Kafka用法总结
一、Kafka是什么
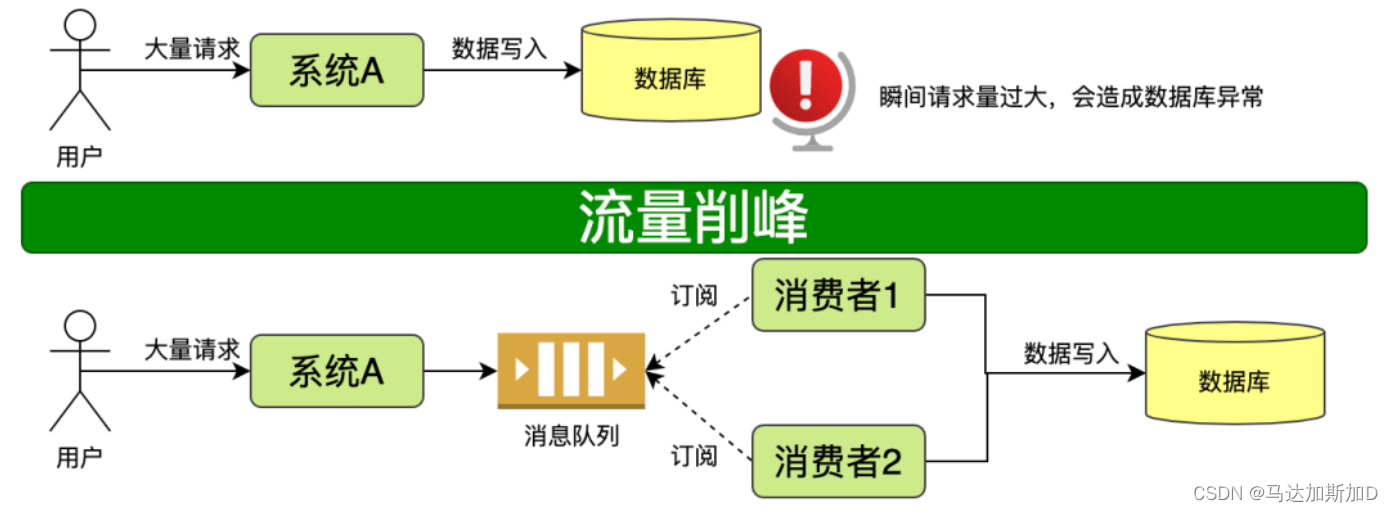
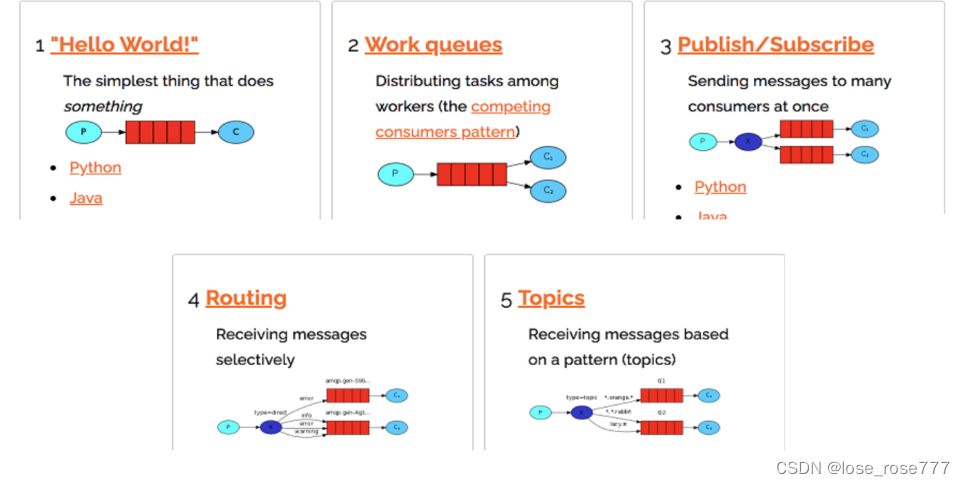
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
二、消息队列
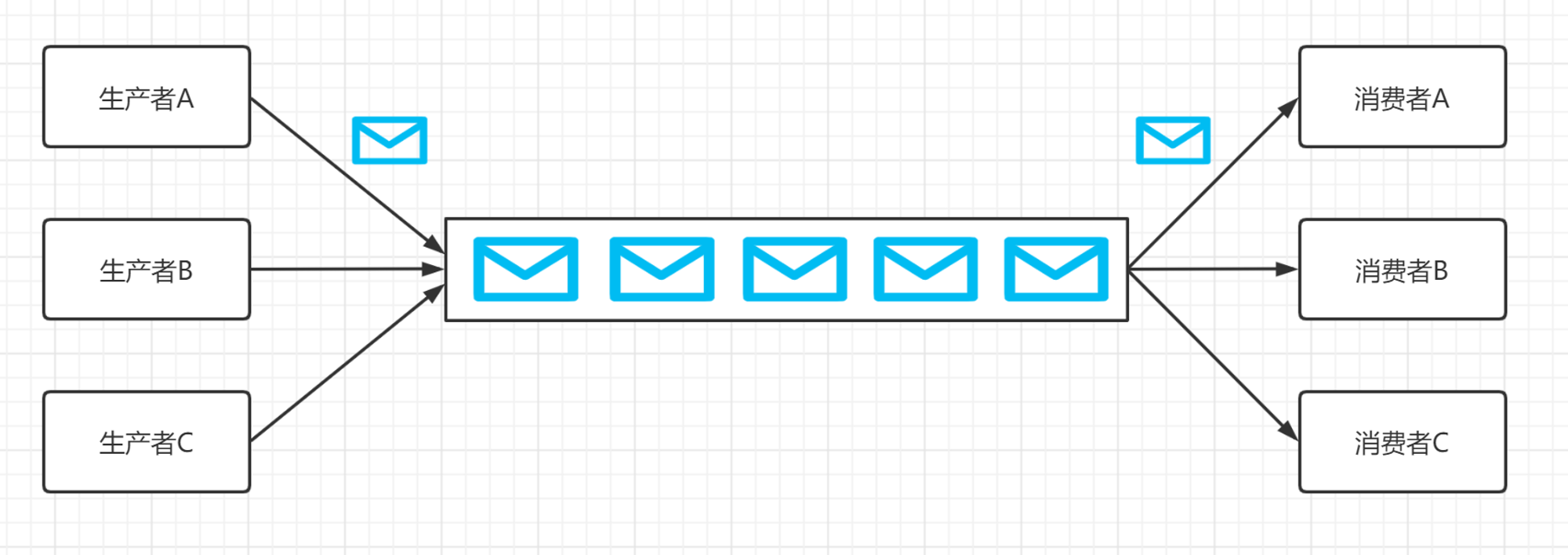
消息队列(Message queue)是一种进程间通信或同一进程的不同线程间的通信方式。把数据放到消息队列的叫做生产者,把数据从生产队列取出的叫做消费者。
消息队列目前有两种模式,点对点模式 和 发布/订阅模式
1、点对点模式

消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅模式

消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
三、Kafka架构

| 组成 | 说明 |
|---|---|
| producer | 消息生产者 |
| consumer | 消息消费者 |
| consumer group | 消费者组,由多个消费者组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者 |
| broker | 一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic |
| topic | 生产者和消费者面向的都是一个topic(类似队列) |
| partition | 一个大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition是一个有序的队列。 |
| leader | 生产者发送数据的对象,以及消费者消费数据的对象都是leader。是多个副本中的主 |
| follower | 实时从leader同步数据并保持一致性。当leader故障时数据不会丢失,并会有一个follower成为leader代其工作。 |
四、安装部署
| ip | host |
|---|---|
| 192.168.2.102 | hadoop102 |
| 192.168.2.103 | hadoop103 |
| 192.168.2.104 | hadoop104 |
-
解压安装包
tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/ -
修改文件路径
为了方便查找和后续环境变量配置修改文件路径
mv /opt/module/kafka_2.11-2.4.1 /opt/module/kafka -
在kafka目录下创建文件夹logs
mkdir /opt/module/kafka/logs -
修改配置
vim /opt/module/kafka/config/server.properties#broker的全局唯一编号,不能重复 broker.id=0 #删除topic功能使能 delete.topic.enable=true #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘IO的现成数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka运行日志存放的路径 log.dirs=/opt/module/kafka/logs #topic在当前broker上的分区个数 num.partitions=1 #用来恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 #segment文件保留的最长时间,超时将被删除 log.retention.hours=168 #配置连接Zookeeper集群地址 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka -
添加环境变量
sudo vim /etc/profile.d/my_env.sh#KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/binsh /etc/profile.d/my_env.shecho $ KAFKA_HOME -
集群内其他服务器安装并配置环境变量
修改其他机器的broker.id
-
启动
在各个服务器节点执行
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties -
关闭
在各个服务器节点执行
kafka-server-stop.sh
五、使用
1、创建topic
创建topic,名称为topicA,副本数为3,partition数为1
kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 1 --topic topicA
2、查看topic
查看hadoop102的topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka --list
3、查看topic详情
kafka-topics.sh --zookeeper hadoop102:2181/kafka --describe --topic topicA

4、发送消息
发送消息到topicA
kafka-console-producer.sh --broker-list hadoop102:9092 --topic topicA

5、消费消息
消费topicA的消息
–from-beginning 表示从头开始接受消息
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic topicA

6、修改分区数
修改topicA的分区数为3
kafka-topics.sh --zookeeper hadoop102:2181/kafka --alter --topic topicA --partitions 3
查看详情结果如下

7、删除topic
删除topicA
kafka-topics.sh --zookeeper hadoop102:2181/kafka --delete --topic topicA
原文地址:https://blog.csdn.net/m0_51192710/article/details/135603638
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_57284.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
![[MFC] MFC消息机制的补充](https://img-blog.csdnimg.cn/direct/4e6d632d6c144126a691d901337a1749.png)