本文介绍: 本文给大家带来的改进机制是(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是’EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction’这个版本的模型结构(这点大家需要注意以下)。
一、本文介绍
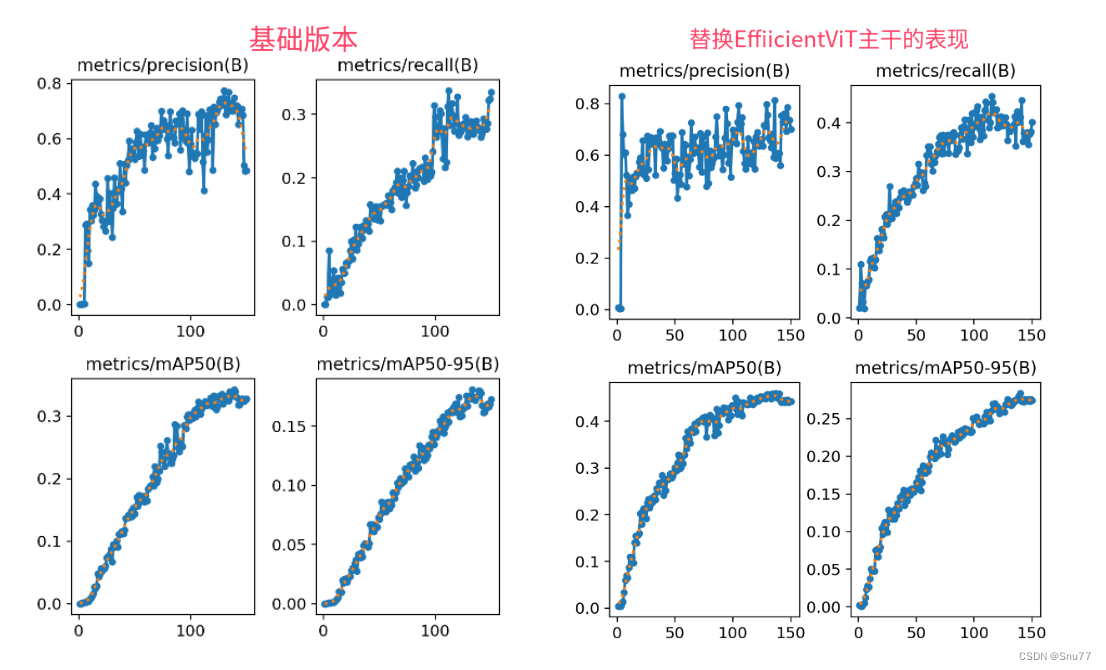
本文给大家带来的改进机制是EfficientViT(高效的视觉变换网络),EfficientViT的核心是一种轻量级的多尺度线性注意力模块,能够在只使用硬件高效操作的情况下实现全局感受野和多尺度学习。本文带来是2023年的最新版本的EfficientViT网络结构,论文题目是’EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction’这个版本的模型结构(这点大家需要注意以下)。同时本文通过介绍其模型原理,然后手把手教你添加到网络结构中去,最后提供我完美运行的记录,如果大家运行过程中的有任何问题,都可以评论区留言,我都会进行回复。亲测在小目标检测和大尺度目标检测的数据集上都有大幅度的涨点效果(mAP直接涨了大概有0.1左右)
推荐指数:⭐⭐⭐⭐⭐
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





