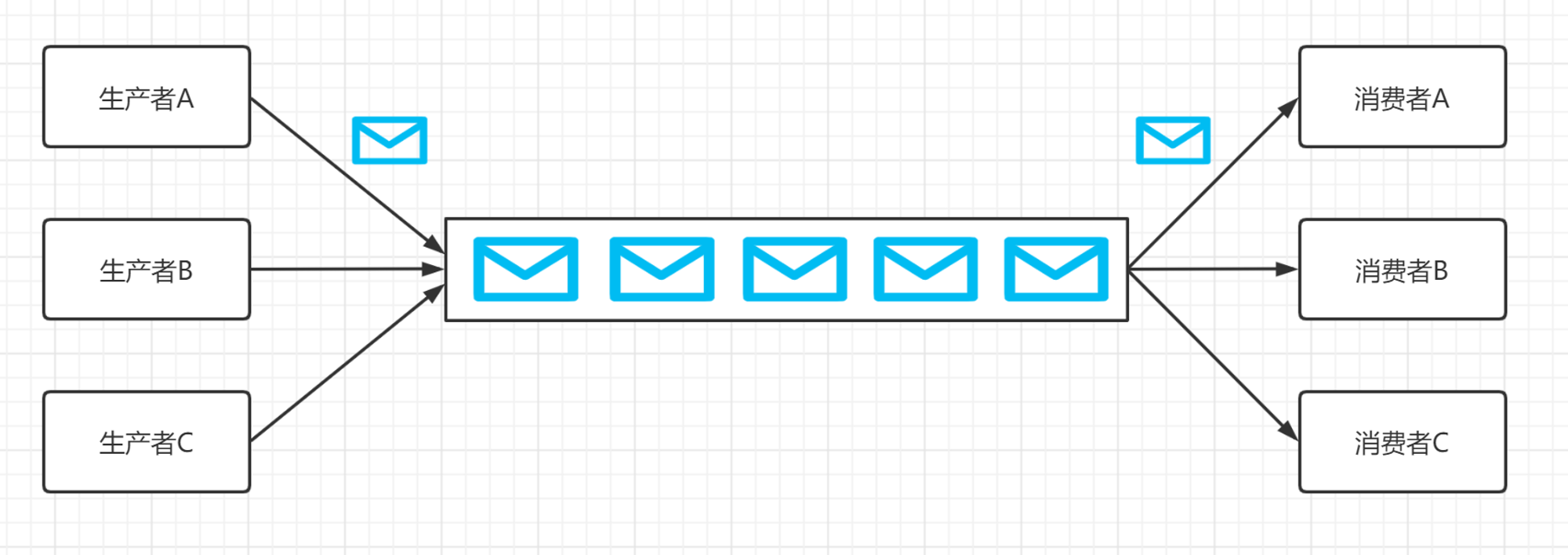
消息队列介绍
消息队列(Message Queue)是一种在分布式系统中进行异步通信的机制。它允许一个或多个生产者在发送消息时暂时将消息存储在队列中,然后由一个或多个消费者按顺序读取并处理这些消息。
消息队列具有以下特点:
- 异步通信:消息队列允许生产者和消费者在时间上解耦,即生产者发送消息后不必等待消费者立即处理,消费者可以在适当的时候从队列中获取并处理消息。
- 可靠性:消息队列提供了持久化机制,确保即使在系统崩溃或重启的情况下,消息也不会丢失。
- 顺序性:消息队列保证了消息按照发送的顺序逐个被消费者读取和处理,这有助于维护数据的完整性和一致性。
- 可扩展性:通过将处理逻辑分离到不同的消费者,消息队列允许系统轻松地扩展到多个节点,以提高吞吐量和应对高并发场景。
- 解耦:消息队列允许生产者和消费者之间无需直接交互,它们之间的耦合性降低,可以独立地进行开发、部署和运维。
常见的消息队列工具有 RabbitMQ 、Kafka 、ActiveMQ 、RocketMQ 等。这些工具提供了不同的特性和适用场景,可以根据实际需求选择适合的消息队列系统。

Kafka的介绍
Apache Kafka是一个开源流处理平台,由Scala和Java编写,由Apache软件基金会开发。它是一个高吞吐量的分布式发布订阅消息系统,可以处理消费者在网站中的所有动作流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,Kafka是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka可以存储和持续处理大型的数据流,它有点像消息中间件,但是和传统的消息中间件有着很大得差异。消息系统只会传递数据,而Kafka的流处理能力可以让我们高效的处理数据。它可以发布和订阅数据流,并将它们保存起来进行处理。
Kafka里的消息用主题进行分类,主题下有若干个分区,有新消息,消息会追加的形式写入分区。由于主题会有多个分区,所以在整个主题范围内,是无法保证消息顺序的。分区可以分布在不同的服务器上,实现数据冗余和伸缩。此外,消费者可以订阅一个或多个主题,通过检查偏移量来区分读取哪个消息。
Kafka的特点
- 高吞吐量:Kafka每秒可以处理数万条消息,适用于各种规模的流数据处理场景。
- 持久化:Kafka将消息持久化到磁盘,因此可以用于批量消费和实时应用程序。
- 分布式系统:Kafka是一个分布式系统,易于向外扩展,支持多个生产者和消费者同时读写。
- 可靠性:Kafka通过分布式结构和数据备份机制来保证数据的可靠性和容错性。
- 可扩展性:Kafka集群支持热扩展,可以方便地增加或减少节点。
- 耐用性:Kafka中的数据分区存储在每台机器的磁盘上,不易丢失。
- 支持在线和离线场景:Kafka既可以在线处理实时数据流,也可以离线处理历史数据。
此外,Kafka还具有低延迟、高并发、灵活的分区和消费者组管理等特点,使其适用于各种流处理场景,如消息队列、行为跟踪、运维数据监控、日志收集、流处理、事件溯源和持久化日志等。

RabbitMQ的介绍
RabbitMQ是一个开源的消息队列系统,使用Erlang语言编写,实现了高级消息队列协议(AMQP)。它是一个可靠的、可扩展的、易用的消息队列系统,广泛应用于各种分布式系统中。
RabbitMQ的特点
RabbitMQ的主要特点包括:
- 可靠性:RabbitMQ通过持久化、传输确认和发布确认等机制来确保消息的可靠传递。
- 灵活的路由:消息在进入队列之前会通过交换器进行路由,使得消息能够按照特定的规则进行分发。
- 可扩展性:RabbitMQ支持构建集群,多个节点可以组成一个集群,并可以根据实际业务需求动态地扩展集群中的节点。
- 高可用性:队列可以在集群的多台机器上进行镜像设置,即使其中的某些节点出现故障,队列仍然可用。
- 多种协议:RabbitMQ不仅原生支持AMQP协议,还支持其他多种消息中间件协议,如STOMP、MQTT等。
- 多语言客户端:RabbitMQ提供了广泛的语言客户端支持,几乎涵盖了所有常用编程语言,包括Java、Python、Ruby、PHP、C#、JavaScript等。
RabbitMQ是一个可靠、灵活、可扩展的消息队列系统,适用于各种分布式系统的消息传递需求。

Kafka与RabbitMQ的相同点
- 消息传递:两者都支持异步消息传递,可以在分布式系统中传递消息。
- 可靠性:两者都提供了持久化机制,保证消息的可靠性传递。
- 高吞吐量:Kafka和RabbitMQ都具有高吞吐量的特性,能够处理大量的消息。
- 可扩展性:两者都支持水平扩展,可以根据需求增加节点来处理更多的消息。
综上所述,Kafka和RabbitMQ的相同点主要表现在消息传递、可靠性、高吞吐量以及可扩展性等方面。
Kafka与RabbitMQ的不同点
- 语言:RabbitMQ是由Erlang语言开发的,而Kafka则是用Scala语言开发的。
- 结构:RabbitMQ使用AMQP(高级消息队列协议),其broker由Exchange、Binding和Queue组成。而Kafka则采用不同的结构,其中broker有part(分区)的概念。
- 交互方式:RabbitMQ采用push的方式,而Kafka则采用pull的方式。
- 集群负载均衡:RabbitMQ的负载均衡需要单独的load balancer进行支持,而Kafka则通过zookeeper对集群中的broker和consumer进行管理。
- 数据处理方式:RabbitMQ是一个传统的AMQP消息队列,使用队列来存储和传递消息,并通过消息持久化和队列持久化机制将消息和队列持久化到磁盘中,以提供高可靠性和持久性。而Kafka则是一个分布式流处理平台,使用分布式日志来存储和传递消息,支持高吞吐量和低延迟的实时数据流处理,适合处理大量的数据流。
- 数据存储:Kafka内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
Kafka和RabbitMQ在语言、结构、交互方式、集群负载均衡、数据处理方式和数据存储等方面存在差异。选择使用哪种消息队列系统取决于具体的应用场景和需求。
Kafka和RabbitMQ的使用场景的区别
Kafka和RabbitMQ的使用场景存在一些明显的区别,主要表现在以下几个方面:
消息大小和格式:RabbitMQ更适合处理中小型消息,而Kafka则更适合处理大型消息和流式数据。实时性要求:RabbitMQ支持更精确的消息传递延迟和定时功能,更适合实时消息处理。吞吐量:Kafka在吞吐量方面表现优于RabbitMQ,尤其在处理大量数据和高并发场景时。数据一致性和可靠性:RabbitMQ提供了更强的消息持久化和确认机制,确保消息可靠传输。分布式系统支持:Kafka通过其分布式特性和高吞吐量能力,更适用于构建大规模分布式系统。插件支持和生态系统:RabbitMQ有更丰富的插件支持和生态系统,更容易与各种技术和工具集成。
Kafka和RabbitMQ的使用场景区别主要表现在消息大小和格式、实时性要求、吞吐量、数据一致性和可靠性、分布式系统支持以及插件支持和生态系统等方面。选择使用哪种消息队列系统取决于具体的应用场景和需求。

原文地址:https://blog.csdn.net/zhangzehai2234/article/details/135469282
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_55656.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!