本文介绍: 后台同步任务是 Kafka 内部自动管理的,不需要人为干预。Kafka 设计了一些后台任务来确保副本之间的同步和数据的一致性,以提高整个系统的可用性和可靠性。滞后主要指的是追随者在处理消息时相对于领导者的位置较远,即它的日志文件中的消息相对较旧。这是通过追随者的日志文件中的偏移量(offset)来衡量的。消息追加到分区的日志文件,这确保了分区的写入顺序。🫱🏽 kafka后台同步策略。在线(心跳表现 | ISR中)宕机(心跳表现 | ISR中)滞后(心跳表现 | ISR中)🫱🏽 kafka分区策略。
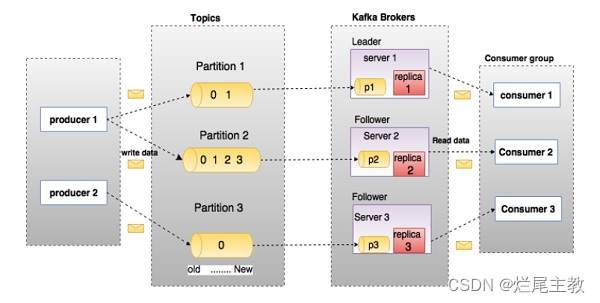
- 主题(topic):消息的第一次分类
- 根据人为的划分条件将消息分成不同的主题
- 主题的划分是人为的根据不同的任务情景去划分
- 比如,我们有两个主题,一个是”订单”,另一个是”库存”。每个主题代表一个消息流。
- 主题的名称作为主题的为一标识符,我们需要保证其唯一性
- Topic是一个逻辑上的概念,并不能直接在图中把Topic的相关单元画出
- 主题的划分是人为的根据不同的任务情景去划分
- 根据人为的划分条件将消息分成不同的主题
- 分区(partition):消息的第二次分类
- 区域化同主题中的消息:分区管理同主题的消息
- 不同主题下分区标识可以相同
- 每个分区都有一个唯一的标识
- 区域化同主题中的消息:分区管理同主题的消息
- 分区偏移(partition offset):消息的第三次分类
- 同一分区内的不同消息都有唯一的偏移
- 消息的偏移值是唯一且按照顺序递增的。kafka分配消息时确定
- 不同分区内的消息的偏移可以相同
- 同一分区内的不同消息都有唯一的偏移
🫱🏽 kafka分区策略
- 默认分区策略(DefaultPartitioner): 如果消息没有指定 key,或者指定的 key 为 null,那么默认分区策略会采用轮询(round-robin)的方式将消息均匀地分配到所有可用分区。
- 基于 key 的分区策略(PartitionByKey): 如果消息指定了 key,那么基于 key 的分区策略会根据 key 的哈希值将消息分配到对应的分区。这确保具有相同 key 的消息总是被分配到同一个分区,以保证消息的顺序性。
- 自定义分区策略: 用户可以根据自己的需求实现自定义的分区策略。这可以通过实现 Kafka 提供的
Partitioner接口来完成。
- 分区备份(replicas of partition):分区的备份,用于防止数据丢失。
- 备份时机
- 消息写入
- 消费者拉取
- 后台任务
- 备份时机
🫱🏽 kafka后台同步策略
后台同步任务是 Kafka 内部自动管理的,不需要人为干预。Kafka 设计了一些后台任务来确保副本之间的同步和数据的一致性,以提高整个系统的可用性和可靠性。
这些后台同步任务包括:
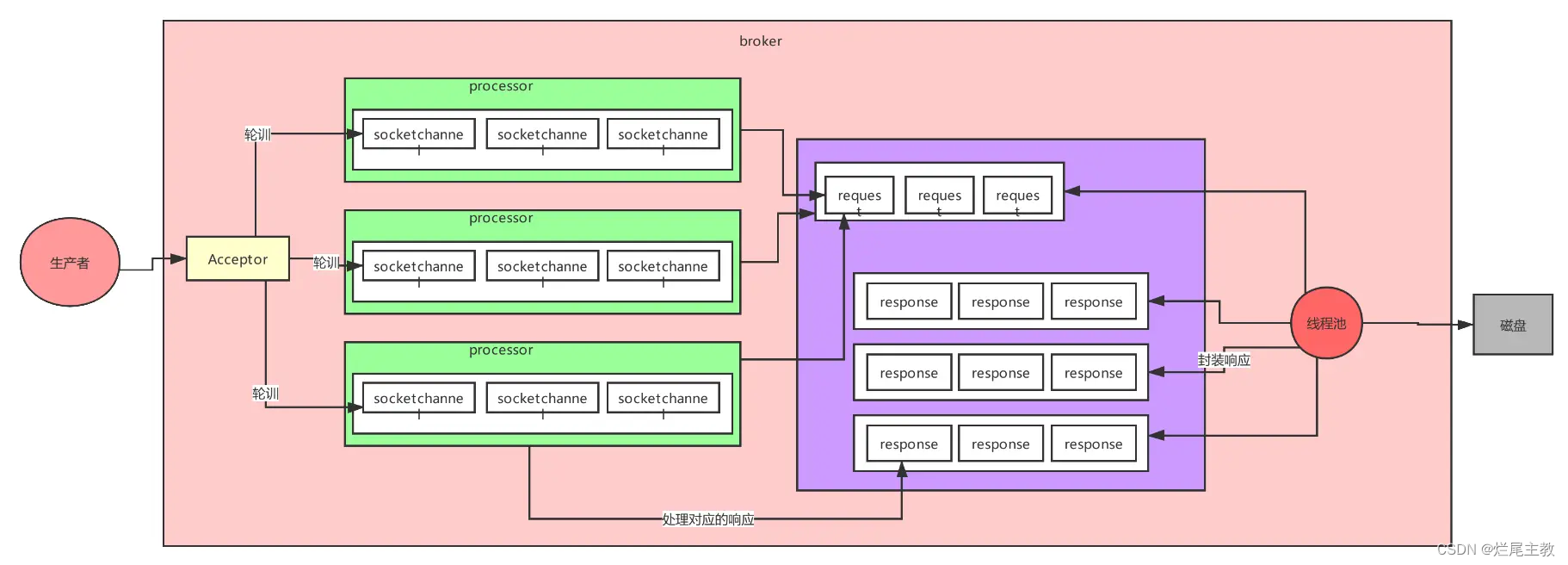
- Leader 的心跳检测: Kafka 集群中的每个分区都有一个领导者(Leader),领导者会定期发送心跳消息给追随者(Followers)。这有助于检测领导者的健康状态。
- 追随者的数据拉取: 追随者会定期从领导者拉取缺失的数据,以保持与领导者的同步。这有助于处理因追随者滞后或宕机而导致的数据不一致。
- Leader 的日志清理: 领导者会定期清理旧的日志段,删除过时的消息。这确保了存储在磁盘上的数据不会无限增长,也有助于提高性能。
- 经纪人(Brokers):负责维护发布数据的系统,每个代理可以管理一个或多个主题的分区。
- 同一主题下可能有1-n 经纪人
- 同一分区任意时刻只能由一个经纪人管理
- 经纪人的分配区域管理
- 一个主题和N个代理中有N个分区,每个代理将有一个分区。
- 一个主题中有N个分区并且多于N个代理(n + m),则第一个N代理将具有一个分区,并且下一个M代理将不具有用于该特定主题的任何分区。
- 一个主题中有N个分区并且小于N个代理(n-m),每个代理将在它们之间具有一个或多个分区共享。 由于代理之间的负载分布不相等,不推荐使用此方案
- 领导者(Leader):负责处理该分区的读写请求
- 职责:
-
消息追加到分区的日志文件,这确保了分区的写入顺序
- 不同分区的消息顺序不做保证
- 同一分区下的消息顺序是根据消息的写入的先后顺序有序存储
-
消息的复制和同步:
-
消息异步地复制到追随者(Followers)
步骤 详细过程 举例(假设分区有3个追随者,需要2个确认) 初始状态: 一个分区有一个领导者和多个追随者。领导者和追随者的副本都在 ISR 中,表示它们与领导者同步。 生产者写入消息: 生产者产生一条新消息并发送给领导者。领导者接收到消息后,将消息追加到分区的日志文件。 生产者发送消息A,领导者将A追加到日志。 消息异步复制到追随者: 领导者开始异步地将写入的消息复制到追随者。追随者接收到领导者的复制请求,将消息追加到它们的日志文件中。 追随者1、追随者2接收A并将A追加到各自日志。 等待 ISR 中的确认: 尽管消息复制是异步进行的,领导者必须等待 ISR 中的一定数量的追随者确认已成功复制。 等待追随者1、追随者2确认。两者是异步的。 如果 ISR 中的足够数量的追随者确认成功复制,领导者将响应给生产者,表示消息已成功写入。 追随者1、追随者2确认,领导者响应。 消息的持久性和有序性: 由于消息已成功写入 ISR 中的足够数量的追随者,可以确保消息的持久性。 消息A被持久化,即使领导者宕机,ISR 中的副本可以被选为新的领导者,从而保证消息的持久性。 由于等待 ISR 中的追随者确认,保证了消息的有序性。领导者会按照消息写入的顺序等待确认,以确保整个分区的消息顺序性。 领导者需要等待一定数量的追随者确认后才能继续处理下一条消息。这确保了消息在分区内的有序存储。
-
-
追随者的管理
- 心跳机制:检测追随者状态(在线、宕机、滞后)
-
在线(心跳表现 | ISR中)
- 追随者定期发送心跳消息,表示自己在线
- 如果追随者的心跳正常,领导者将其包含在 ISR 中,表示它是同步的。
-
宕机(心跳表现 | ISR中)
- 领导者在一定时间内没有受到心跳信息,无法确认追随者的在线状态
- 领导者可能将宕机的追随者移出 ISR,等待其他追随者的确认。
-
滞后(心跳表现 | ISR中)
- 追随者仍定期发送心跳消息,但在处理消息上存在滞后。
- 领导者可能将滞后太多的追随者移出 ISR,以确保 ISR 中的副本是相对同步的。
滞后主要指的是追随者在处理消息时相对于领导者的位置较远,即它的日志文件中的消息相对较旧。这是通过追随者的日志文件中的偏移量(offset)来衡量的。
-
- 心跳机制:检测追随者状态(在线、宕机、滞后)
-
读操作的响应
- 领导者负责处理来自消费者的读取请求。
- 消费者可以从领导者或者任意一个追随者拉取消息。领导者负责返回正确的消息,确保读取操作的正确性。
- 领导者负责处理来自消费者的读取请求。
-
故障转移
- 如果领导者宕机或者发生故障,Kafka 集群会自动进行领导者选举。新的领导者将被选举出来,确保分区的可用性。这是通过使用 ZooKeeper 进行协调的。
-
日志清理
- 领导者定期进行日志清理,删除过时的日志段,以释放磁盘空间。这有助于保持存储的合理大小
-
- 职责:
- 追随者(Follower):备份节点是领导者的追随者,它们会按照领导者的指令更新数据。如果领导者失败,追随者可以接管并保持系统正常运行。
- 消费者:
-
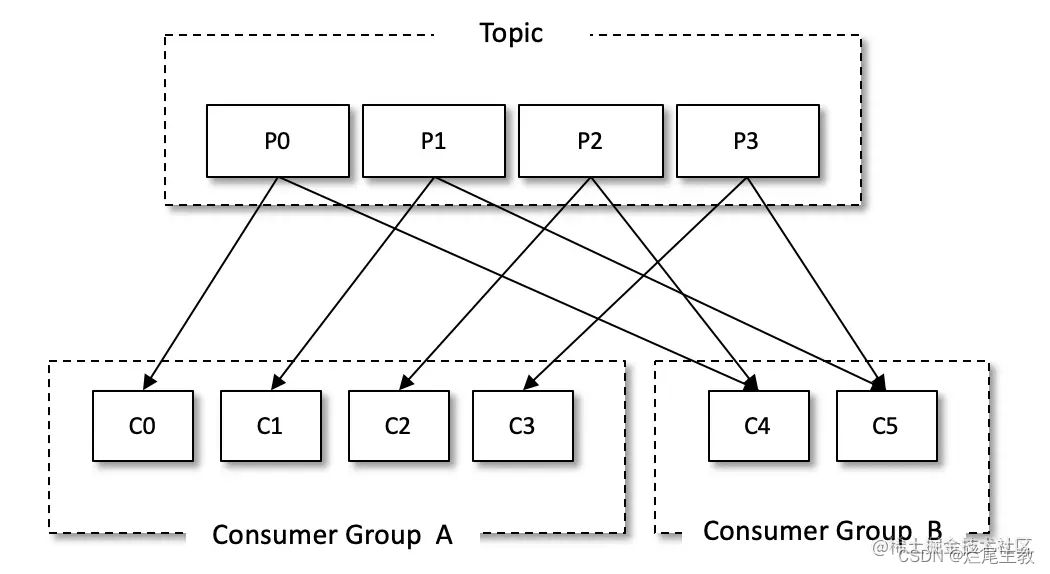
同一消费组中,消费者不能同时消费同一分区的消息
-
消费者分配消费分区策略
-
初始化(静态)
-
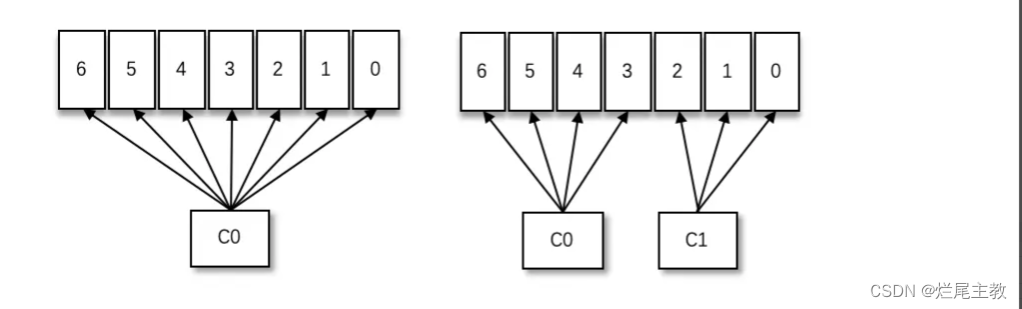
动态变化
-
同一消费组内,增加消费者
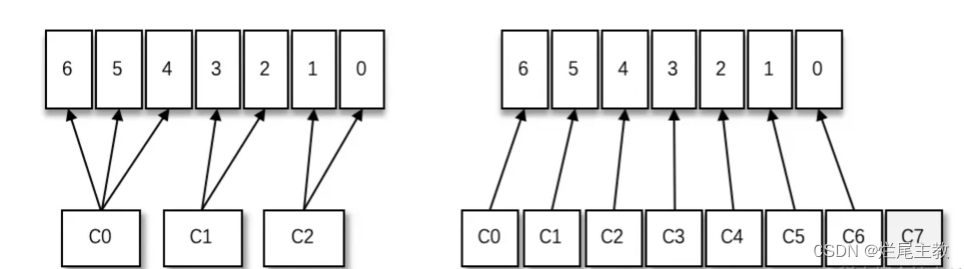
-
增加消费组
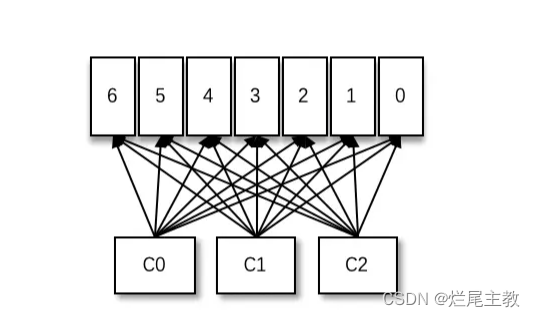
-
-
-
原文地址:https://blog.csdn.net/qq_25218219/article/details/135552974
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_57058.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






