自然语言处理复习
谨以此博客作为复习期间的记录
实体关系联合抽取
流水线式
-
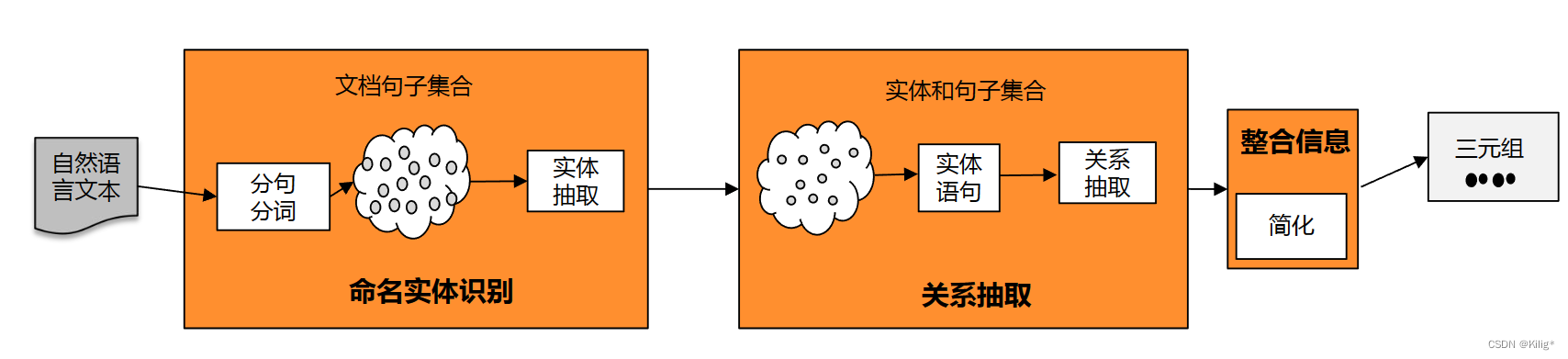
流水线式抽取(Pipline): 把关系抽取的任务分为两个步骤,首先进行实体识别,再抽取出两个实体的关系。
-
联合抽取(Joint Extraction): 端到端,同时进行实体和关系的抽取。流水线式抽取会导致误差在各流程中传递和累加,而联合抽取的方式则实现难度更大
端到端方法

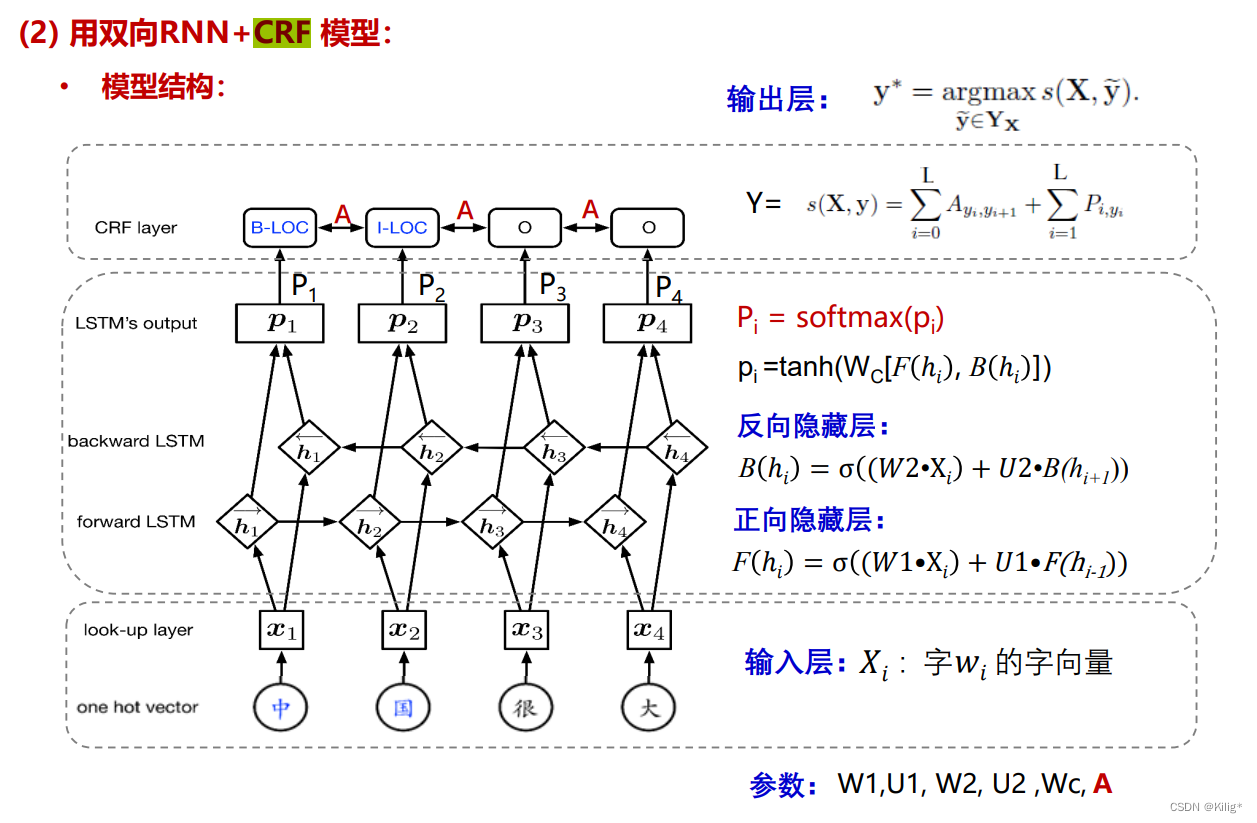
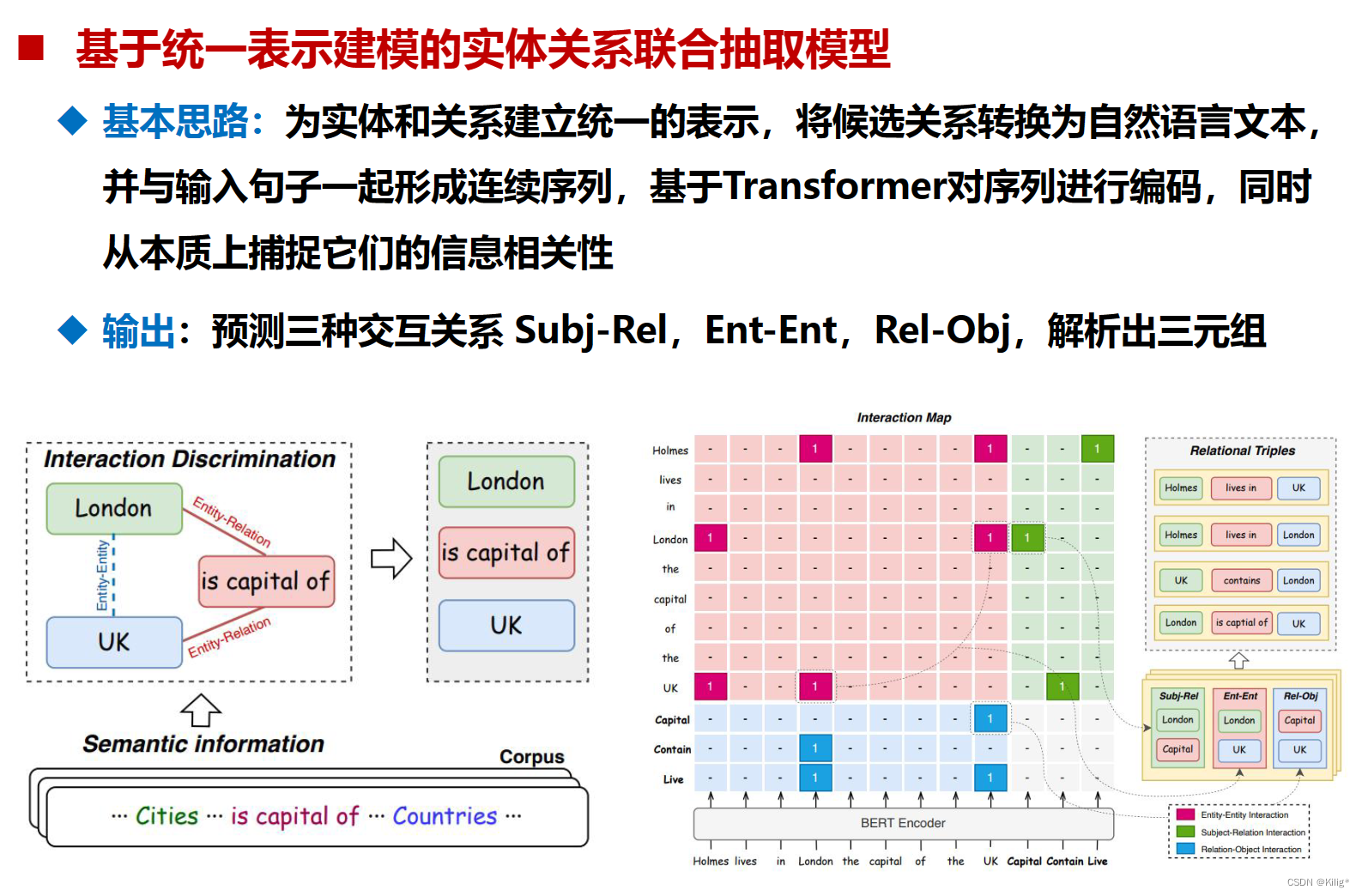
流水线式抽取和新标注策略的实体关系联合抽取都可以和序列标注结合起来,
检索式问答系统
流水线方式
Document Retriever 和 Document Reader 分两步
- Document Retriever:通过TF-IDF检索维基百科中与问题相关的Top K个文档
- Document Reader:将答案抽取转化为抽取式阅读理解问题
- • 输入:一个文档段落,一个自然语言描述的问题
- • 输出:段落中抽取的答案片段
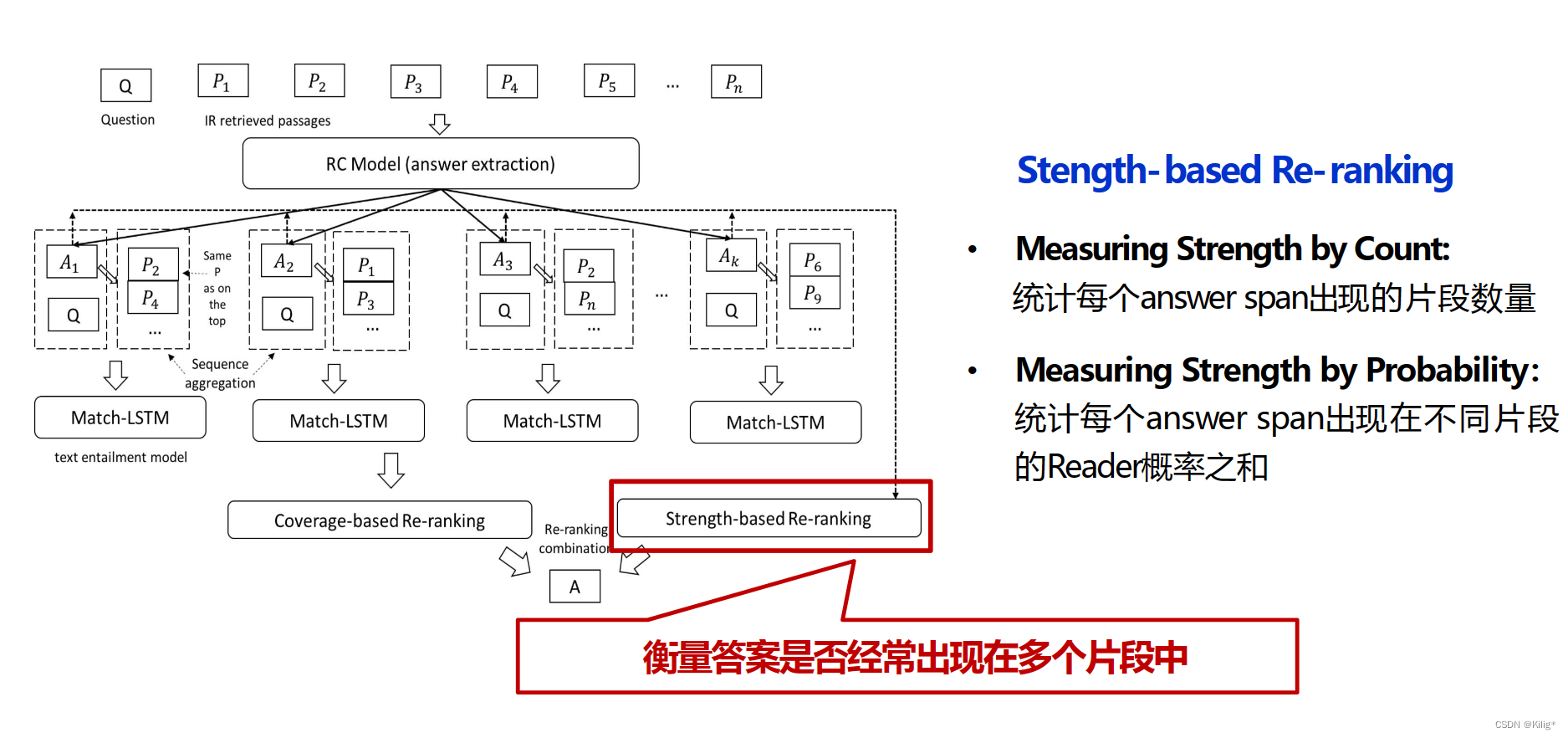
论文中提出的模型结构主要包括两个阶段:信息检索(IR)和阅读理解(RC),以及两种答案重排方法:基于证据强度的重排和基于证据覆盖的重排。以下是这些模型组件的详细介绍:
信息检索(IR)阶段
- 目标:检索与给定问题最相关的网页段落。
- 方法:使用搜索引擎(例如谷歌或必应)来找到与问题最相关的顶级网页段落。
- 特点:与标准阅读理解任务不同,在开放领域设置中,RC模型通常在远程监督下进行训练。这意味着在训练阶段,RC模型会将包含正确答案的所有段落与问题进行匹配
阅读理解(RC)阶段
- 目标:从检索到的段落中提取答案。
- 方法:使用阅读理解模型(例如R3模型)来从这些段落中提取候选答案。
- 特点:与单个固定段落的标准阅读理解任务不同,开放领域问答需要处理多个段落,并从中提取候选答案
基于证据强度的重排
- 目的:利用段落中出现答案的频率或概率来评估答案的强度。
- 实现:计算每个答案在顶级答案候选中出现的次数,或者将RC模型为每个答案跨度分配的概率相加,以确定最终预测
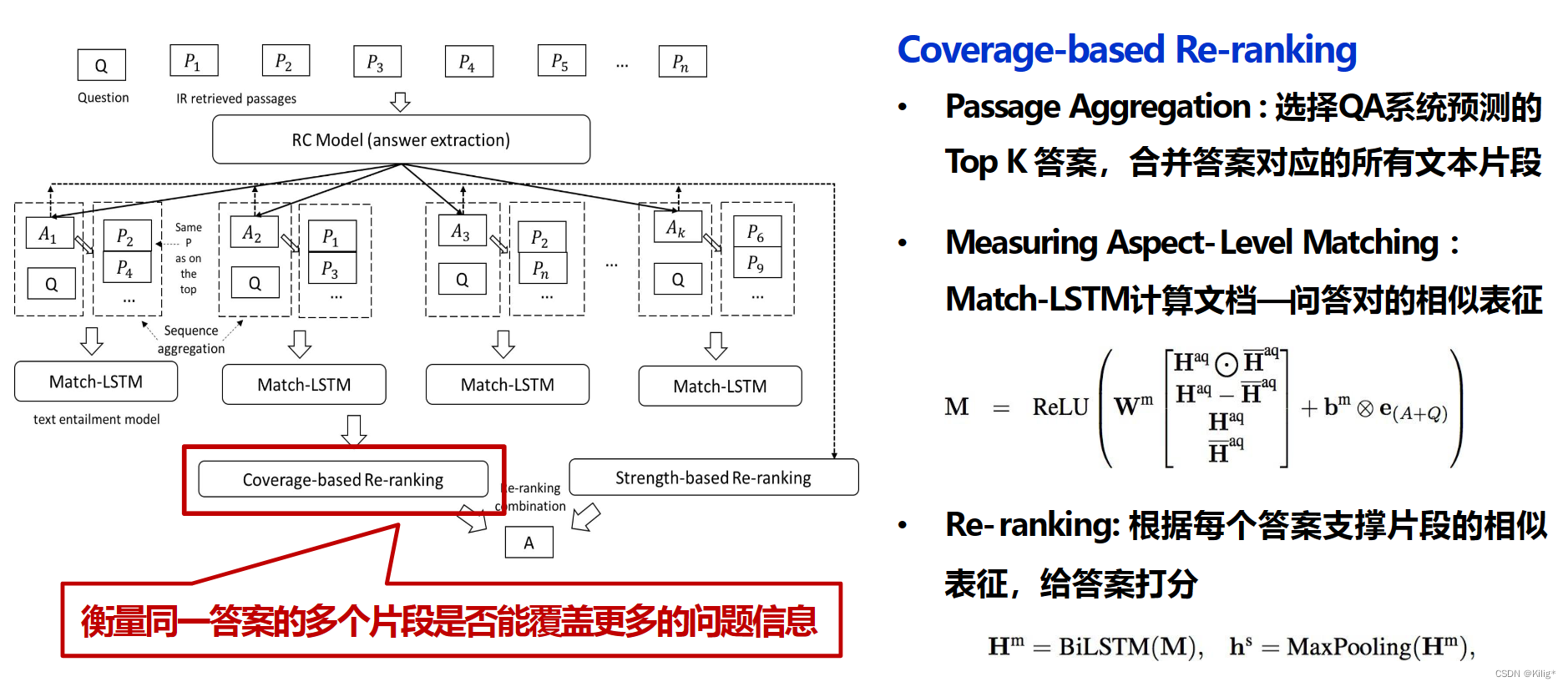
基于证据覆盖的重排
- 目的:根据不同段落的证据如何覆盖问题来排列答案候选。
- 实现:首先将包含答案的段落连接成一个“伪段落”,然后使用匹配LSTM模型来衡量这个伪段落如何涵盖问题的各个方面
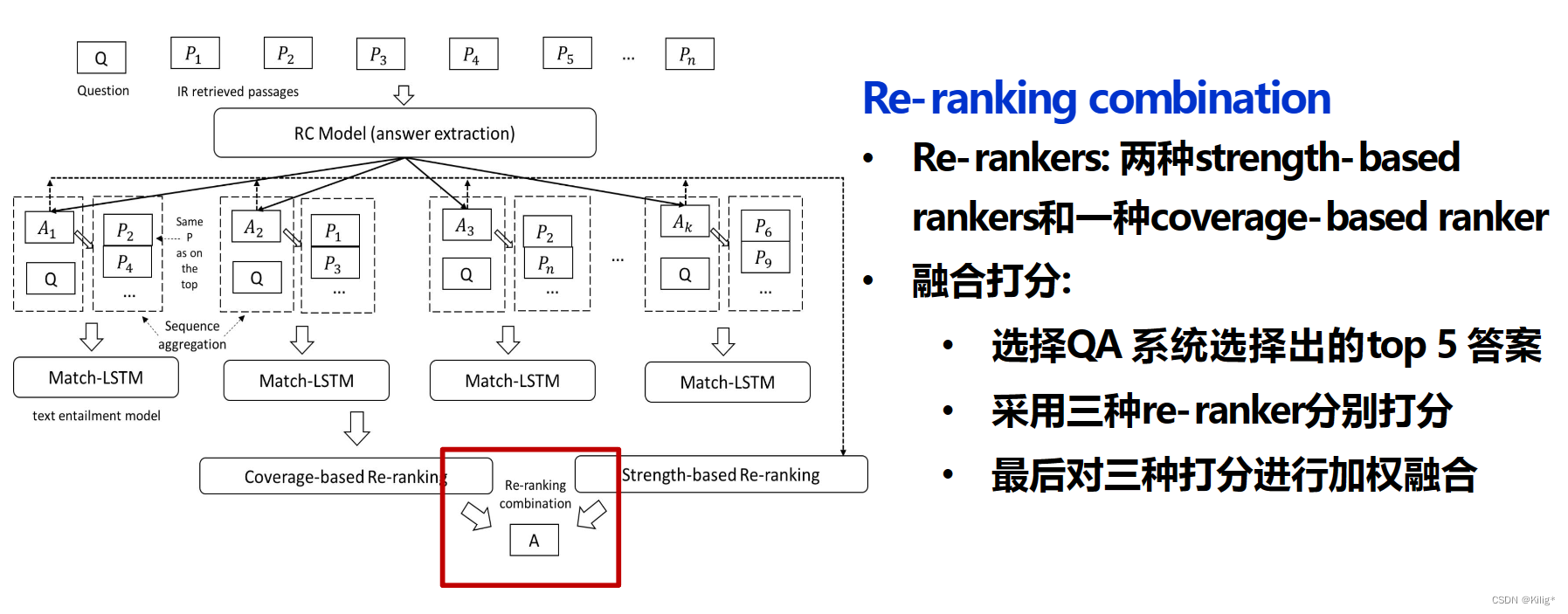
结合不同类型的聚合
- 方法:将两种重排方法的输出进行加权组合,无需额外训练。
- 特点:首先使用softmax重新归一化两种基于强度的重排器和一个基于覆盖的重排器提供的前5个答案得分,然后对相同答案的得分进行加权求和,选择得分最高的答案作为最终预测
这种结合信息检索、阅读理解和多种重排策略的方法充分利用了多个段落的证据,有效地提高了开放领域问答系统的性能。
端到端方式
Retriever-Reader的联合学习
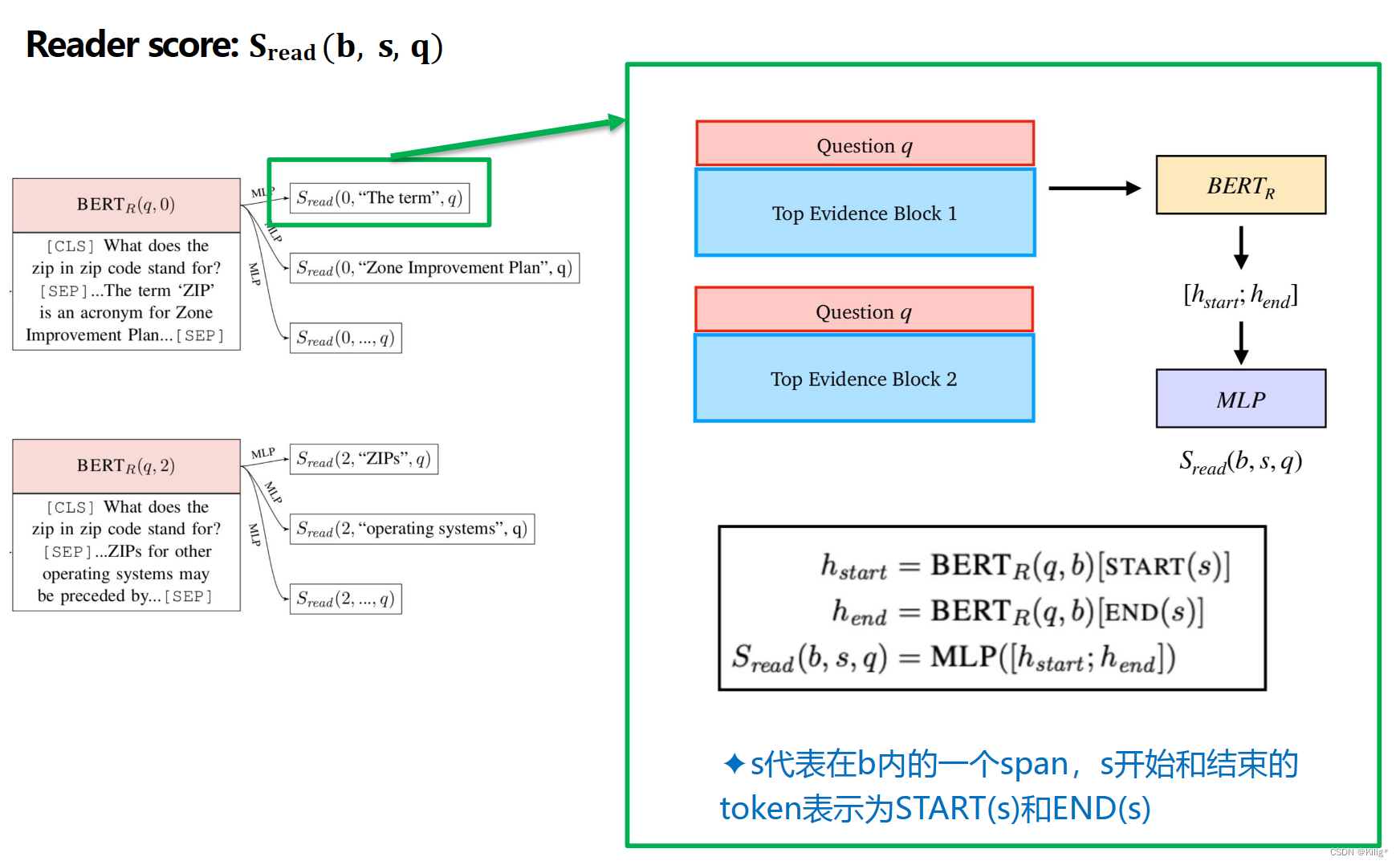
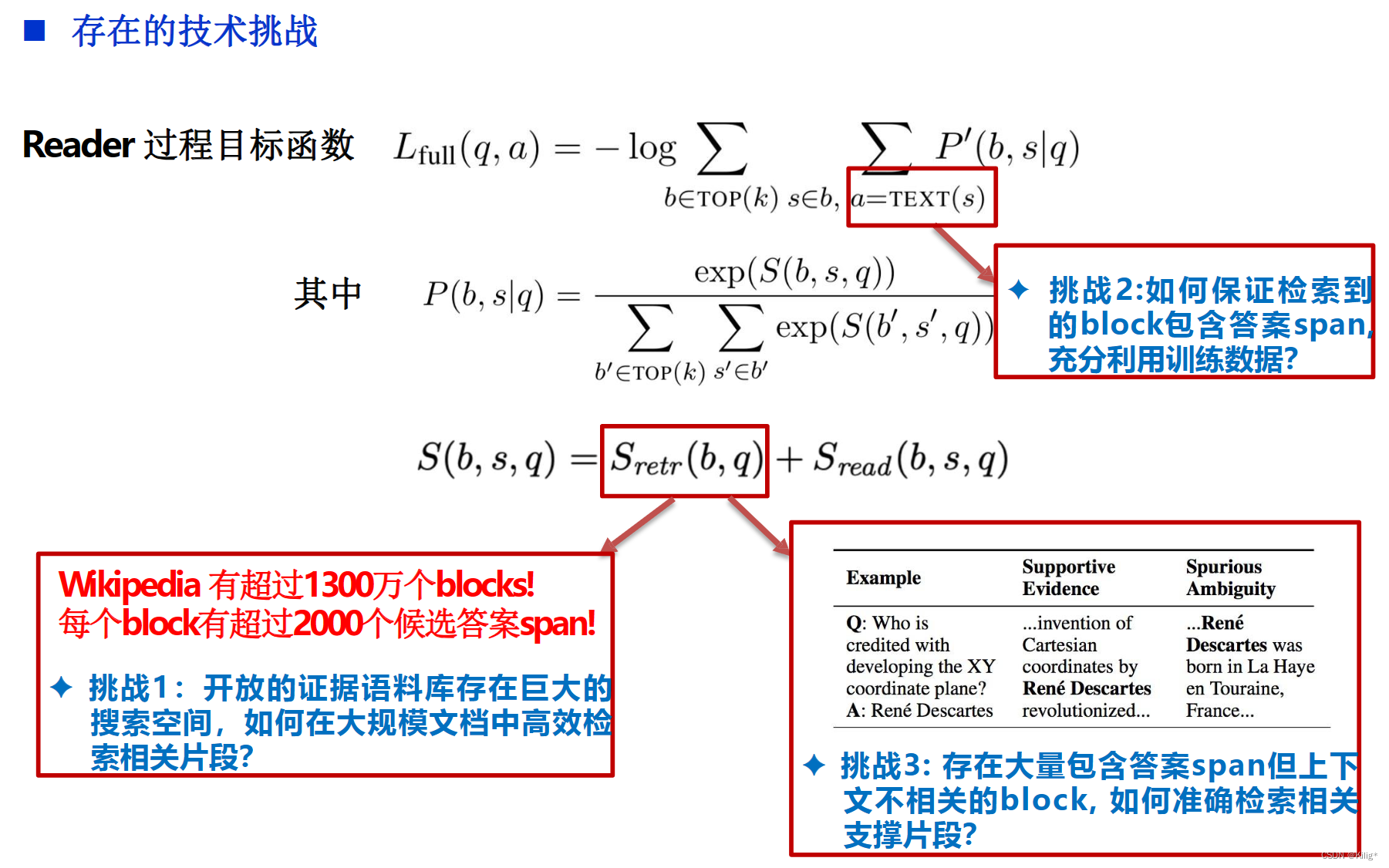
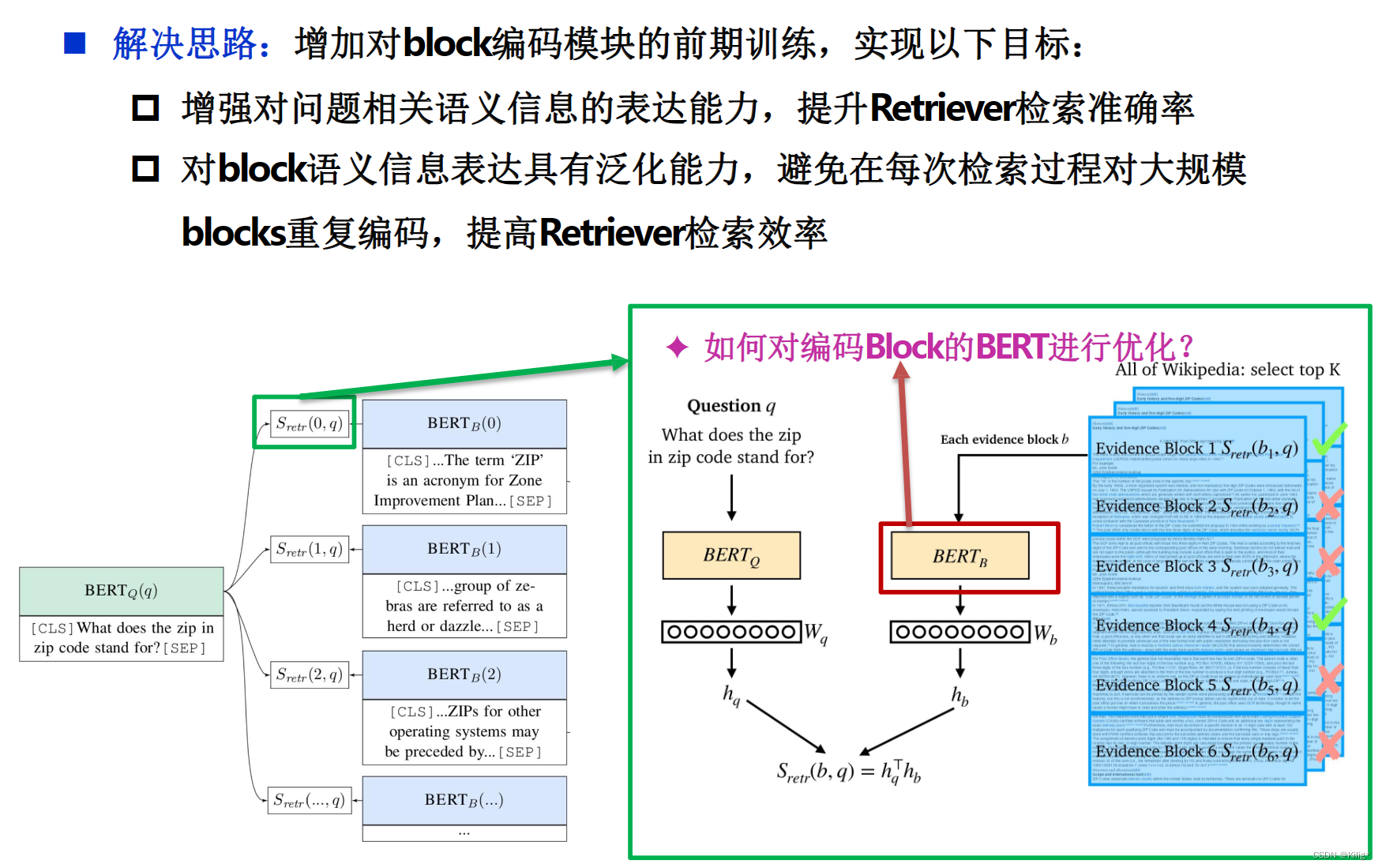
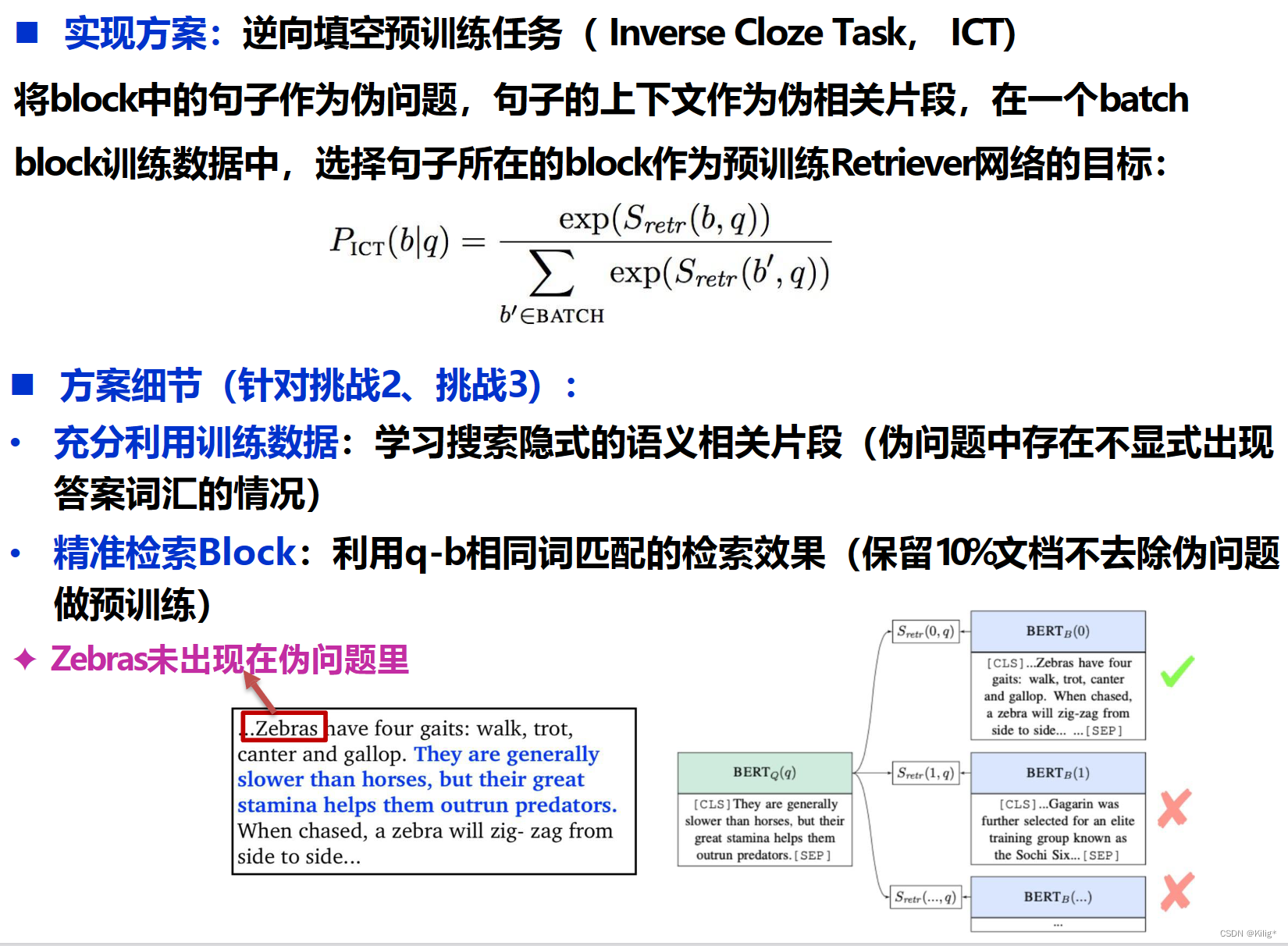
Lee et al., Latent Retrieval for Weakly Supervised Open Domain Question Answering, ACL,2019
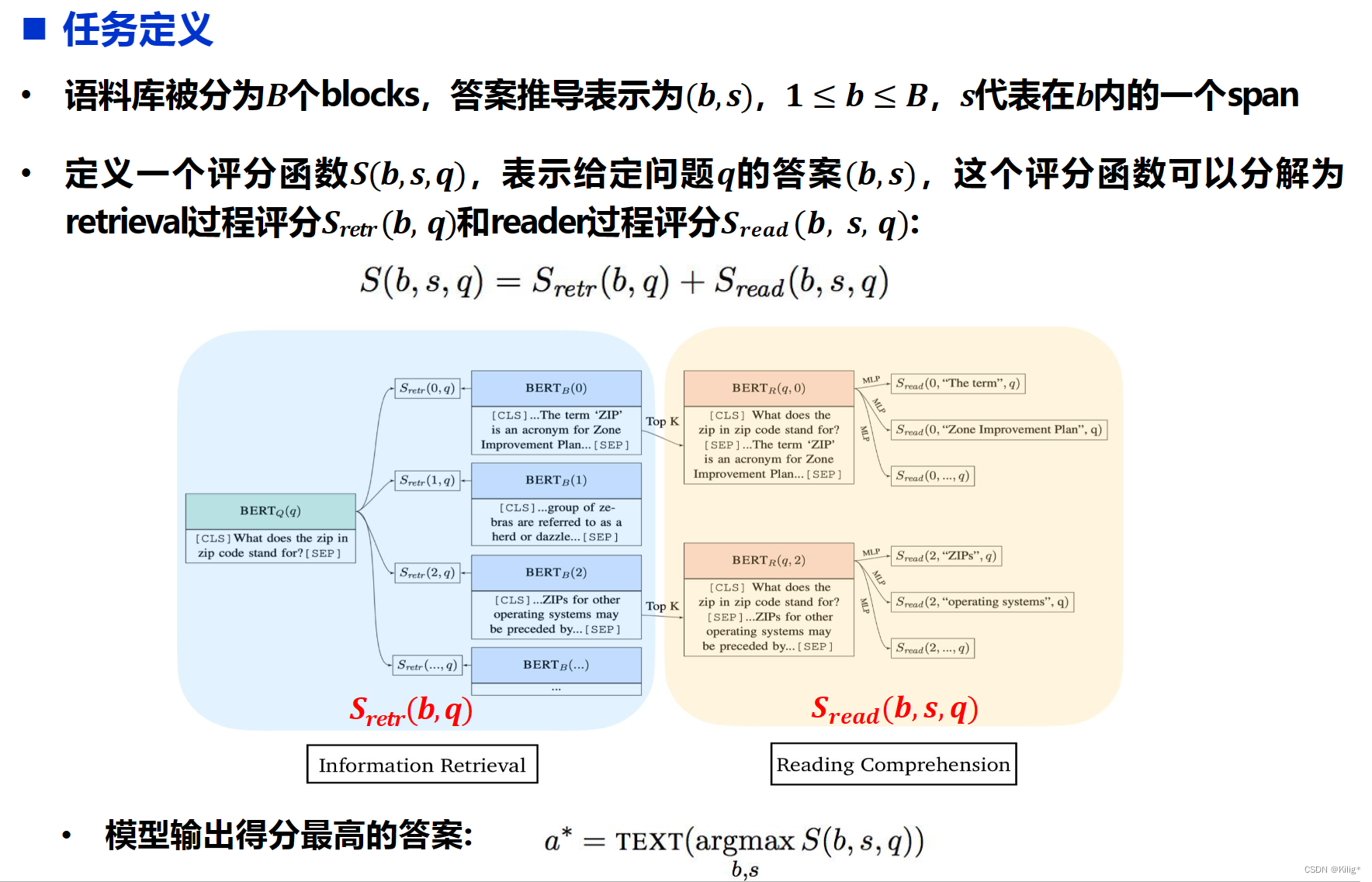
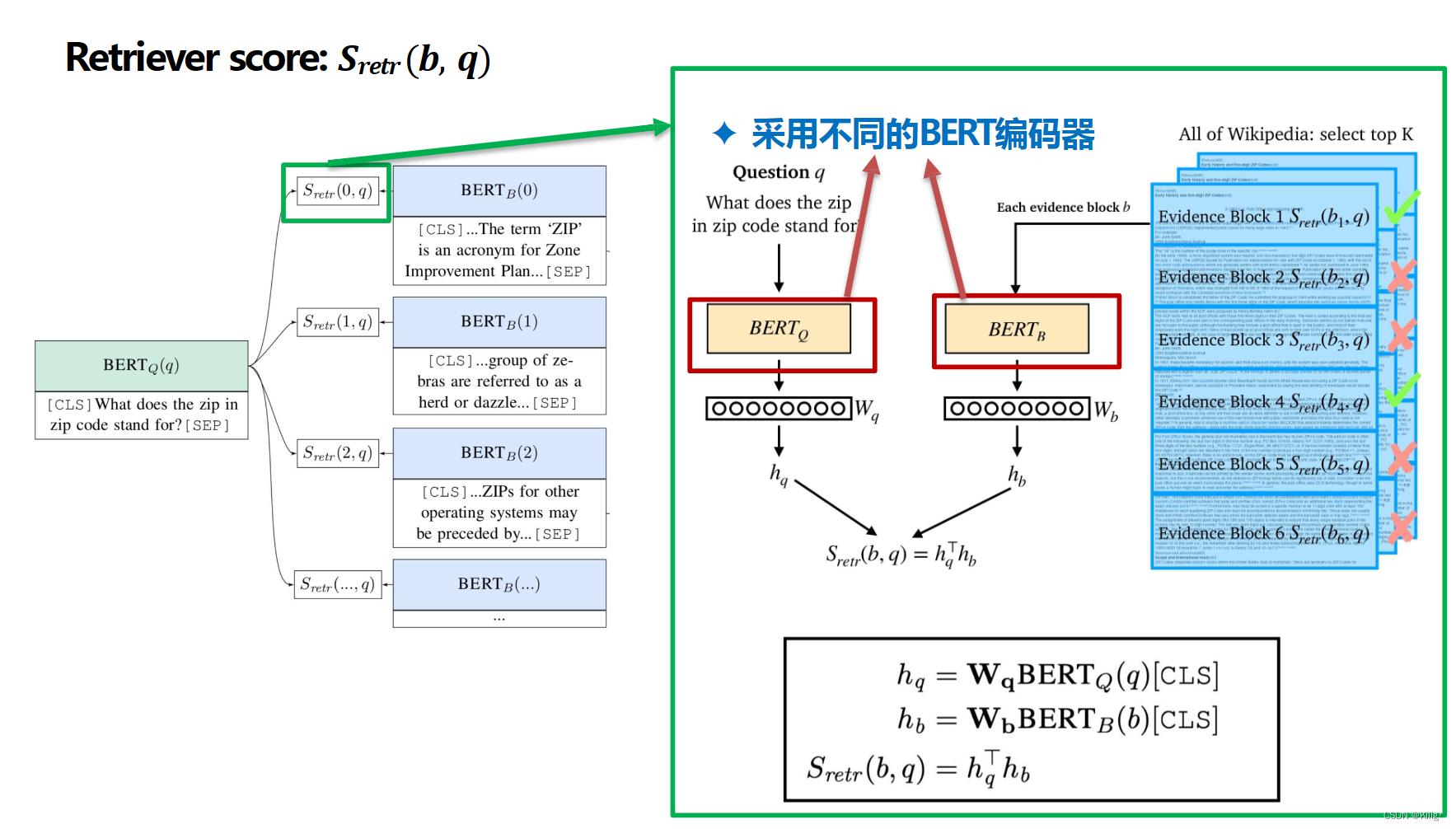



基于预训练的Retriever-Free方法
Petroni et al. Language Models as Knowledge Bases? ACL, 2019
情感分析
联合三元组抽取
将问题转为一个序列生成问题
统一输入输出的标准

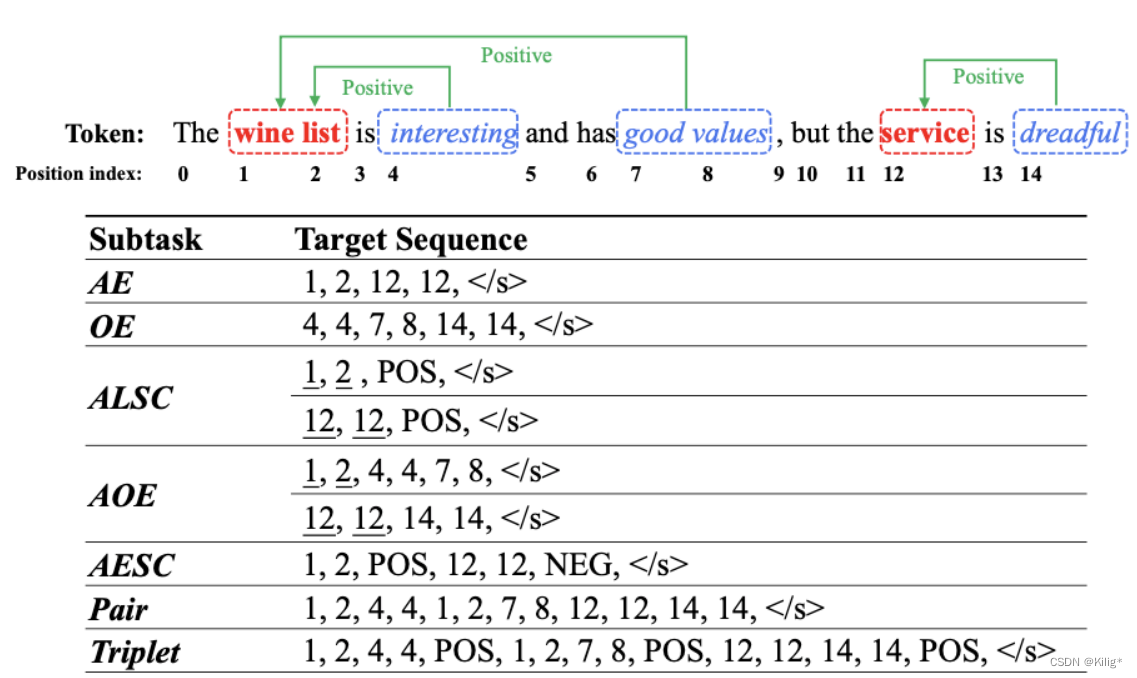
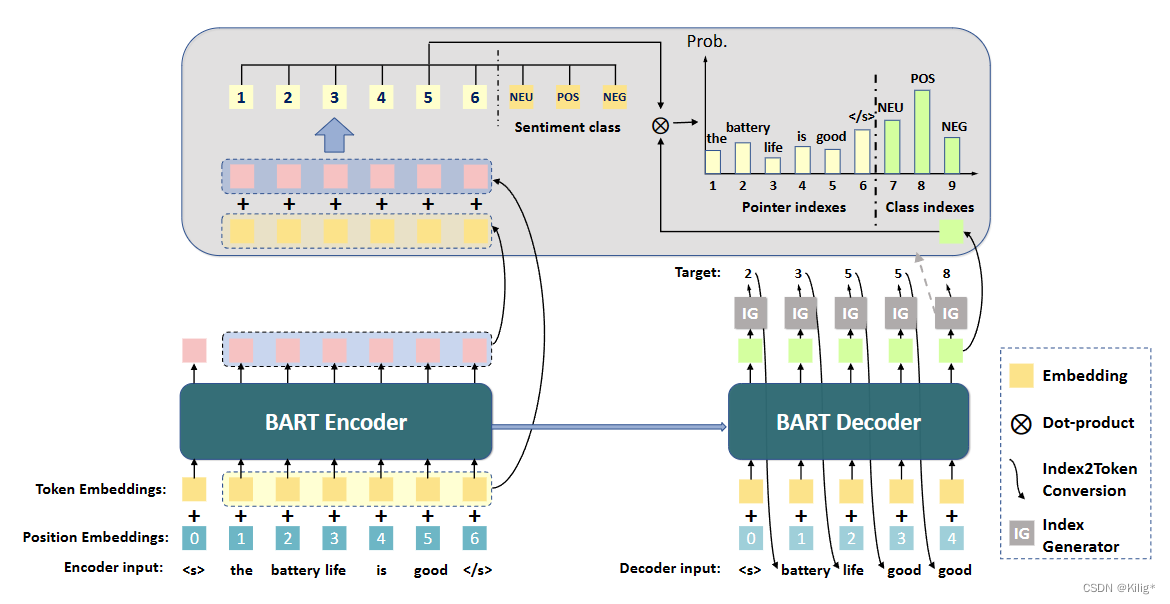
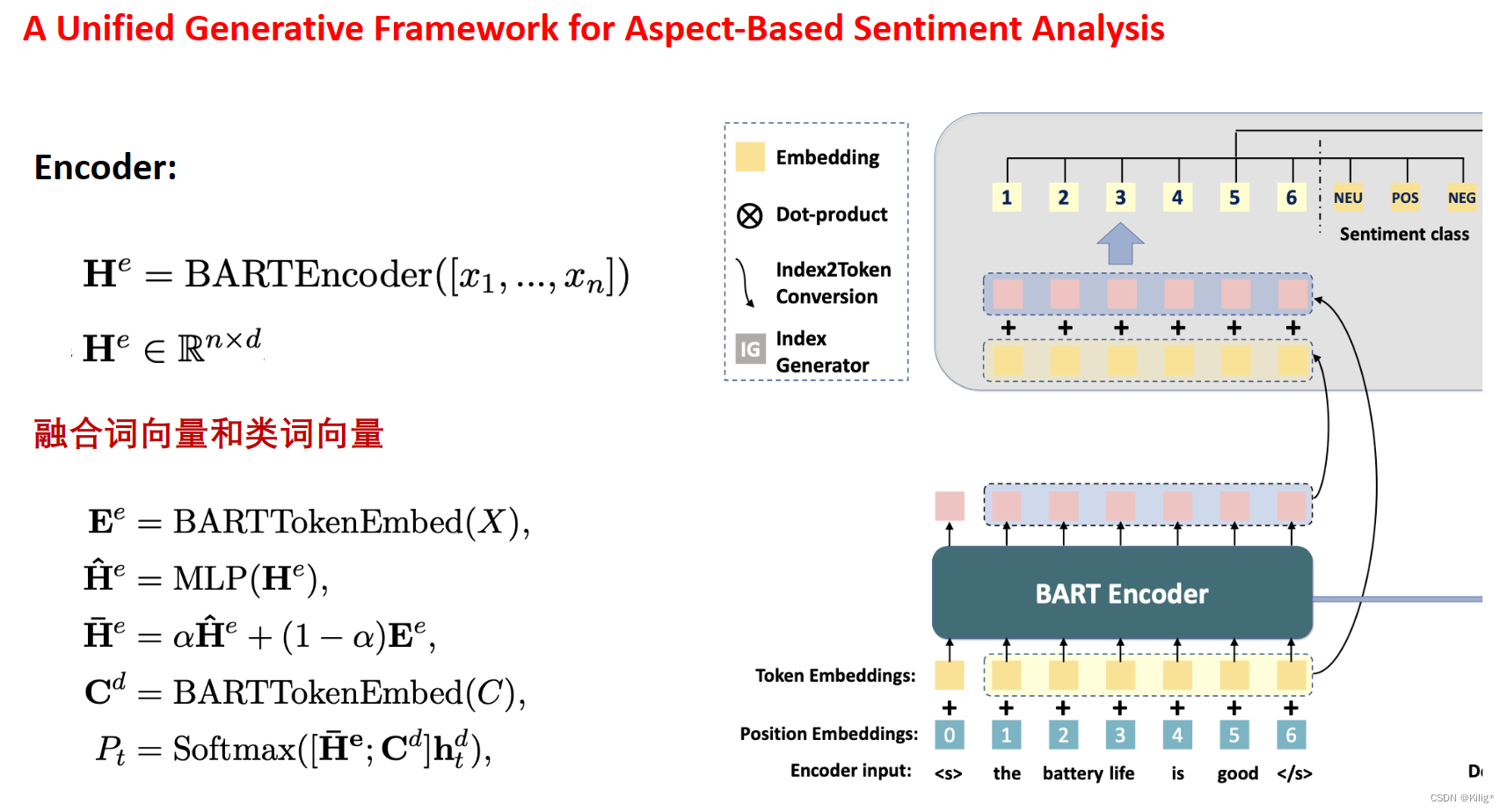
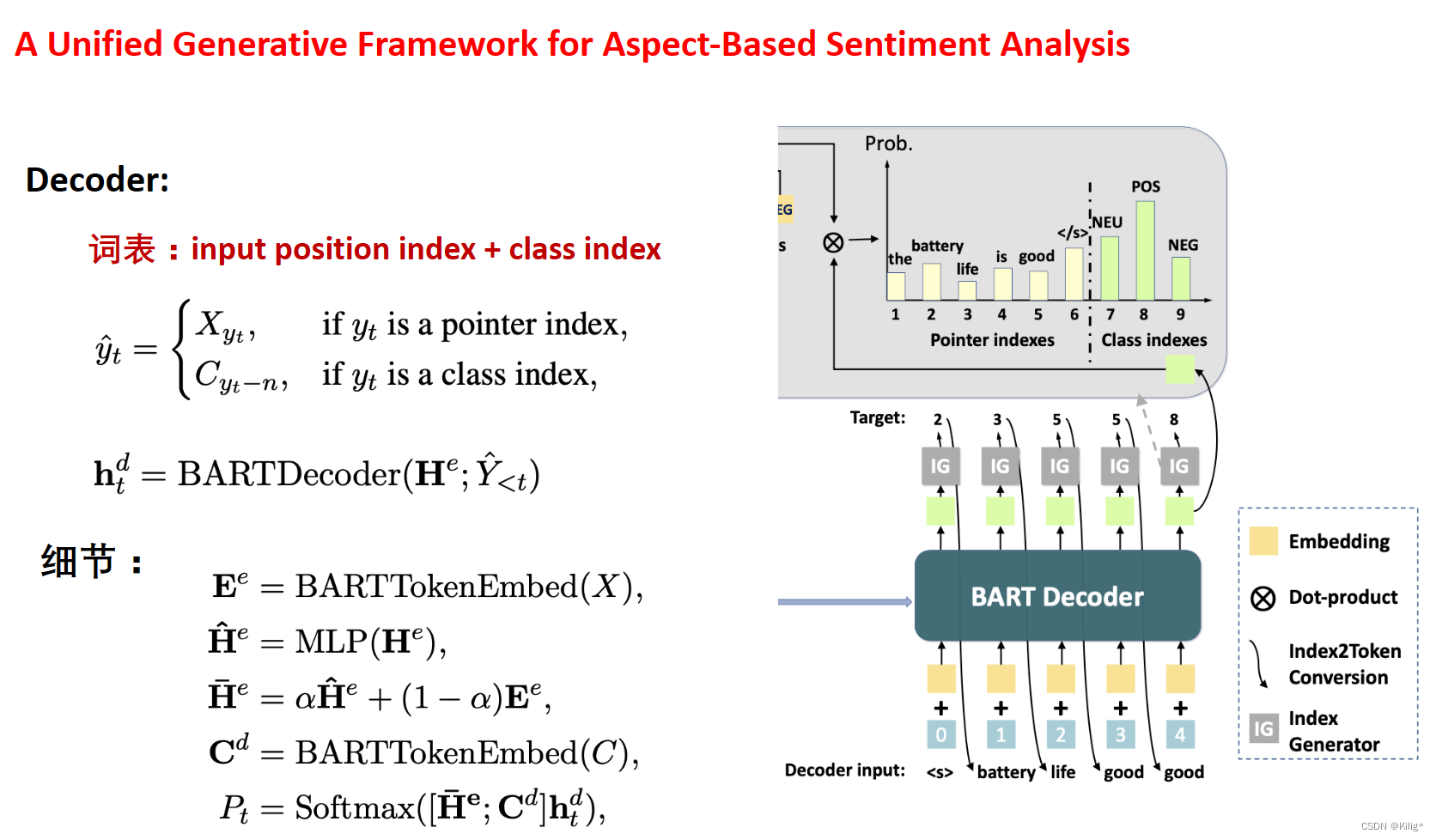
A Unified Generative Framework for Aspect-Based Sentiment Analysis
原文地址:https://blog.csdn.net/Kilig___/article/details/135580394
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56076.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






