目录
一、准备工作
Flume 要想将数据输出到 HDFS,必须持有 Hadoop 相关 jar 包。
将以下 jar 包拷贝到“/usr/local/flume/lib”目录下。
/usr/local/servers/hadoop/share/hadoop/common/lib/commons-configuration2-2.1.1.jar
/usr/local/servers/hadoop/share/hadoop/common/lib/commons-io-2.5.jar
/usr/local/servers/hadoop/share/hadoop/common/lib/hadoop-auth-3.1.3.jar
/usr/local/servers/hadoop/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar
/usr/local/servers/hadoop/share/hadoop/common/lib/stax2-api-3.1.4.jar
/usr/local/servers/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar
/usr/local/servers/hadoop/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar
[root@bigdata common]# cd /usr/local/flume/lib
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/commons-configuration2-2.1.1.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/commons-io-2.5.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/hadoop-auth-3.1.3.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/htrace-core4-4.1.0-incubating.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/lib/stax2-api-3.1.4.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/common/hadoop-common-3.1.3.jar .
[root@bigdata lib]# cp /usr/local/servers/hadoop/share/hadoop/hdfs/hadoop-hdfs-3.1.3.jar .

二、实时读取本地文件到HDFS
(一)案例需求
实时监控Hive日志,并上传到HDFS中。
(二)需求分析

(三)实现步骤
1、在“/usr/local/flume/”目录下新建文件夹job
[root@bigdata lib]# cd /usr/local/flume
[root@bigdata flume]# mkdir job
[root@bigdata flume]# cd job
2、在job目录下新建文件flume-file-hdfs.conf
[root@bigdata job]# vi flume-file-hdfs.conf
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /usr/local/flume/datas/flume_tmp.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://bigdata:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2
内容详解:

3、执行监控配置
[root@bigdata zhc]# cd /usr/local/flume
[root@bigdata flume]# bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf

4、启动Hadoop和Hive并操作Hive产生日志
启动一个新的终端,输入:
[root@bigdata zhc]# start-all.sh
[root@bigdata zhc]# cd /usr/local/hive
[root@bigdata hive]# bin/hive
再启动一个新的终端,写入日志:
[root@bigdata hive]# echo 123 > /usr/local/flume/datas/flume_tmp.log
然后就可以在HDFS上查看:

三、实时读取目录文件到HDFS
(一)案例需求
使用Flume监听整个目录的文件。
(二)需求分析
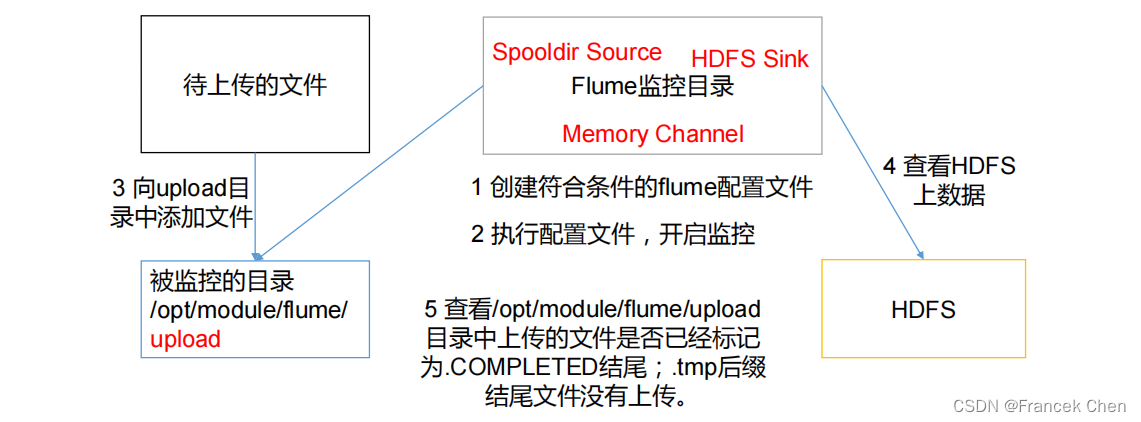
(三)实现步骤
1、在job目录下新建文件flume-dir-hdfs.conf
[root@bigdata job]# vi flume-dir-hdfs.confa3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /usr/local/flume/datas
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://bigdata:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
内容详解:

2、启动监控文件夹命令
启动一个新的终端:
[root@bigdata hive]# cd /usr/local/flume
[root@bigdata flume]# bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf

说明: 在使用Spooling Directory Source时
1.不要在监控目录中创建并持续修改文件
2.上传完成的文件会以.COMPLETED结尾
3.被监控文件夹每500毫秒扫描一次文件变动
3、向datas文件夹中添加文件
[root@bigdata job]# cd /usr/local/flume/datas
[root@bigdata datas]# touch one.txt
[root@bigdata datas]# touch two.txt最后再到HDFS上查看:

原文地址:https://blog.csdn.net/Morse_Chen/article/details/135455624
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_56472.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!