预测目标词,其中
Y
<
t
Y_{<t}
Y<t 表示历史记录 {y1, y2, · · ·, yt -1}。预测过程通常是词汇表的分类器。从上式可以看出,生成目标词的概率与当前隐藏状态、目标序列的历史和上下文
e
F
u
e^{Fu}
eFu 有关。解码器的本质是通过优化损失函数对词汇进行分类,从而生成代表目标词
y
t
y_t
yt 特征的向量。向量经过一个softmax函数后,概率最大对应的词就是要输出的结果。
-
模型训练。
在抽象器的训练过程中,三个组件(ExEncoder、AbEncoder 和 Decoder)被联合训练,以最小化负条件对数似然,即
L
A
b
(
θ
)
L_{Ab} (θ)
LAb(θ) 计算如下:
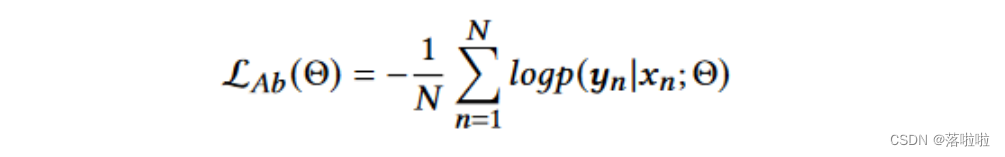
其中 θ 是抽象器的模型参数,每个 (xn, yn) 是训练集中的一个(代码片段,注释)对。
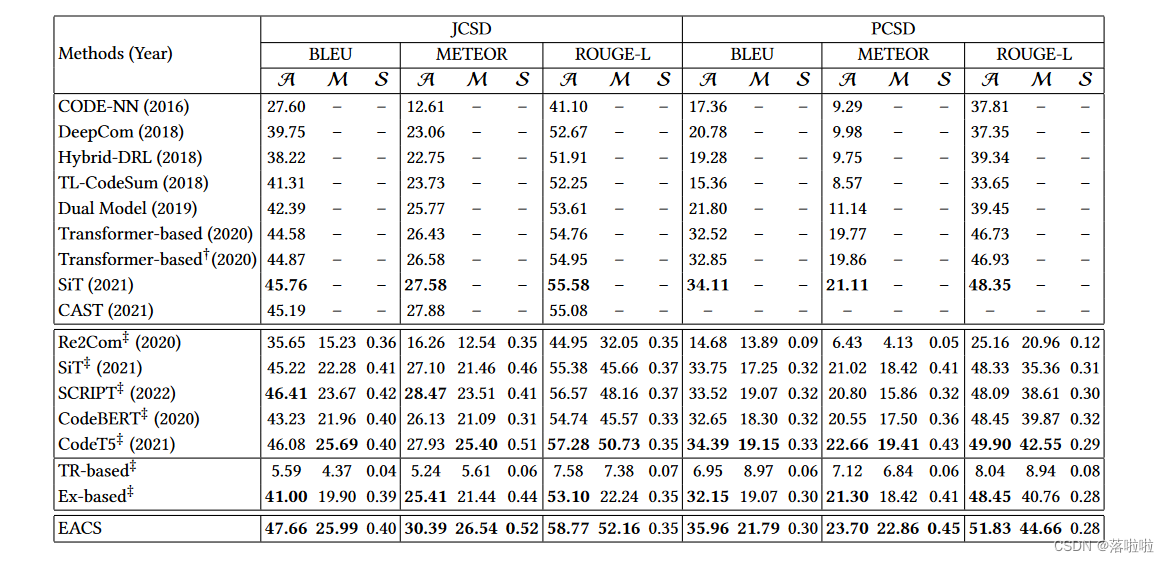
3. Evaluation
原文地址:https://blog.csdn.net/Luo_LA/article/details/135373036
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52942.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!




