前言
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask使用 BSD 授权。
一、Flask安装
Flask是第一个第三方库。与其他模块一样,安装时可以直接使用python的pip命令实现。不过首先需要保证python要安装好。
安装方式有两种一种通过命令行安装flask,第二种使用Pycharm直接创建Flask项目
个人非常推荐安装 Pycharm
1.使用命令行安装Flask
win+R打开输入cmd打开命令行
pip install flask
这将会使用 pip 包管理器从 Python Package Index(PyPI)下载并安装 Flask。
2.使用pycharm创建Flask项目
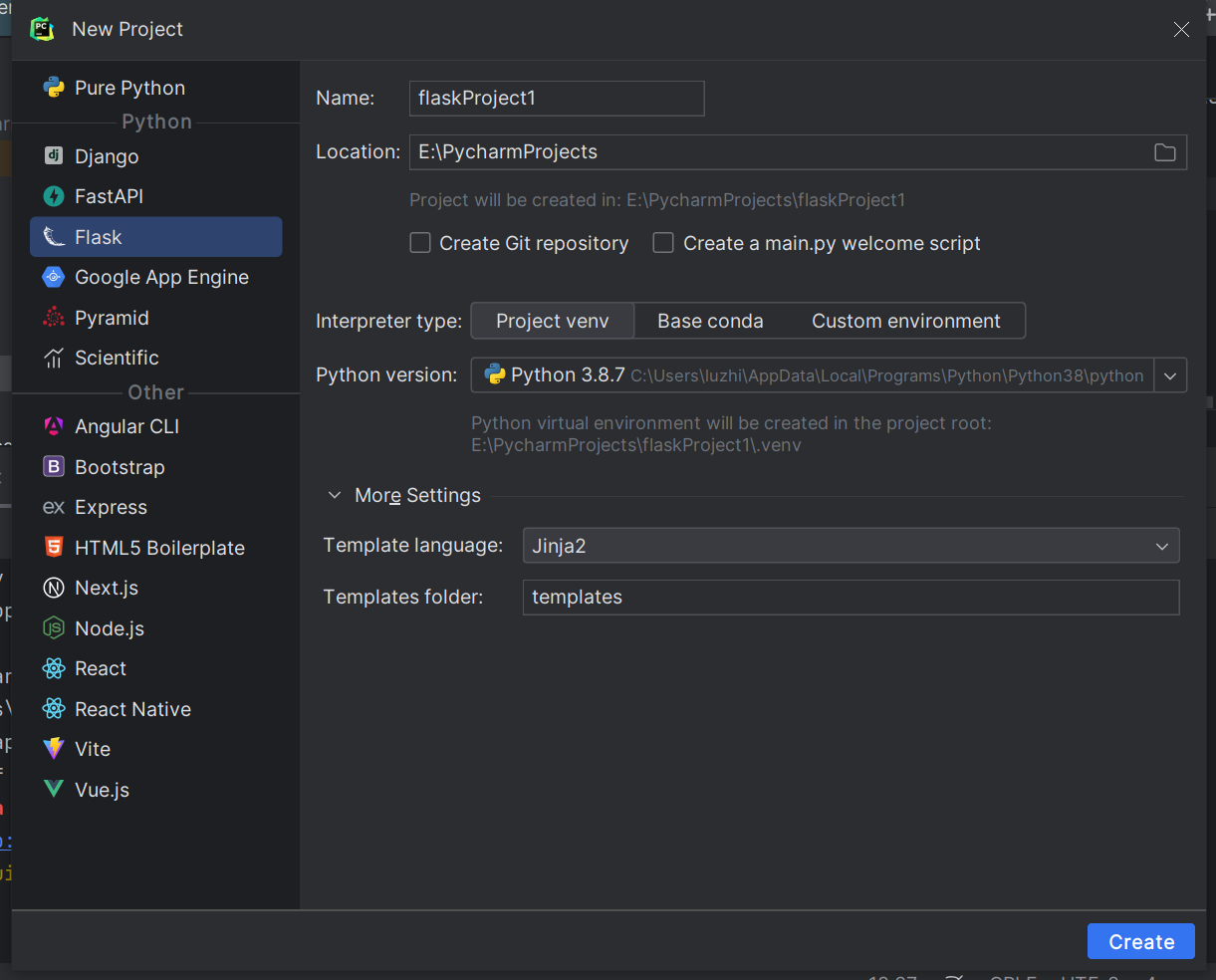
点击File->New project->选择Flask->点击Create。到这里就创建完成了
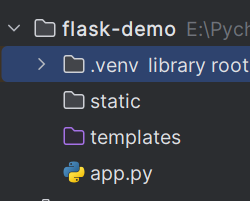
代码结构如下

二、运行Flask项目
1.使用命令运行程序
python app.py
2.在pycharm中运行
点击右上角绿色三角运行
三、路由
所谓路由,就是处理请求url和函数之间关系的程序,一个Web应用不同的路径会有不同的处理函数,当我们请求应用时,路由会根据请求的 url 找到对应处理函数。
1.基础路由定义
使用 route() 装饰器来把函数绑定到 URL:
@app.route('/')
def index():
return 'Index Page'
@app.route('/hello')
def hello():
return 'Hello, World'
2.动态url
Flask 支持在 url 中添加变量部分,使用<变量名>的形式表示,Flask 处理请求时会把变量传入视图函数,所以可以在试图函数内获取该变量的值。
@app.route('/user/<name>')
def hello_user(name):
return 'Hello {}!'.format(name)
当我们在浏览器中访问http://127.0.0.1:5000/hello/xxxx地址时,将在页面上看到”Hello xxxx!”。url 路径中/hello/后面的参数被hello()函数的name参数接收并使用。
我们还可以在 url 参数前添加转换器来转换参数类型,比如:
@app.route('/user/<int:user_id>')
def hello_user(user_id):
return 'Hello user:{}!'.format(user_id)
访问http://127.0.0.1:5000/hello/111,页面上会显示”Hello user:111!”。其中,参数类型转换器int:控制传入参数的类型只能是整形,传入其他类型将报 404 的错误,
目前支持的参数类型转换器有:
- string :字符型,但是其中不能包含斜杠”/”
- int:整型
- float:浮点型
- uuid:uuid字符类型
- path:字符型,可以包含斜杠”/”,如aa/bb/cc
除此之外,还可以设置 url 变量参数的默认值,如下,在app.route()装饰器里使用defaults参数设置,接收一个字典,来存储 url 变量参数默认值映射。
@app.route('/user', defaults={'name': 'default_name'})
@app.route('/user/<name>')
def hello_user(name):
return 'Hello {}!'.format(name)
上述代码中,/user不带参数,访问/user时,变量name就会使用默认值”default_name”。其实,这种做法等同于在hello_user()函数内给name变量设置缺省值。
3.获取url路径中?后面参数的值
使用request.args.get获取url路径中?后面参数的值
from flask import Flask, request
@app.route('/user',methods=['GET'])
def user():
name=request.args.get("name",default="张三",type=str)
return f"{name},你好";
上述代码中,获取访问地址文:/user?name=xxx中name的值,default字段为设置默认值
4.HTTP请求方法设置
HTTP 请求方法常用的有GET、POST、PUT、DELETE。Flask 路由也可以设置请求方法,在app.route()装饰器中使用使用methods参数传入一个包含监听的 HTTP 请求的可迭代对象。 比如,下面的视图
函数同时监听GET请求和POST请求:
from flask import request
@app.route('/login', methods=['GET', 'POST'])
def login():
if request.method == 'POST':
return 'This is a POST request'
else:
return 'This is a GET request'
分别使用GET请求和POST请求访问http://127.0.0.1:5000/login时,会返回不同的内容,如果使用其他的请求方法(如PUT),会报 405 Method Not Allowed 的错误。
5.url构建
Flask提供了url_for()方法来快速获取及构建 url,方法的第一个参数是视图函数的名称,之后的一个或多个参数对应的是 url 变量部分。
@app.route('/superuser')
def hello_superuser():
return 'Hello superuser!'
@app.route('/user/<name>')
def hello_user(name):
return 'Hello {}!'.format(name)
@app.route('/user/<name>')
def hello(name):
if name == 'superuser':
return redirect(url_for('hello_superuser'))
else:
return redirect(url_for('hello_user', name=name))
上述代码中:url_for()方法是根据试图函数名称获取url,redirect()是根据 url 重定向到视图函数,二者配合使用,用作 url 的重定向。hello(name)函数接受来自 url 的参数的值,判断值是否与superuser匹配,如果匹配,则使用redirect(url_for())将应用程序重定向到hello_superuser()函数,否则重定向到hello_user()函数。
四、模板
在 Python 内部生成 HTML 不好玩,且相当笨拙。因为您必须自己负责 HTML 转义,以确保应用的安全。因此, Flask 自动为您配置 Jinja2 模板引擎。
模板可被用于生成任何类型的文本文件。对于 web 应用来说,主要用于生成 HTML 页面,但是也可以生成 markdown 、用于电子邮件的纯文本等等。
1.使用 render_template()渲染模板
使用 render_template() 方法可以渲染模板,您只要提供模板 名称和需要作为参数传递给模板的变量就行了。下面是一个简单的模板渲染例子:
@app.route('/blog/<int:blog_id>')
def hello(name=None):
return render_template('blog.html')
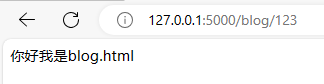
Flask 会在 templates 文件夹内寻找模板。因此,需要在app.py同级下新建文件夹templates,在templates 中创建名字为blog的html文件
访问结果如下:
2.给模板传递参数并渲染
下列代码中:接收用户传来的参数,并且创建了一个User类一并传到模板中进行渲染
class User():
def __init__(self, username, email):
self.username = username
self.email = email
# 重写__dict__属性,返回字典形式的对象信息
@app.route('/blog/<int:blog_id>')
def hello(blog_id=None):
user_info = User("Cheryl", "cheryl.superlu@gmail.com")
return render_template('blog.html', blog_id=blog_id, user=user_info)
blog.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>blog</title>
</head>
<body>
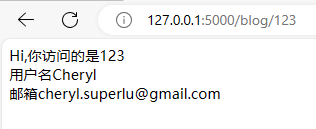
Hi,你访问的是{{ blog_id }}
<div>
用户名{{ user.username }}<br>
邮箱{{ user.email }}
</div>
</body>
</html>
访问结果如下:
3.if、for
控制器:
@app.route('/student')
def student():
stu=Student("Cheryl",18,["看书","学习","运动"])
return render_template("student.html",stu=stu)
1.if条件控制
Jinja2中的if条件判断语句必须放在{% if %}中间,并且还必须有结束的标签{% endif %},并且可以使用 and 和 or 来进行逻辑合并操作。
模板:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
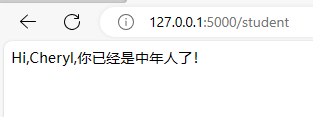
{% if stu.age>=18 and stu.age<30 %}
Hi,{{ stu.name }},你已经是成年人了!
{% elif stu.age>=30 %}
Hi,{{ stu.name }},你已经是中年人了!
{% else %}
Hi,{{ stu.name }},你是未成年!
{% endif %}
</body>
</html>
结果:
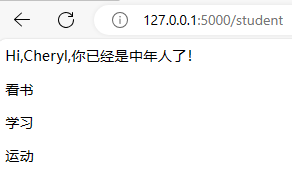
2.for循环
Jinja2中的for循环语句必须放在{% for statement %}中间,并且还必须有结束的标签{% endfor %}。假设模板文件如下 :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{#判断语句#}
{% if stu.age>=18 and stu.age<30 %}
Hi,{{ stu.name }},你已经是成年人了!
{% elif stu.age>=30 %}
Hi,{{ stu.name }},你已经是中年人了!
{% else %}
Hi,{{ stu.name }},你是未成年!
{% endif %}
{#循环语句#}
{% for item in stu.hobby %}
<p>{{ item }}</p>
{% endfor %}
</body>
</html>
结果:
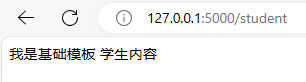
4.模板继承
Jinja2中可以使用extends来继承模板,block相当于占位符子模板中进行填充内容即可
基础模板-base.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>
{% block title %}
{% endblock %}
</title>
</head>
<body>
我是基础模板
{% block body %}
{% endblock %}
</body>
</html>
学生模板-student.html:
{% extends 'base.html' %}
{% block title %}
学生模板
{% endblock %}
{% block body %}
学生内容
{% endblock %}
结果
五、Flask-SQLAlchemy操作数据库
我这里操作数据库使用的是Flask-SQLAlchemy
认识Flask-SQLAlchemy
- Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展。它致力于简化在 Flask 中 SQLAlchemy 的使用。
- SQLAlchemy 是目前python中最强大的 ORM框架, 功能全面, 使用简单。
ORM优缺点
优点
- 有语法提示, 省去自己拼写SQL,保证SQL语法的正确性
- orm提供方言功能(dialect, 可以转换为多种数据库的语法), 减少学习成本
- 防止sql注入攻击
- 搭配数据迁移, 更新数据库方便
- 面向对象, 可读性强, 开发效率高
缺点
- 需要语法转换, 效率比原生sql低
- 复杂的查询往往语法比较复杂 (可以使用原生sql替换)
1.安装
pip install flask-sqlalchemy
flask-sqlalchemy 在安装/使用过程中, 如果出现 ModuleNotFoundError: No module named ‘MySQLdb’错误, 则表示缺少mysql依赖包, 可依次尝试下列两个方案后重试
- 方案1: 安装 mysqlclient依赖包 (如果失败再尝试方案2):
pip install mysqlclient - 方案2: 安装pymysql依赖包:
pip install pymysql
mysqlclient 和 pymysql 都是用于mysql访问的依赖包, 前者由C语言实现的, 而后者由python实现, 前者的执行效率比后者更高, 但前者在windows系统中兼容性较差, 工作中建议优先前者。
2.组件初始化
flask-sqlalchemy 的相关配置也封装到了 flask 的配置项中, 可以通过app.config属性 或 配置加载方案(如config.from_object) 进行设置
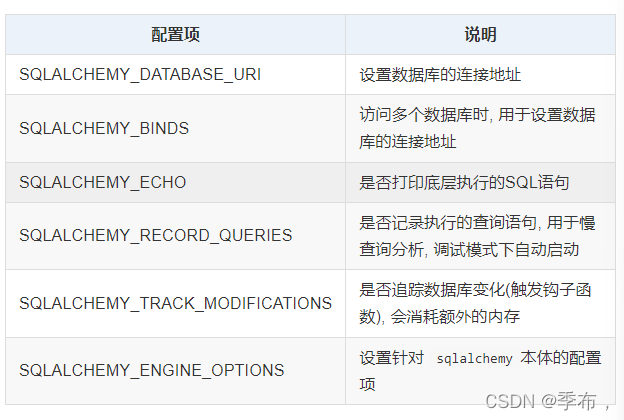
数据库URI(连接地址)格式: 协议名://用户名:密码@数据库IP:端口号/数据库名, 如:
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
如果数据库驱动使用的是 pymysql, 则协议名需要修改为
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:mysql@127.0.0.1:3306/demo'
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 设置数据库连接地址
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/demo'
# 是否追踪数据库修改(开启后会触发一些钩子函数) 一般不开启, 会影响性能
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 是否显示底层执行的SQL语句
app.config['SQLALCHEMY_ECHO'] = True
两种初始化方式
- 方式1-初始化组件对象, 直接关联Flask应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 应用配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 方式1: 初始化组件对象, 直接关联Flask应用
db = SQLAlchemy(app)
- 方式2-先创建组件, 延后关联Flass应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 方式2: 初始化组件对象, 延后关联Flask应用
db = SQLAlchemy()
def create_app(config_type):
"""工厂函数"""
# 创建应用
flask_app = Flask(__name__)
# 加载配置
config_class = config_dict[config_type]
flask_app.config.from_object(config_class)
# 关联flask应用
db.init_app(app)
return flask_app
3.构建模型类
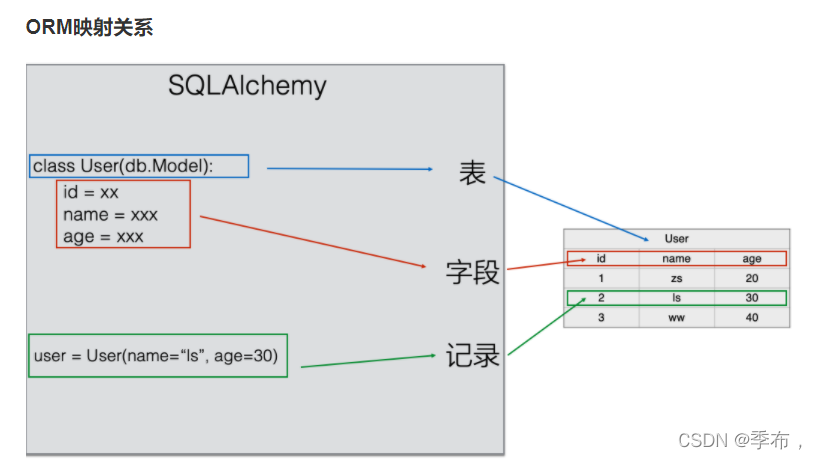
- 类 对应 表
- 类属性 对应 字段
- 实例对象 对应 记录
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 类->表 类属性->字段 实例对象->记录
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, age):
self.name = name
self.age = age
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
if __name__ == '__main__':
app.run(debug=True)
注意点
- 模型类必须继承 db.Model, 其中 db 指对应的组件对象
- 表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
- 类属性对应字段, 必须是通过 db.Column() 创建的对象
- 可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表
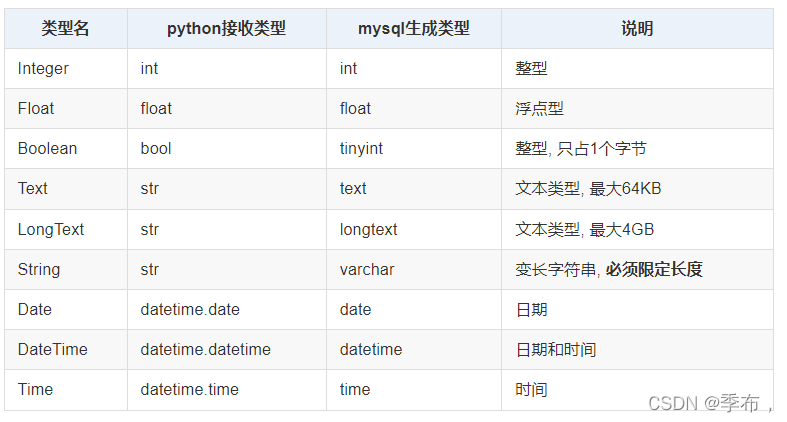
常用的字段类型
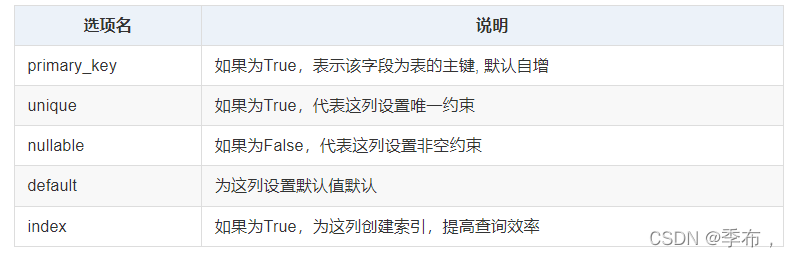
常用的字段选项
4.数据操作
- 这里的 会话 并不是 状态保持机制中的 session,而是 sqlalchemy 的会话。它被设计为 数据操作的执行者, 从SQL角度则可以理解为是一个 加强版的数据库事务
- sqlalchemy 会 自动创建事务, 并将数据操作包含在事务中, 提交会话时就会提交事务
- 事务提交失败会自动回滚
1.增加数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.创建模型对象
users = User("Cheryl", 88)
# 2.将模型对象添加到会话中
db.session.add(users)
# 添加多条记录
# db.session.add_all([user1, user2, user3])
# 3.提交会话 (会提交事务)
# sqlalchemy会自动创建隐式事务
# 事务失败会自动回滚
db.session.commit()
return "index"
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, age):
self.name = name
self.age = age
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
if __name__ == '__main__':
app.run()
2.查询数据
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.get查询,根据根据主键查询
user = User.query.get(1)
# 2.查询所有用户数据
user_list = User.query.all() # 返回列表, 元素为模型对象
# 3.查询有多少个用户
user_count=User.query.count()
# 4.查询id为4的用户[3种方式]
# 方式1: 根据id查询 返回模型对象/None
User.query.get(4)
# 方式2: 等值过滤器 关键字实参设置字段值 返回BaseQuery对象
# BaseQuery对象可以续接其他过滤器/执行器 如 all/count/first等
User.query.filter_by(id=4).all()
# 方式3: 复杂过滤器 参数为比较运算/函数引用等 返回BaseQuery对象
User.query.filter(User.id == 4).first()
# 5.分页查询, 每页3个, 查询第2页的数据 paginate(页码, 每页条数)
pn = User.query.paginate(page=1, per_page=2)
print(f"总页数{pn.pages},每页条数{pn.per_page}")
userList=[]
for user in pn.items:
userList.append(user.to_dict())
print(f"当前页的数据 {userList}")
# 封装返回结果
result = {
"code": "200",
"msg": "信息查询成功!",
"data": None
}
result_data=[]
for user in user_list:
result_data.append(user.to_dict())
result['data'] = user_count
return jsonify(result)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
3.更新数据
flask-sqlalchemy 提供了两种更新数据的方案
- 先查询, 再更新
对应SQL中的 先select, 再update - 基于过滤条件的更新 (推荐方案)
对应SQL中的 update xx where xx = xx (也称为 update子查询 )
1.先查询, 再更新
这种方式的缺点
- 查询和更新分两条语句, 效率低
- 如果并发更新, 可能出现更新丢失问题(Lost Update)
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
#更新返回受影响的行数
user=User.query.filter(User.name=="wang").first()
user.name="update"
db.session.commit()
return ""
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
2.基于过滤条件的更新
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
- 会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
操作步骤如下:
- 配合 查询过滤器filter() 和 更新执行器update() 进行数据更新
- 提交会话
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
#更新返回受影响的行数
result=User.query.filter(User.name=="wang").update({"name":"update"})
print(result)
db.session.commit()
return ""
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
4.删除数据
类似更新数据, 也存在两种删除数据的方案
先查询, 再删除
- 对应SQL中的 先select, 再delete
基于过滤条件的删除 (推荐方案)
- 对应SQL中的 delete xx where xx = xx (也称为 delete子查询 )
1.先查询, 再删除
这种方式的缺点:
- 查询和删除分两条语句, 效率低
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.查询
user=User.query.filter(User.name=='wang').first()
# 2.从db.session中删除
db.session.delete(user)
# 3.将db.session中的修改,同步到数据库中
db.session.commit()
return "数据删除成功!"
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
2.基于过滤条件的删除
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 会对满足过滤条件的所有记录进行删除, 可以实现批量删除处理
操作步骤如下:
- 配合 查询过滤器filter() 和 删除执行器delete() 进行数据删除
- 提交会话
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.查询
user=User.query.filter(User.name=='wang').delete()
# 2.提交会话
db.session.commit()
return "数据删除成功!"
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
5. 刷新数据
- Session 被设计为数据操作的执行者, 会先将操作产生的数据保存到内存中
- 在执行 flush刷新操作 后, 数据操作才会同步到数据库中
有两种情况下会 隐式执行刷新操作
- 提交会话
- 执行查询操作 (包括 update 和 delete 子查询)
开发者也可以 手动执行刷新操作 session.flush()
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.创建新的用户
user=User("王五","xxx@xcx.com",88)
# 2.添加用户
db.session.add(user)
# 3.主动执行flush()操作立即执行sql
db.session.flush()
# 提交会话会自动执行flush操作
db.session.commit()
return "数据删除成功!"
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
user1 = User(name='wang', email='wang@163.com', age=20)
user2 = User(name='zhang', email='zhang@189.com', age=33)
user3 = User(name='chen', email='chen@126.com', age=23)
user4 = User(name='zhou', email='zhou@163.com', age=29)
user5 = User(name='tang', email='tang@itheima.com', age=25)
user6 = User(name='wu', email='wu@gmail.com', age=25)
user7 = User(name='qian', email='qian@gmail.com', age=23)
user8 = User(name='liu', email='liu@itheima.com', age=30)
user9 = User(name='li', email='li@163.com', age=28)
user10 = User(name='sun', email='sun@163.com', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
if __name__ == '__main__':
app.run()
6.多表关联查询
案例中包含两个模型类: User用户模型 和 Address地址模型, 并且一个用户可以有多个地址, 两张表之间存在一对多关系
 关系属性
关系属性
关系属性是 sqlalchemy 封装的一套查询关联数据的语法, 其目的为 让开发者使用 面向对象的形式 方便快捷的获取关联数据
import json
from flask import Flask, jsonify
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://root:root@127.0.0.1:3306/flast_demo?charset=utf8mb4'
# 创建组件对象
db = SQLAlchemy(app)
@app.route('/')
def index():
# 1.添加数据
user = User("张三", "xxx@xx.com", 88)
db.session.add(user)
db.session.flush()
address1 = Address("山东济南", user.id)
address2 = Address("山东济宁", user.id)
db.session.add_all([address1, address2])
db.session.commit()
# 2.查询多表数据,要求查询名字为张三的地址信息
result=User.query.filter(User.name == "张三").first()
return result.to_dict()
# 构建模型类
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
email = db.Column('email', db.String(20)) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
address = db.relationship("Address")
def __init__(self, name, email, age):
self.name = name
self.email = email
self.age = age
def to_dict(self):
adr_list=[]
for adr in self.address:
adr_list.append(adr.to_dict())
return {
"id": self.id,
"name": self.name,
"email": self.email,
"age": self.age,
"address": adr_list
}
class Address(db.Model):
__tablename__ = 't_address'
id = db.Column(db.Integer, primary_key=True)
address = db.Column('address', db.String(20), unique=True)
user_id = db.Column(db.Integer, db.ForeignKey('t_user.id'))
def __init__(self, detail, user_id):
self.detail = detail
self.user_id = user_id
def to_dict(self):
return {
"id": self.id,
"detail": self.detail,
"user_id": self.user_id
}
with app.app_context():
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
if __name__ == '__main__':
app.run()
4.连接查询
- 开发中有 联表查询需求 时, 一般会使用 join连接查询
- sqlalchemy 也提供了对应的查询语法
db.session.query(主表模型字段1, 主表模型字段2, 从表模型字段1, xx.. ).join(从表模型类, 主表模型类.主键 == 从表模型类.外键)
- join语句 属于查询过滤器, 返回值也是 BaseQuery 类型对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/demo')
def demo():
"""查询多表数据 需求: 查询姓名为"张三"的用户id和地址信息"""
# sqlalchemy的join查询
data = db.session.query(User.id, Address.detail).join(Address, User.id == Address.user_id).filter(User.name == '张三').all()
for item in data:
print(item.detail, item.id)
return "demo"
@app.route('/')
def index():
"""添加数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2, user1])
db.session.commit()
return 'index'
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关联查询的性能优化
- 通过前边的学习, 可以发现 无论使用 外键 还是 关系属性 查询关联数据, 都需要查询两次, 一次查询用户数据, 一次查询地址数据
- 两次查询就需要发送两次请求给数据库服务器, 如果数据库和web应用不在一台服务器中, 则 网络IO会对查询效率产生一定影响
- 可以考虑使用 连接查询 join 使用一条语句就完成关联数据的查询
# 使用join语句优化关联查询
adrs = Address.query.join(User, Address.user_id == User.id).filter(User.name == '张三').all() # 列表中包含地址模型对象
Flask-SQLAlchemy摘抄自:https://blog.csdn.net/weixin_47906106/article/details/123774620
六、使用flask-migrate迁移ORM模型
在Flask-SQLAlchemy中使用 db.create_all() 创建所有继承自db.Model的表,但是这种方法有个弊端就是我先在User类中新增一个字段表不会更新
使用flask-migrate来解决这个问题
下载依赖
pip install flask-migrate
ORM模型映射成表的三步
- 1.flask db init; 这部只需要执行一次
- 2.flask db migrate; 识别ORM模型的改变,生成迁移脚本
- 3.flask db upgrade; 运行迁移脚本,同步到数据库中
原文地址:https://blog.csdn.net/qq_43548590/article/details/135549983
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_57610.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!