一、doc_values
默认情况下,大部分字段是索引的,这样让这些字段可被搜索。倒排索引(inverted index)允许查询请求在词项列表中查找搜索项(search term),并立即获得包含该词项的文档列表。
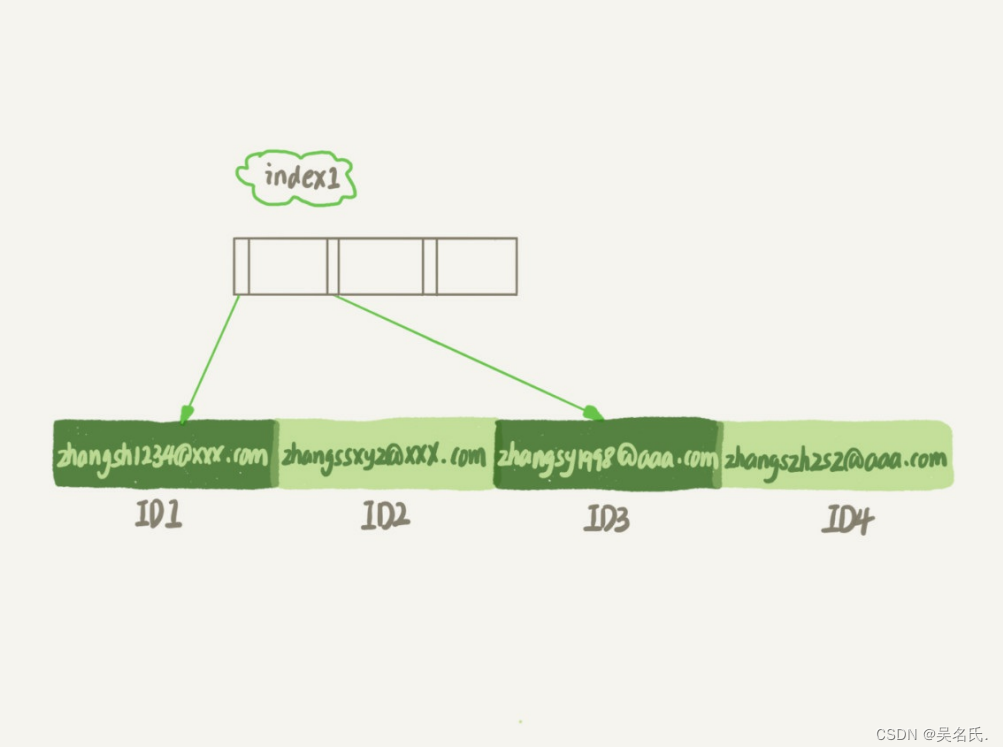
倒排索引(inverted index):
如果我们想要获得所有包含 brown 的文档的词的完整列表,我们会创建如下查询:
GET /my_index/_search
{
“query” : {
“match” : {
“body” : “brown”
}
},
“aggs” : {
“popular_terms”: {
“terms” : {
“field” : “body”
}
}
}
}
倒排索引是根据词项来排序的,所以我们首先在词项列表中找到 brown,然后扫描所有列,找到包含 brown 的文档。我们可以快速看到 Doc_1 和 Doc_2 包含 brown 这个 token。
然后,对于聚合部分,我们需要找到 Doc_1 和 Doc_2 里所有唯一的词项。用倒排索引做这件事情代价很高: 我们会迭代索引里的每个词项并收集 Doc_1 和 Doc_2 列里面 token。这很慢而且难以扩展:随着词项和文档的数量增加,执行时间也会增加。
Doc values 通过转置两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,doc values 将文档映射到它们包含的词项:

当数据被转置之后,想要收集到 Doc_1 和 Doc_2 的唯一 token 会非常容易。获得每个文档行,获取所有的词项,然后求两个集合的并集。
Doc values 可以使聚合更快、更高效并且内存友好。Doc values 的存在是因为倒排索引只对某些操作是高效的。
倒排索引的优势:在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里,聚合需要这种访问模式。
在 Elasticsearch 中,Doc Values 就是一种列式存储结构,默认情况下每个字段的 Doc Values 都是激活的,Doc Values 是在索引时创建的。当字段索引时,Elasticsearch 为了能够快速检索,会把字段的值加入倒排索引中,同时它也会存储该字段的 `Doc Values`。
Elasticsearch 中的 Doc Values 常被应用到以下场景:
- 对一个字段进行排序
- 对一个字段进行聚合
- 某些过滤,比如地理位置过滤
- 某些与字段相关的脚本计算
因为文档值(doc values)被序列化到磁盘,我们可以依靠操作系统的帮助来快速访问。当 working set 远小于节点的可用内存,系统会自动将所有的文档值保存在内存中,使得其读写十分高速;当其远大于可用内存,操作系统会自动把 Doc Values 加载到系统的页缓存中,从而避免了 jvm 堆内存溢出异常。
因此,搜索和聚合是相互紧密缠绕的。搜索使用倒排索引查找文档,聚合操作收集和聚合 doc values 里的数据。
doc values 支持大部分字段类型,但是text 字段类型不支持(因为analyzed)。

(1) status_code 字段默认启动 doc_values 属性;
(2) session_id 显式设置 doc_values = false,但是仍然可以被查询;
如果确信某字段不需要排序或者聚合,或者从脚本中访问字段值,那么我们可以设置 doc_values = false,这样可以节省磁盘空间。
二、fielddata
与 doc values 不同,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆。这意味着它本质上是不可扩展的。
fielddata可能会消耗大量的堆空间,尤其是在加载高基数(high cardinality)text字段时。一旦fielddata已加载到堆中,它将在该段的生命周期内保留。此外,加载fielddata是一个昂贵的过程,可能会导致用户遇到延迟命中。这就是默认情况下禁用fielddata的原因。
如果需要对 text 类型字段进行排序、聚合、或者从脚本中访问字段值,则会出现如下异常:
Fielddata is disabled on text fields by default. Set fielddata=true on [your_field_name] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory.
但是,在启动fielddata 设置之前,需要考虑为什么针对text 类型字段进行排序、聚合、或脚本呢?通常情况下,这是不太合理的。
text字段在索引时,例如New York,这样的词会被分词,会被拆成new、york 2个词项,这样当搜索new 或 york时,可以被搜索到。在此字段上面来一个terms的聚合会返回一个new的bucket和一个york的bucket,但是你可能想要的是一个单一new york的bucket。
怎么解决这一问题呢?
你可以使用 text 字段来实现全文本查询,同时使用一个未分词的 keyword 字段,且启用doc_values,来处理聚合操作。

(1) 使用my_field 字段用于查询;
(2) 使用my_field.keyword 字段用于聚合、排序、或脚本;
可以使用 PUT mapping API 在现有text 字段上启用 fielddata,如下所示:

原文地址:https://blog.csdn.net/qq_32907195/article/details/135394978
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_53226.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!