本文介绍: Web 应用程序的 3 层架构公有子网层私有子网层数据子网层用于存储 Session(替代方案:DynamoDB)用于缓存来自 RDS 的数据多可用区RDS用于存储用户数据用于扩展读取的读取副本用于灾难恢复的多可用区Elastic Beanstalk 是在 AWS 上部署应用程序的以开发人员为中心的视图它使用了我们之前见过的所有组件:EC2、ASG、ELB、RDS……托管服务自动处理容量配置、负载平衡、扩展、应用程序运行状况监控、实例配置……
Classic Solutions Architecture
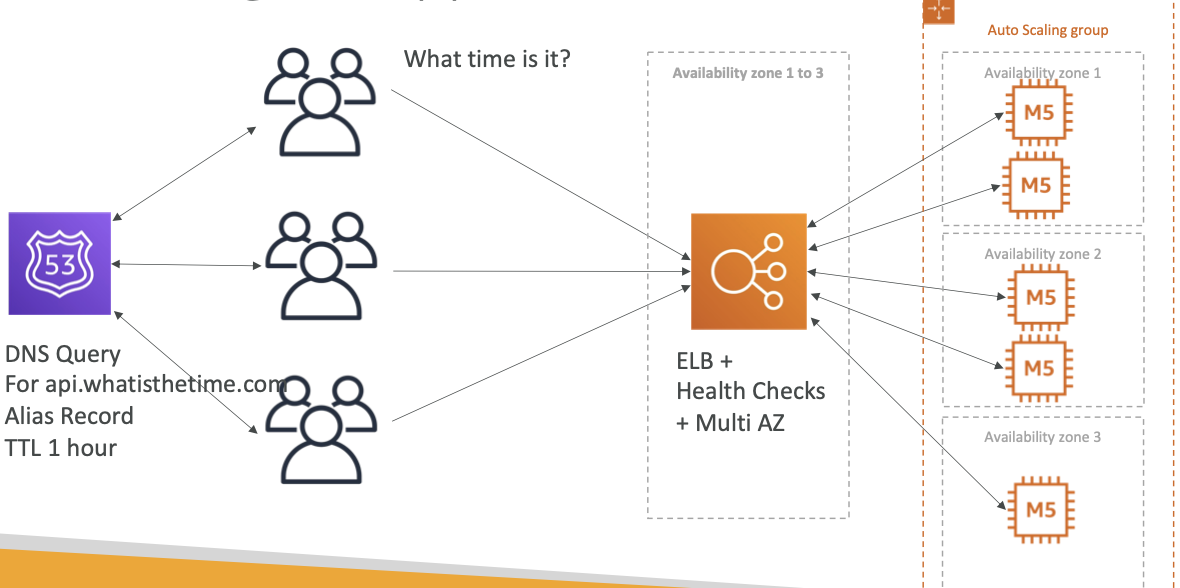
无状态 Web 应用程序:WhatIsTheTime.com
背景 & 目标
架构演进
Well-Architected 5 pillars
成本、性能、可靠性、安全性、卓越运营
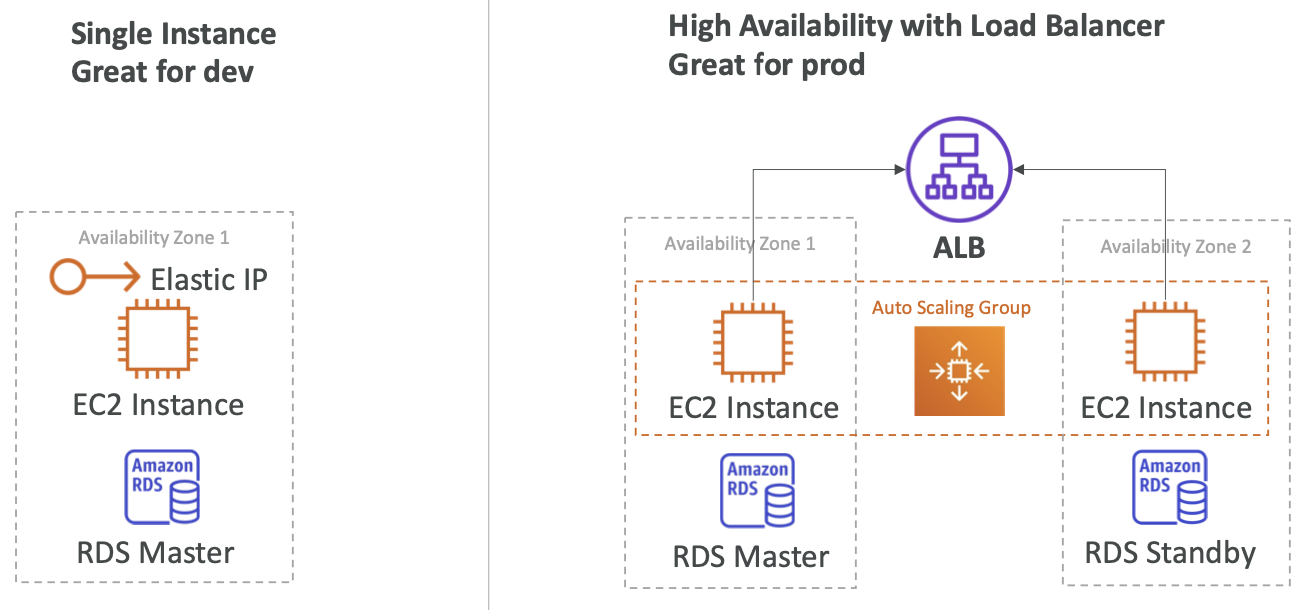
有状态的 Web 应用程序:MyClothes.com
背景 & 目标
架构演进
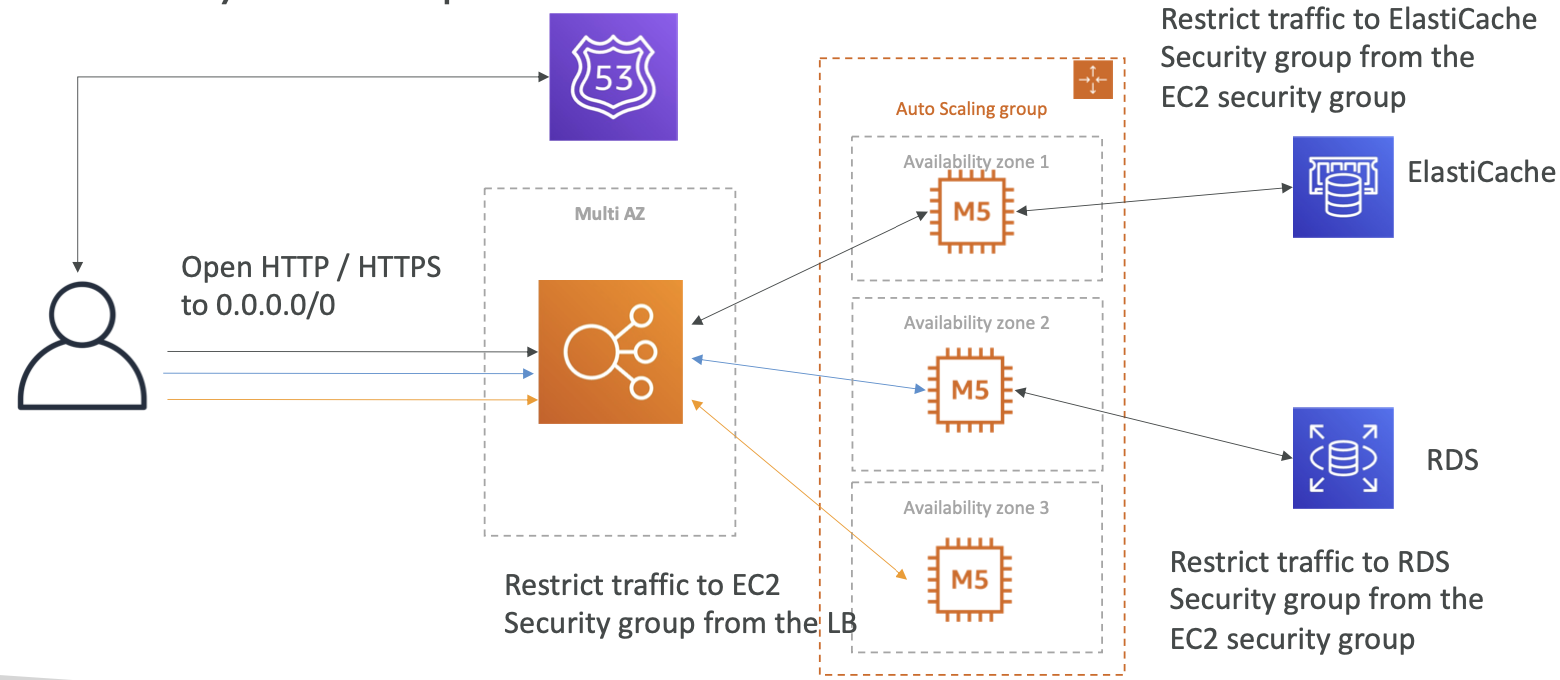
总结
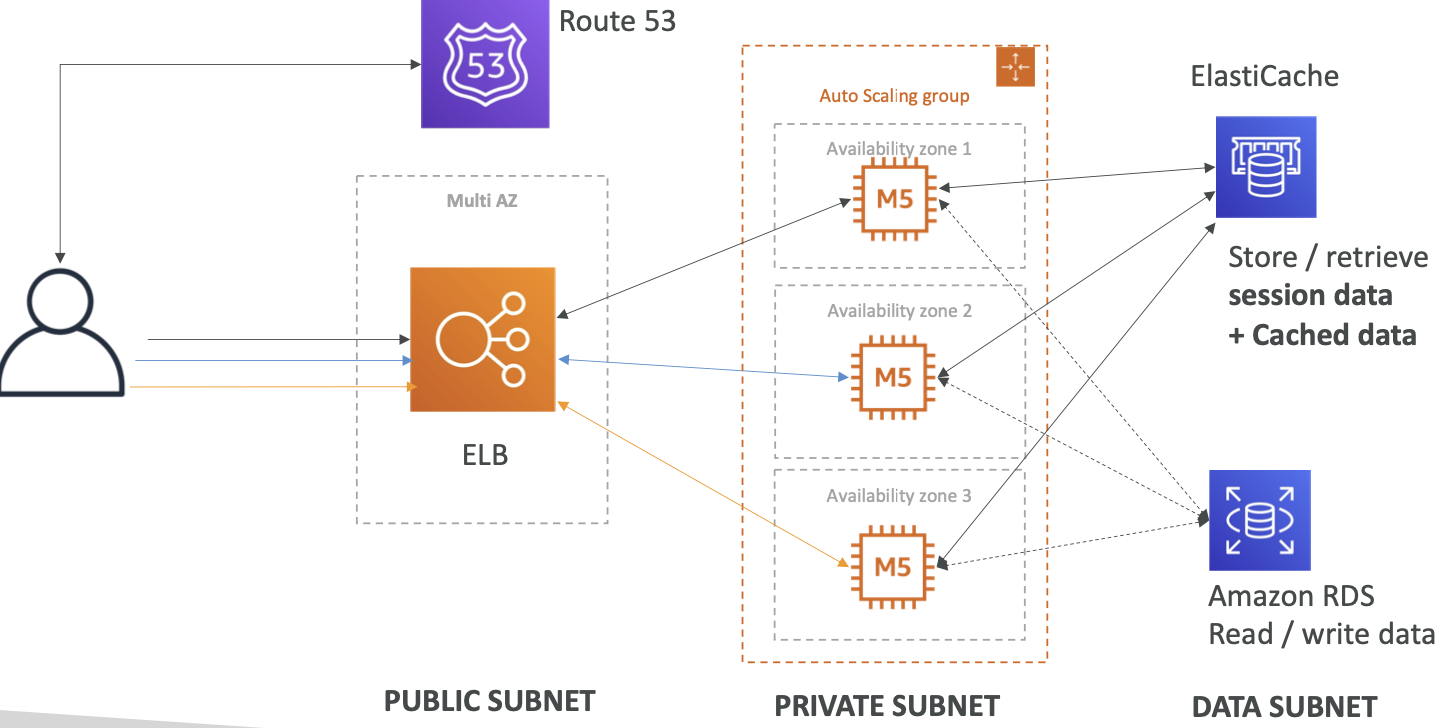
有状态的 Web 应用程序:MyWordPress.com
背景 & 目标
架构演进
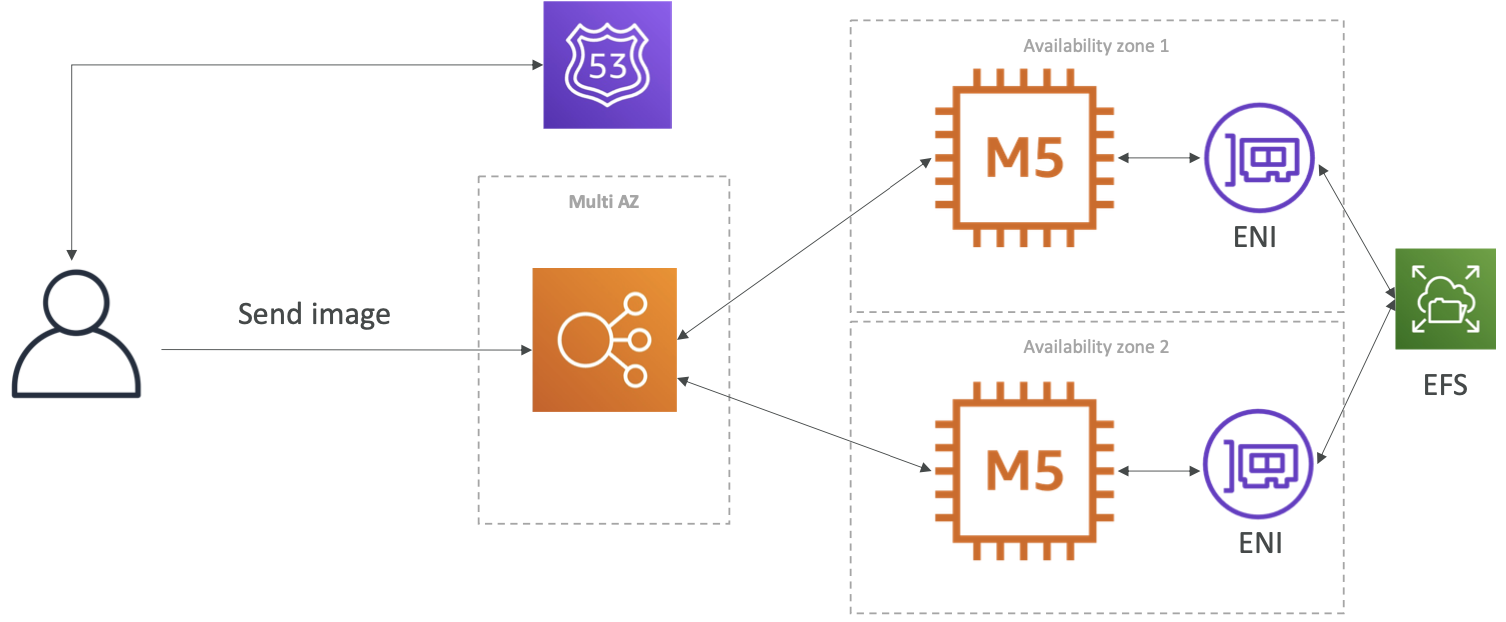
快速实例化应用程序
AWS 上的开发人员的问题
Elastic Beanstalk
概述
组成
支持的平台
Web ServerTier vs. WorkerTier
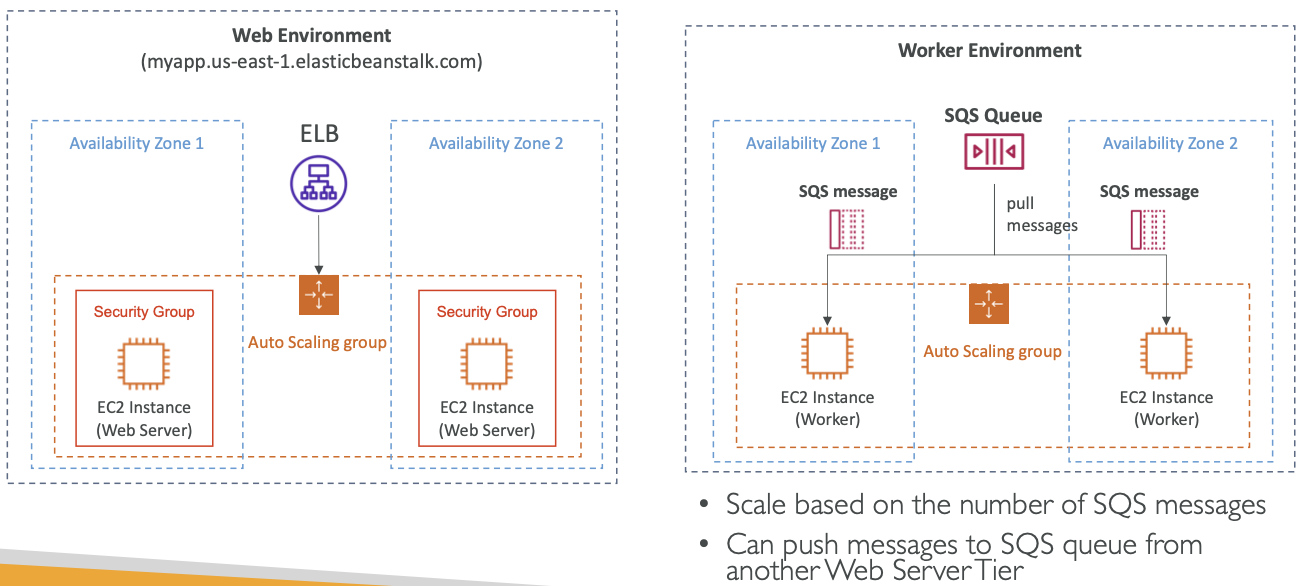
Elastic Beanstalk 部署模式

Amazon S3 Section
Amazon S3 Use cases
Amazon S3 — Buckets
Amazon S3 — Objects
Amazon S3 — Security
S3 Bucket Policies

示例:公共访问 — 使用存储桶策略

示例:用户访问 S3 — IAM 权限

示例:EC2 实例访问 — 使用 IAM 角色

进阶:跨账户访问 — 使用存储桶策略


Amazon S3 — Static Website Hosting(静态网站托管)
Amazon S3 — Versioning
Amazon S3 — Replication(CRR & SRR)
Notes
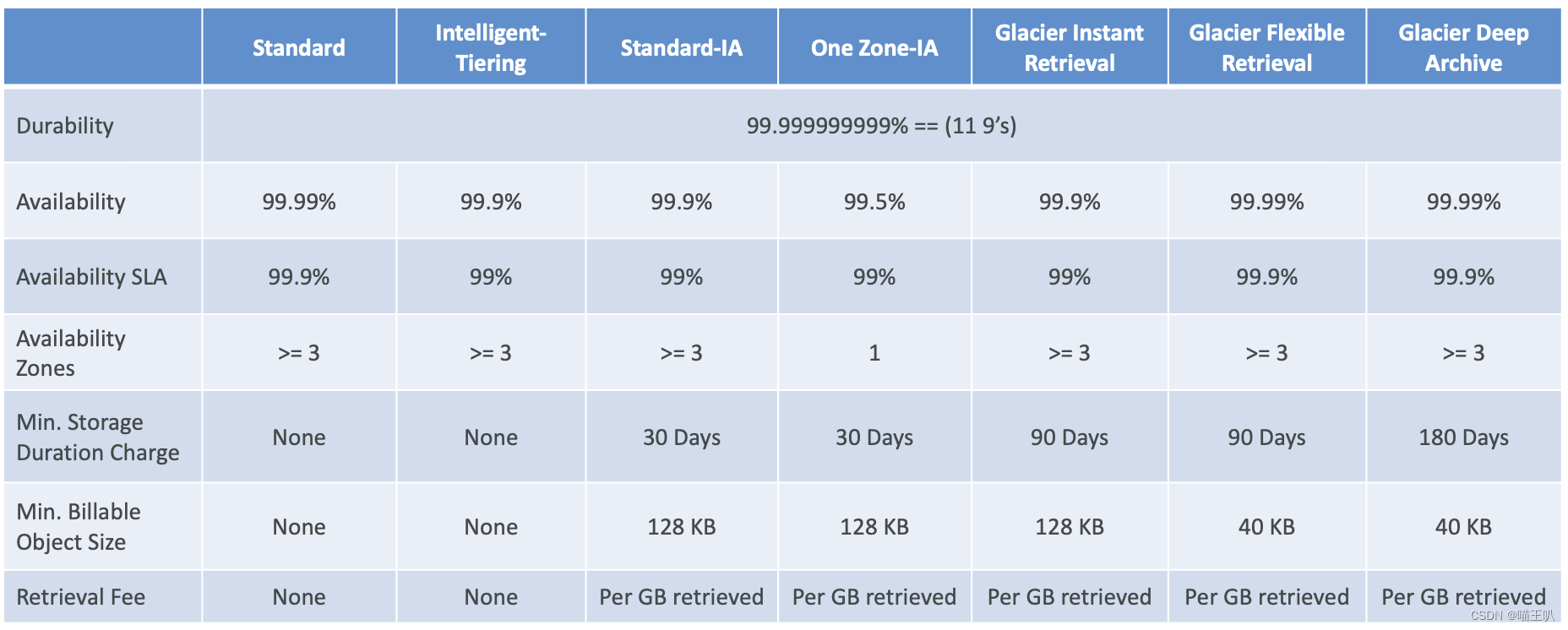
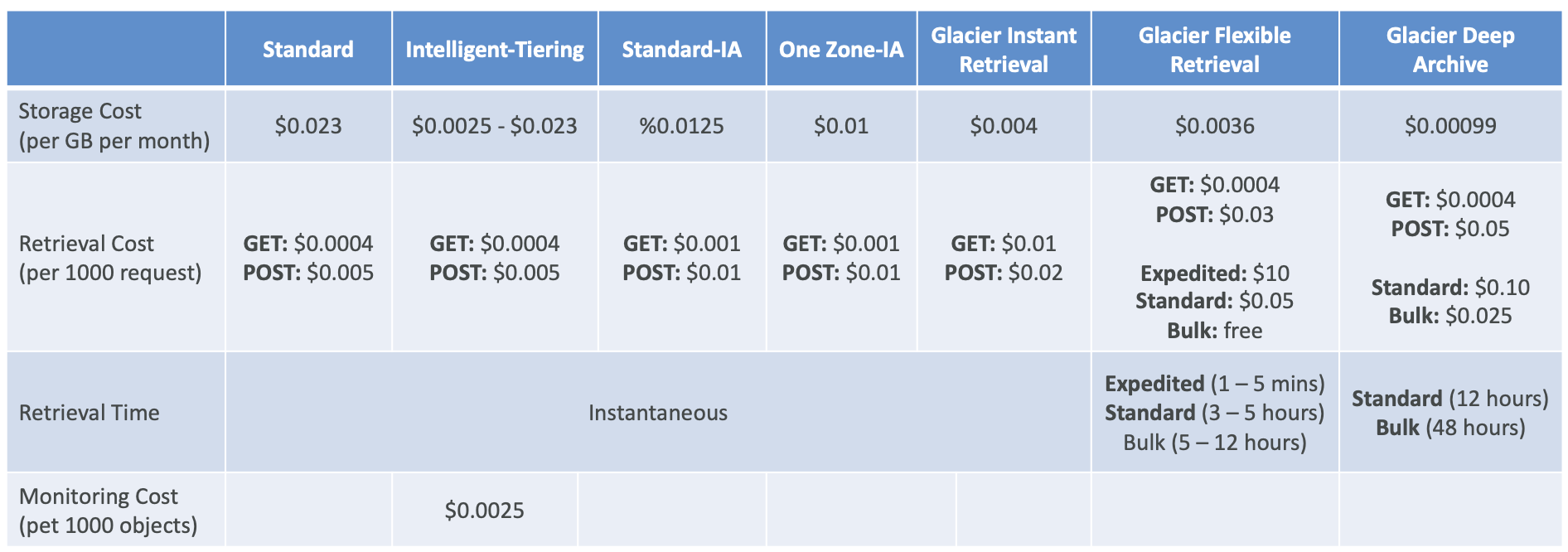
Amazon S3 Storage Classes
S3 Durability and Availability
S3 Standard — 通用
S3 Storage Classes — Infrequent Access
S3 Glacier Storage Classes
S3 Intelligent Tiering
Advanced S3
Amazon S3 — Storage Classes 间的转换
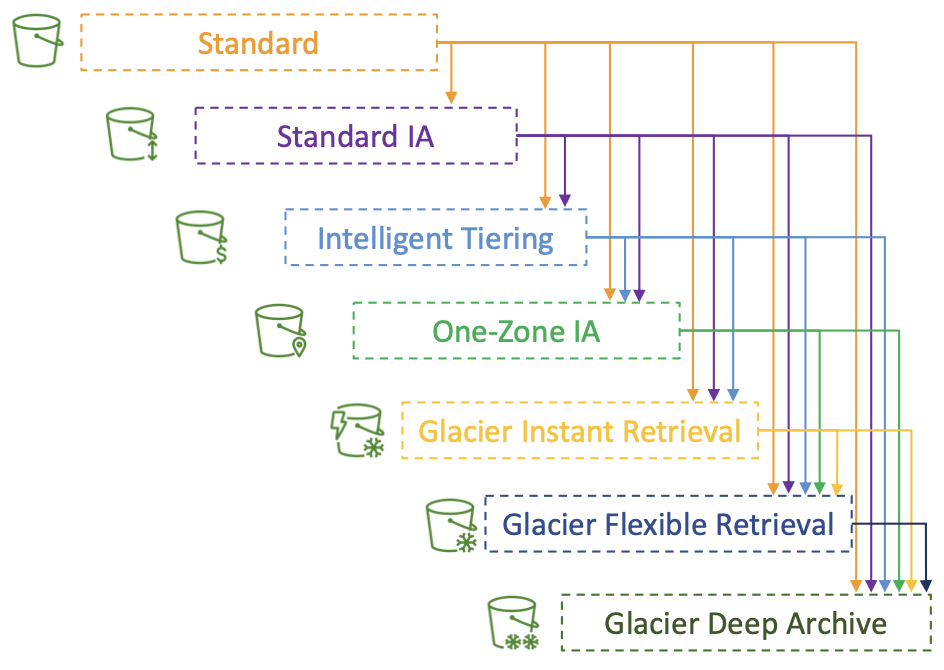
Amazon S3 — Lifecycle Rules
Amazon S3 — 生命周期规则(场景 1)
Amazon S3 — 生命周期规则(场景 2)
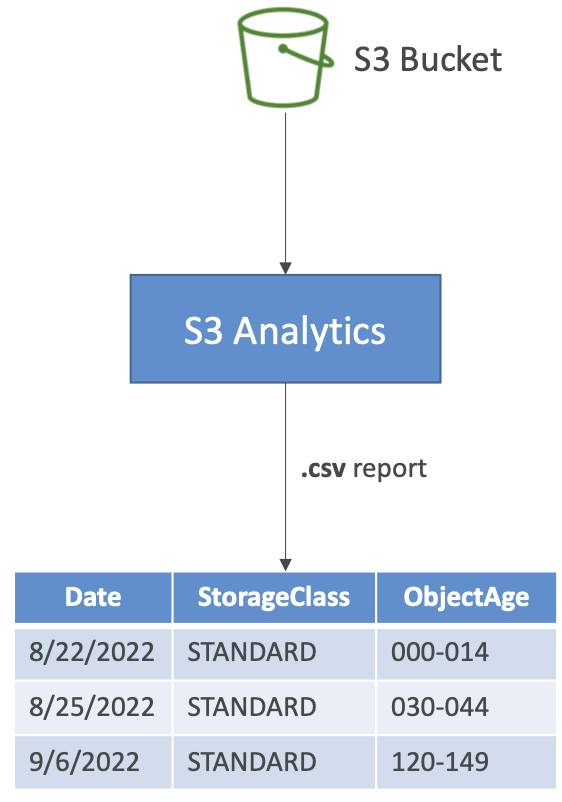
Amazon S3 Analytics — Storage Class Analysis
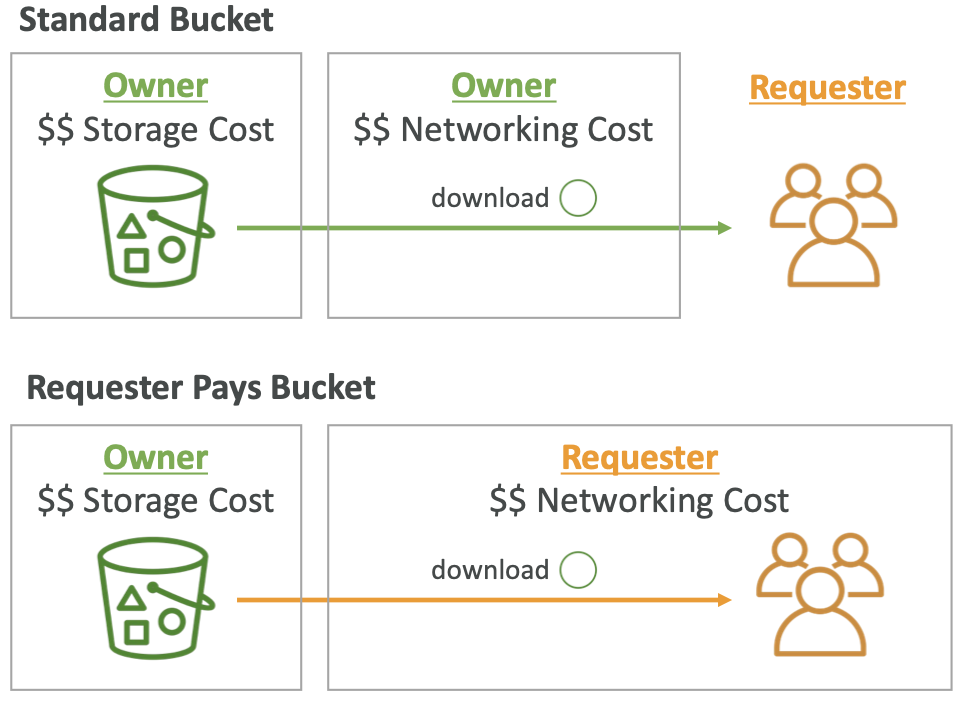
S3 — Requester Pays
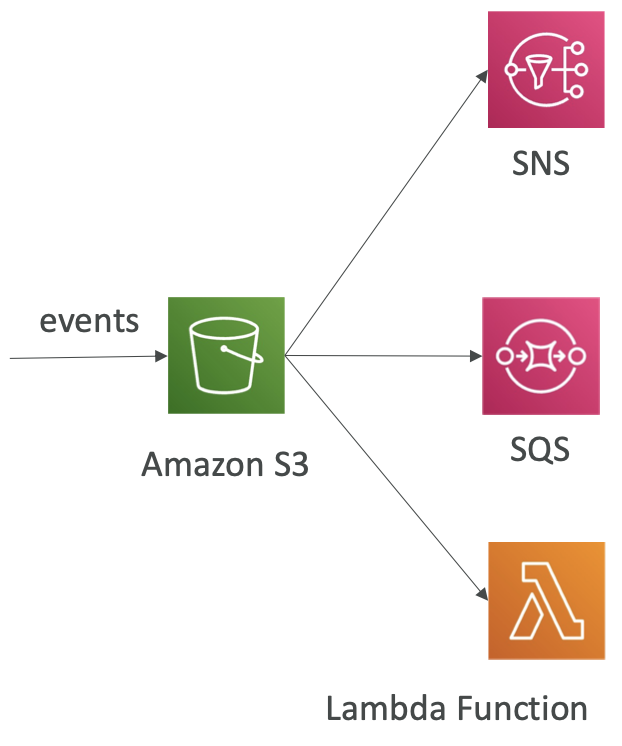
S3 Event Notifications
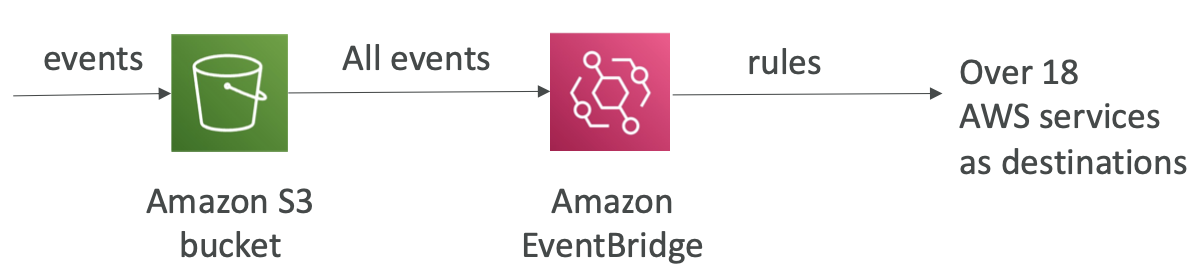
使用 Amazon EventBridge 的 S3 事件通知
S3 — Baseline Performance 基准性能
S3 Performance
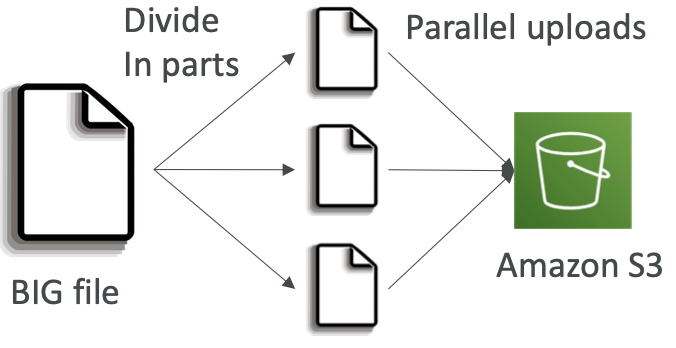
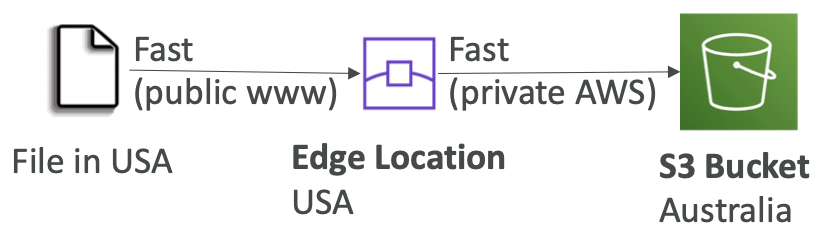
S3 Performance — S3 Byte-Range Fetches
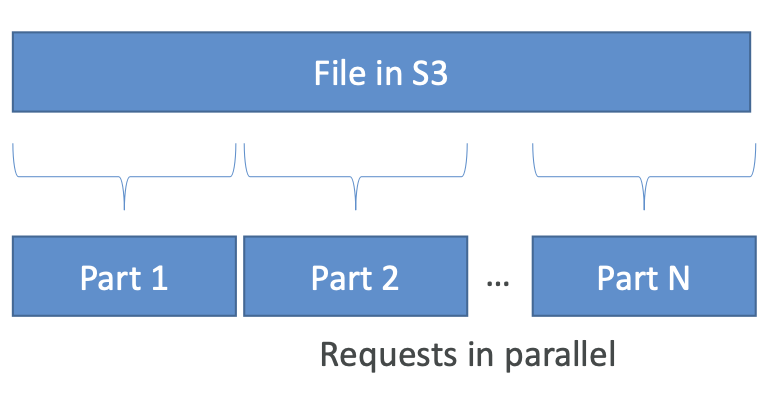

S3 Select 和 Glacier Select
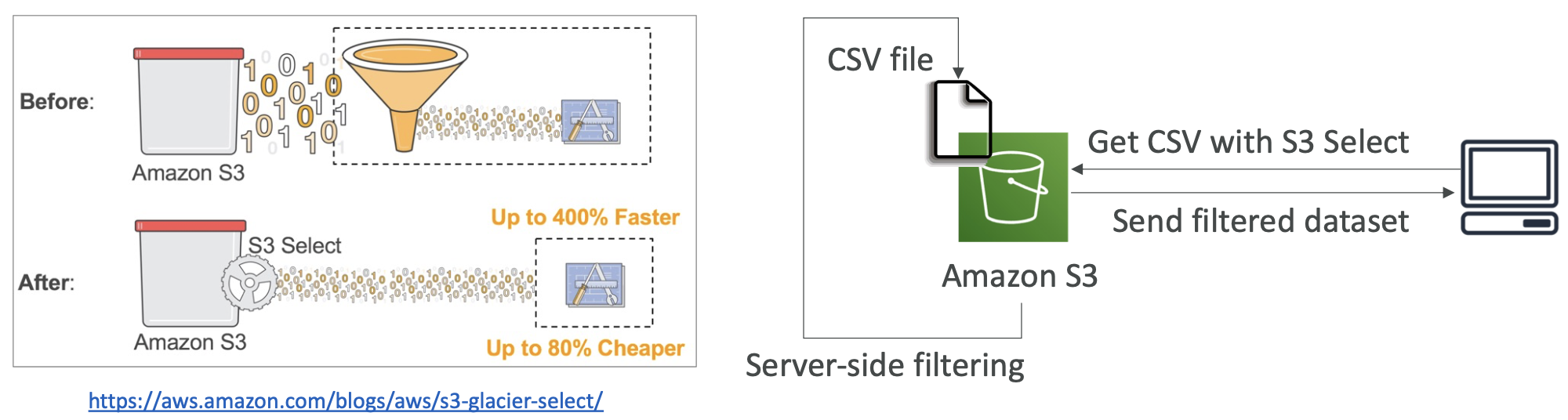
S3 批量操作
Amazon S3 安全
Amazon S3 — 对象加密
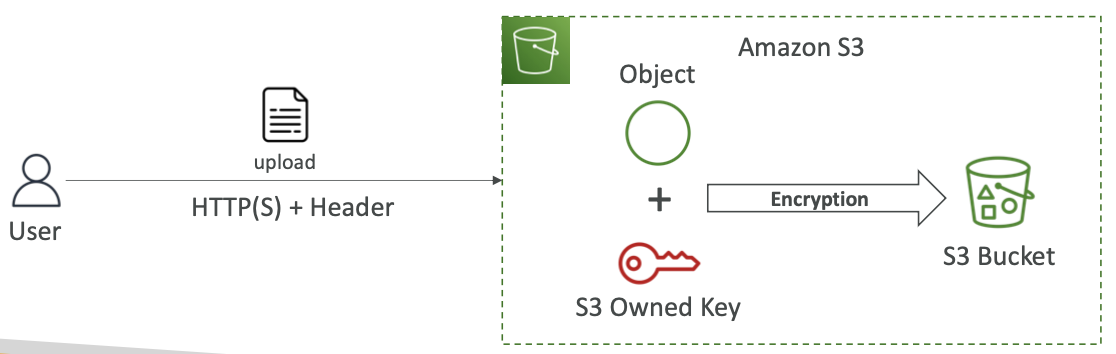
Amazon S3 加密 — SSE-S3
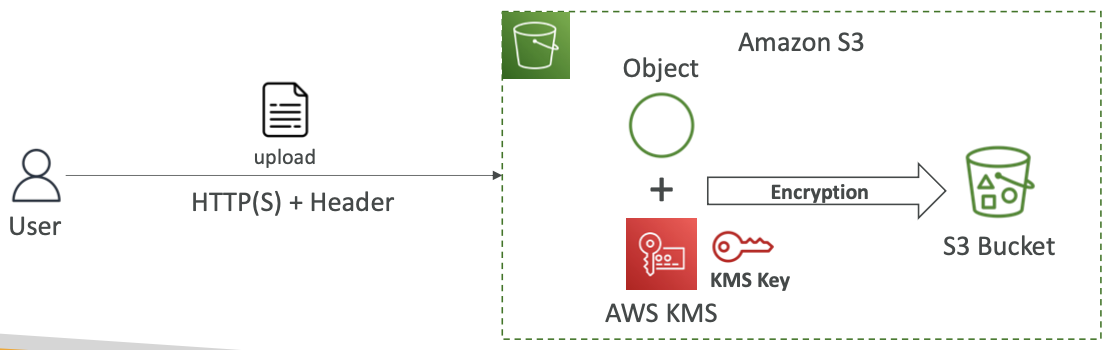
Amazon S3 加密 — SSE-KMS
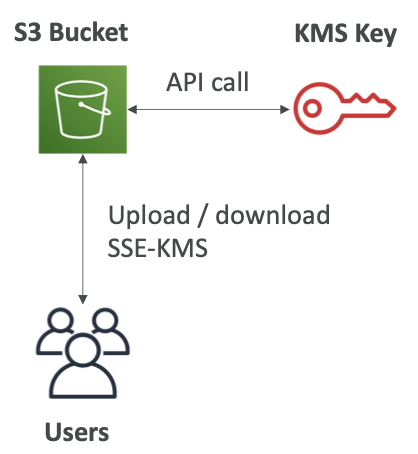
SSE-KMS Limitation
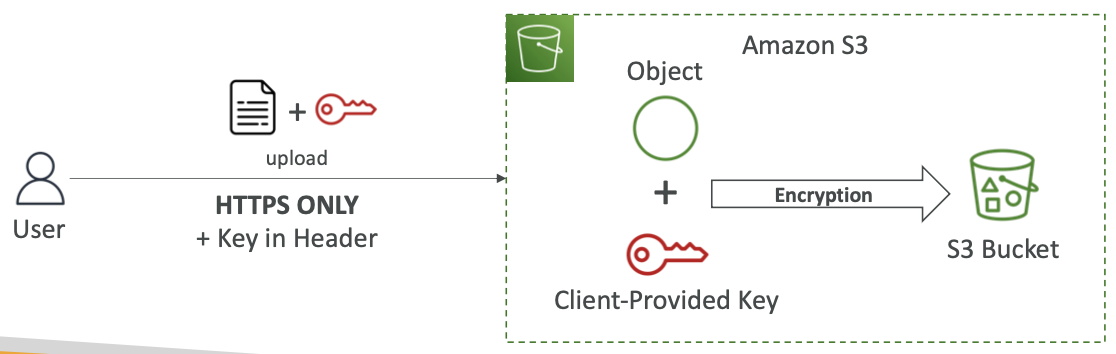
Amazon S3 加密 — SSE-C
Amazon S3 加密 — Client-Side Encryption
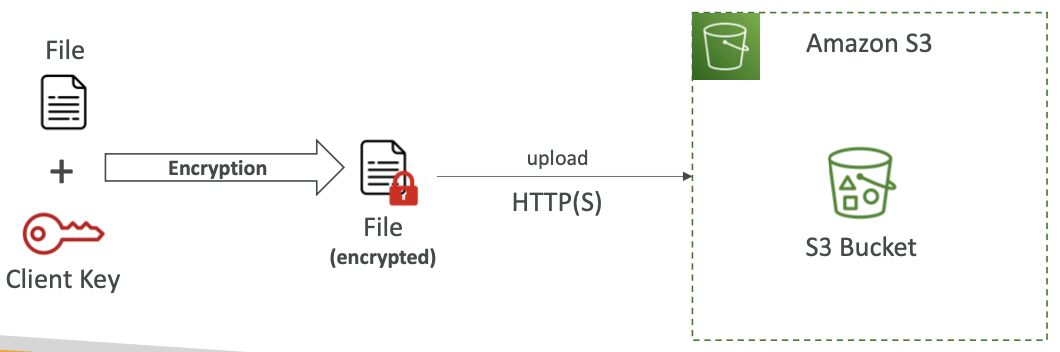
Amazon S3 — Encryption in transit (SSL/TLS)
Amazon S3 — Default Encryption vs. Bucket Policies

什么是 CORS?

Amazon S3 — CORS

Amazon S3 — MFA Delete
S3 访问日志

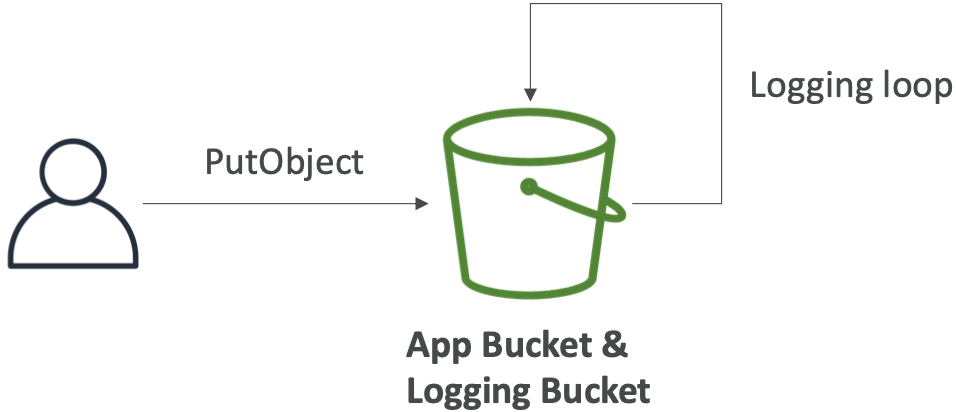
S3 访问日志:警告
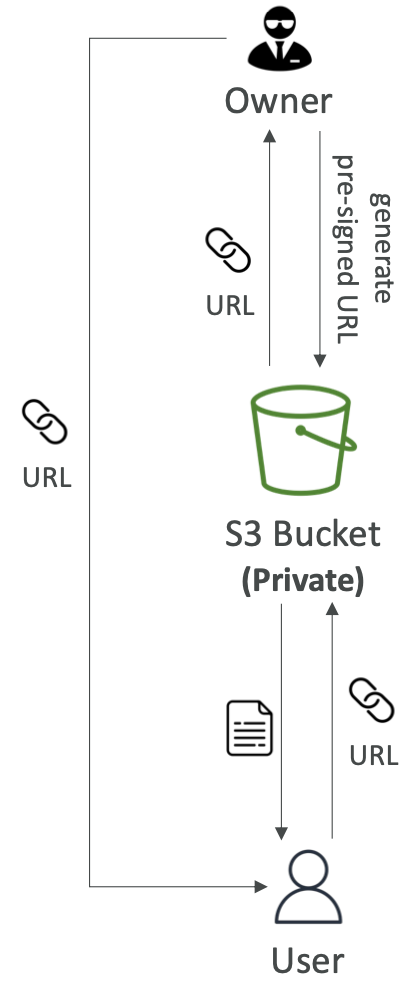
Amazon S3 — 预签名 URL
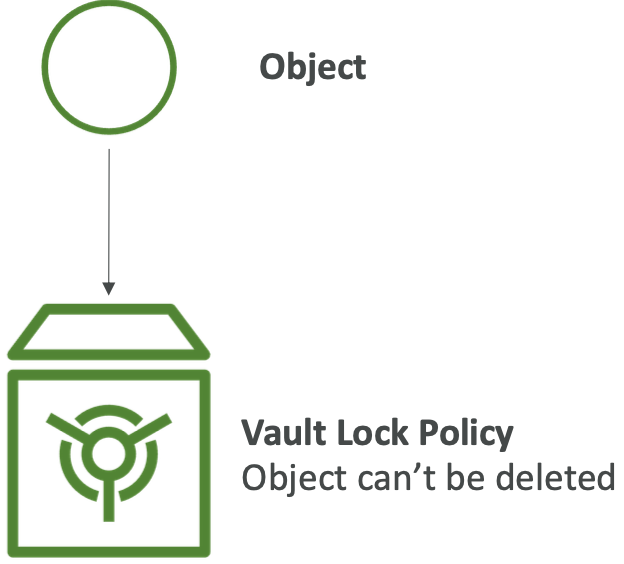
 |
|S3 Glacier Vault Lock
 |
|S3 Object Lock(必须启用版本控制)
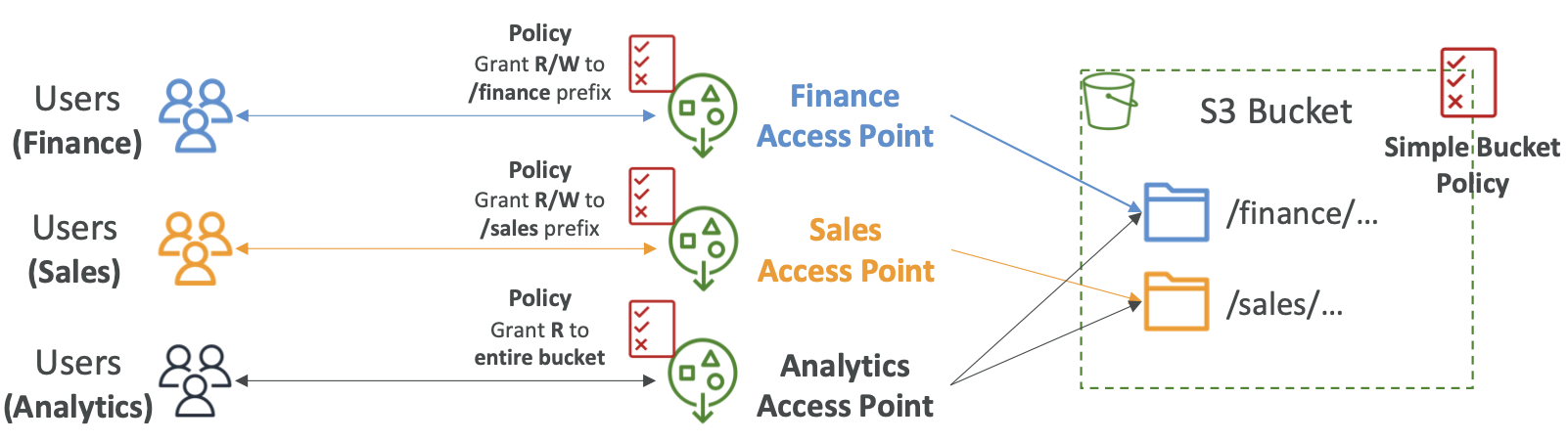
S3 – Access Points(接入点)
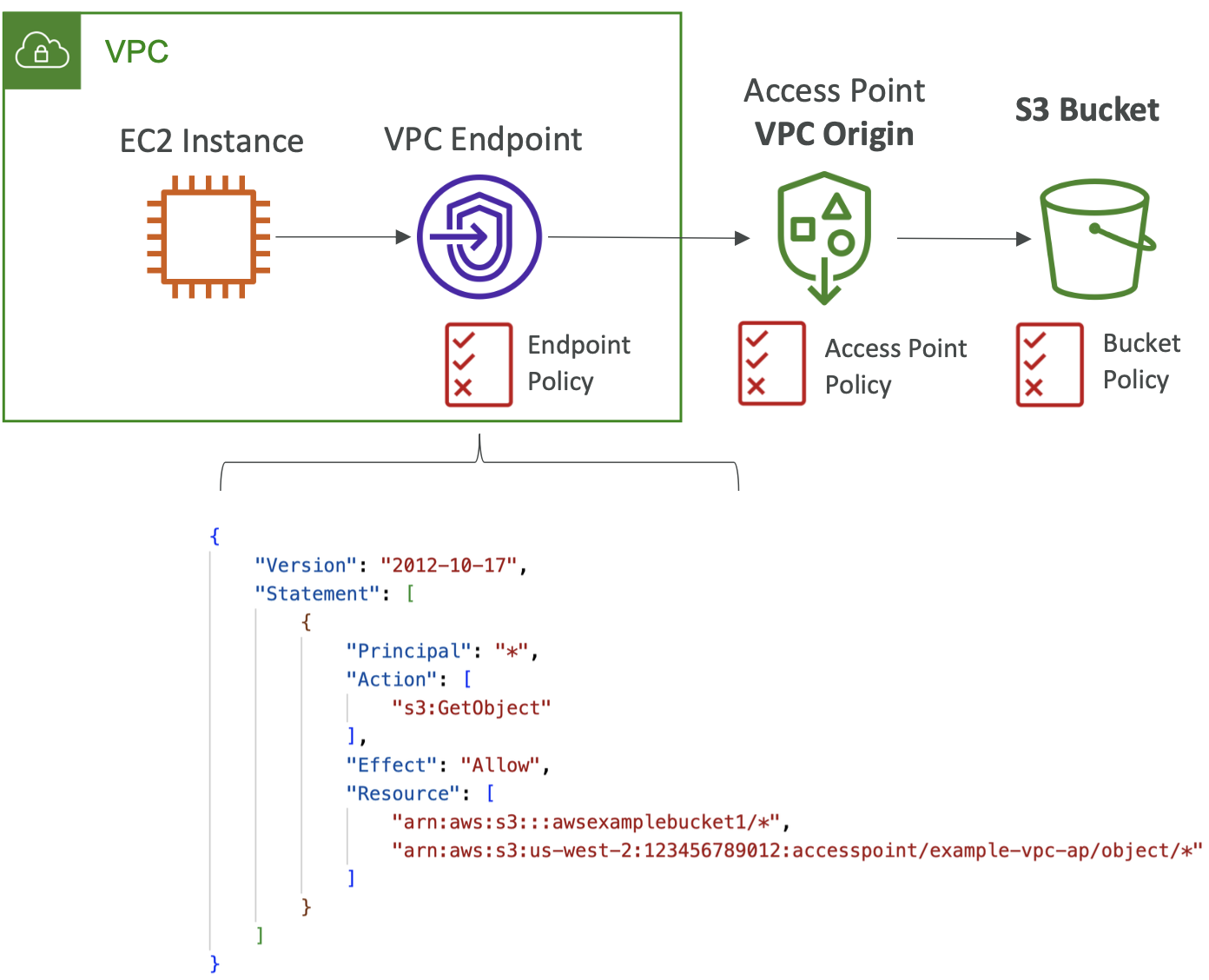
S3 – 接入点 – VPC Origin
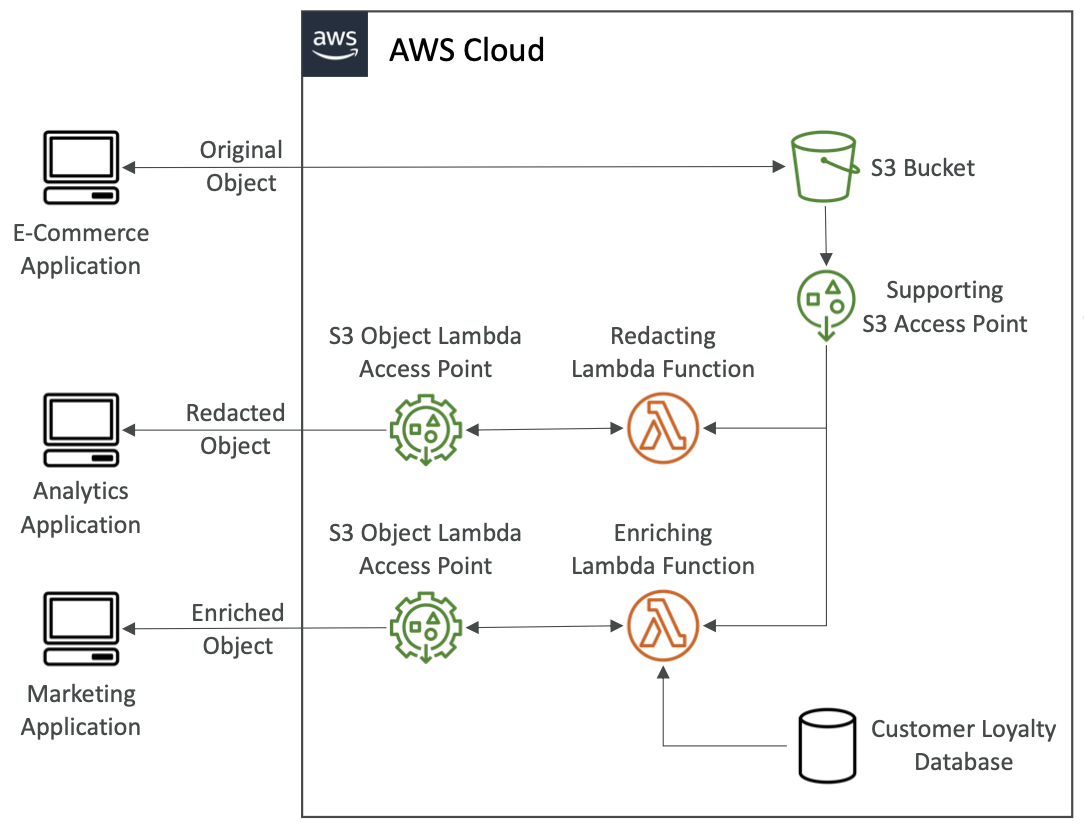
S3 Object Lambda
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。