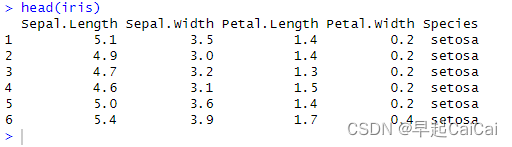
本文介绍: 利用KNN算法对鸢尾花进行分类的具体代码
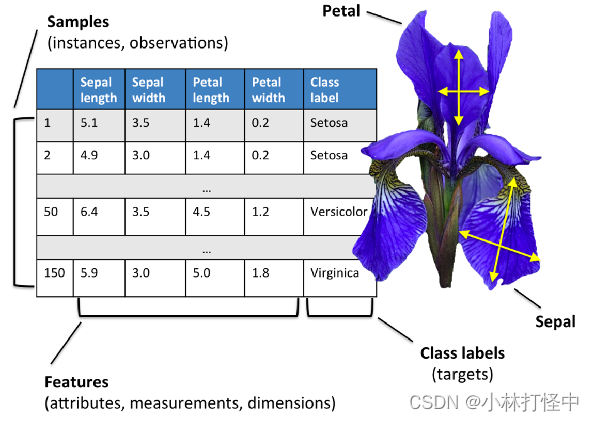
实现流程:
1、获取数据集
2、数据基本处理
3、数据集预处理-数据标准化
4、机器学习(模型训练)
5、模型评估
6、模型预测
具体API:
1、获取数据集
# 1、加载数据集
from sklearn.datasets import load_iris
iris = load_iris()查看各项属性
# 查看目标值
iris.target
# 查看目标值名
print(iris.target_names)
# 查看特征名
iris.feature_names
# 查看数据
iris.data
# 查看数据集描述
iris.DESCR
# 数据文件路径
iris.filename2、数据基本处理
# 2、对数据做简单的可视化
# 2.1 导包
import seaborn as sns
import pandas as pd# 2.2 将数据转成 DF格式,设置data, columns属性、目标值名称
iris_df = pd.DataFrame(iris.data,columns=iris.feature_names)
iris_df['label'] = iris.target
iris_df
# 2.3 用lmplot做可视化
sns.lmplot(data=iris_df,x='sepal length (cm)',y='petal width (cm)', hue='label', fit_reg=False) # fit_reg=默认会拟合一个回归直线

# 查看数据详情
iris_df.describe()# 3、划分训练集、测试集
# 3.1 导包
from sklearn.model_selection import train_test_split
# 3.2 实现划分
X_train,X_test,y_train,y_test = train_test_split(iris.data, iris.target,test_size=0.2,random_state=21)
3、数据集预处理-数据标准化
# 4、特征工程
# 4.1 导包
from sklearn.preprocessing import StandardScaler
# 4.2 数据集预处理-数据标准化
scaler = StandardScaler()
scaler.fit(X_train) # 计算均值、方差
X_train_scaled = scaler.transform(X_train)
# 4.3 让测试集的均值和方法, 转换测试集数据
X_test_scaled = scaler.transform(X_test) # 做标准化计算
4、机器学习(模型训练)
# 5、模型训练
# KNN导包
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
# 使用标准化之后的特征值,进行模型训练
knn.fit(X_train_scaled, y_train)5、模型评估 及 预测
# 6、模型评价
# 导包
from sklearn.metrics import accuracy_score
# 用训练好的模型,对训练集进行分类预测
y_train_pred = knn.predict(X_train_scaled)
# 用训练好的模型,对测试集进行分类预测
y_test_pred = knn.predict(X_test_scaled)
# 利用模型输出的结果 和真实标签进行比较,两者一致,则模型分类正确
accuracy_score(y_train,y_train_pred)
accuracy_score(y_test,y_test_pred)原文地址:https://blog.csdn.net/linxinyide/article/details/135500412
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56092.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。