目录
-
- 1. 十大排序简述
- 2. 请写一个方法判断一个整数是奇数还是偶数。
- 3. 请写一个方法判断一个整数是否是2的n次方。
- 4. 对字节变量,其二进制表示法中求有多少个1,如 00101010则返回值为 3,也是要求效率最高。
- 5. 100万的数据选出前1万大的数
- 6. 二分查找
- 7. BFS(广度优先搜索)
- 8. DFS(深度优先搜索)
- 9. 请写出求斐波那契数列任意一位的值的算法
- 10. 下列代码在运行中会产生几个临时对象?
- 11. 怎么判断一个点是否在直线上?
- 12. 判断点是否在线段上?
- 13. 解决哈希冲突的方法
- 14. 常用的hash算法
- 15. 逆矩阵的作用
- 16. 数组和 List 的区别
- 17. 数据结构中数组和链表各有什么特点,什么场合下应该使用数组,什么 场合下应该使用链表
- 18. 请简要介绍Unity中常用数据结构
- 19. Unity中常见的碰撞算法
- 20. Unity中常见的路径搜索算法
- 21. Unity中常见的曲线插值算法
- 22. 请解释Unity中的递归算法的性能问题,以及如何避免性能问题?
- 23. 简要介绍Unity中的常用的随机化算法?
- 24. 简要介绍Unity中常用的光照算法?
1. 十大排序简述

-
十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
-
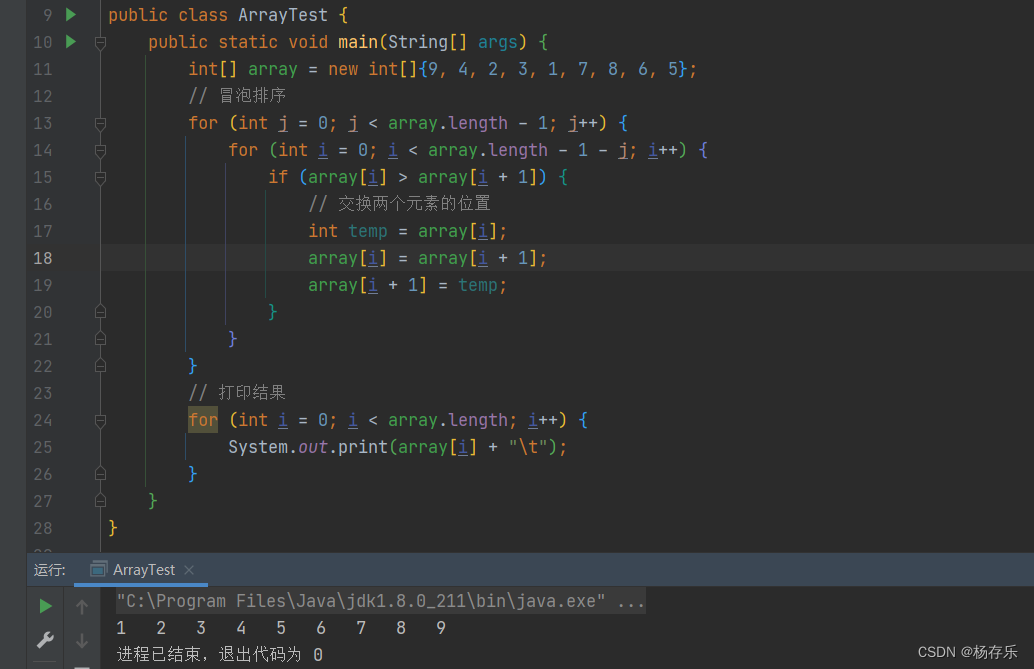
冒泡排序(Bubble Sort)
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。 -
选择排序(Selection Sort)
选择排序(Selection-sort)是一种简单直观的排序算法。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。 -
插入排序(Insertion Sort)
插入排序(Insertion-Sort)的算法描述是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 -
希尔排序(Shell Sort)
1959年Shell发明,第一个突破O(n2)的排序算法,是简单插入排序的改进版。它与插入排序的不同之处在于,它会优先比较距离较远的元素。希尔排序又叫缩小增量排序。 -
归并排序(Merge Sort)
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。 -
快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。 -
堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。 -
计数排序(Counting Sort)
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。 -
桶排序(Bucket Sort)
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。 -
基数排序(Radix Sort)
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前
2. 请写一个方法判断一个整数是奇数还是偶数。
常规答案
- 与2取余,若为0则是偶数,否则为奇数。
public static bool IsEven(int number)
{
return ((number % 2) == 0);
}
进阶答案
- 检测数字的二进制最低位是否为0。将最低位和1相与,如果结果为0,则为偶数,否则为奇数。
如奇数3和1位与,实际上是
00000000 00000000 00000000 00000011
& 00000000 00000000 00000000 00000001
---------------------------------------------
00000000 00000000 00000000 00000001
再比如偶数6和1位与,实际上是
00000000 00000000 00000000 00000110
& 00000000 00000000 00000000 00000001
---------------------------------------------
00000000 00000000 00000000 00000000
判断一个整数是奇数还是偶数
/** <summary>
/// 判断一个整数是否是偶数
/// </summary>
/// <param name="number">传入的整数</param>
/// <returns>如果是偶数,返回true,否则为false</returns>
public static bool IsEven(int number)
{
return ((number & 1) == 0);
}
/** <summary>
/// 判断一个整数是否是奇数
/// </summary>
/// <param name="number">传入的整数</param>
/// <returns>如果是奇数,返回true,否则为false</returns>
public static bool IsOdd(int number)
{
return !IsEven(number);
}
3. 请写一个方法判断一个整数是否是2的n次方。
常规答案
- 利用位运算进行判断,将一个数通过不断位右移,最终结果若为1则为true,否则为false。
判断一个整数是否是2的n次方
public static bool IsPower(int number)
{
if (number <= 0)
{
return false;
}
while (true)
{
if (number == 1)
{
return true;
}
//如果是奇数
if ((number & 1) == 1)
{
return false;
}
//右移一位
number >>= 1;
}
}
进阶答案
- 2的n次方其二进制表示只有1个1,如整数8,其二进制表示形式是00001000,减去1后为00000111,让这两者进行位与的结果刚好是0则为true,否则就是falsez。
判断一个整数是否是2的n次方
public static bool IsPower(int number)
{
if (number <= 0)
{
return false;
}
if ((number & (number - 1)) == 0)
{
return true;
}
return false;
}
4. 对字节变量,其二进制表示法中求有多少个1,如 00101010则返回值为 3,也是要求效率最高。
private static int GetCountGroupByOne(int data)
{
int count = 0;
if (data == 0)
{
}
else if (data > 0)
{
while (data > 0)
{
data &= (data - 1);
count++;
}
}
else
{
int minValue = -0x40000001;
while (data > minValue)
{
data &= (data - 1);
count++;
}
count++;
}
return count;
}
5. 100万的数据选出前1万大的数
-
利用堆排序、小顶堆实现。
-
先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O (nmlogm)(n为100,m为10000)。
-
优化的方法:分治。可以把所有10亿个数据分组存放,比如分别放在1000个文件中。这样处理就可以分别在每个文件的10^6个数据中找出最大的10000个数,合并到一起在再找出1000*10000中的最终的结果。
6. 二分查找
-
算法思路:假设目标值在闭区间[l, r]中,每次将区间长度缩小一半,当l = r时,我们就找到了目标值。
- 当我们将区间[l, r]划分成[l, mid]和[mid + 1, r]时,其更新操作是r = mid或者l = mid + 1;,计算mid时不需要加1。(常用)
int bsearch_1(int 1, int r)
{
While (l <r)
{
int mid = l +r >> 1;
if(check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
- 当我们将区间[l, r]划分成[l, mid – 1]和[mid, r]时,其更新操作是r = mid – 1或者l = mid;,此时为了防止死循环,计算mid时需要加1。
int bsearch_2(int 1, int r)
{
While (l <r)
{
int mid = l + r +1 >> 1;
if(check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
- 代码里的if语句,若变成一个bool函数带入对应的l,r,mid,array等,在函数里面继续二分查找,即可变成“二分答案”。
7. BFS(广度优先搜索)
- BFS从根节点开始搜索,并根据树级别模式探索所有邻居根。它使用队列数据结构来记住下一个节点访问。
1.如果不需要确定当前遍历到了哪一层
while queue 不空:
cur = queue.pop()
for 节点 in cur的所有相邻节点:
if 该节点有效且未访问过:
queue.push(该节点)
2.如果要确定当前遍历到了哪一层,BFS 模板如下。 这里增加了 level 表示当前遍历到二叉树中的哪一层了,也可以理解为在一个图中,现在已经走了多少步了。size 表示在当前遍历层有多少个元素,也就是队列中的元素数,我们把这些元素一次性遍历完,即把当前层的所有元素都向外走了一步。
level = 0
while queue 不空:
size = queue.size()
while (size --)
{
cur = queue.pop()
for 节点 in cur的所有相邻节点:
if 该节点有效且未访问过:
queue.push(该节点)
}
level++;
8. DFS(深度优先搜索)
-
注意搜索的顺序;当搜到叶子节点(递归结束)时就回溯,回退一步看一步。
-
DFS从根节点开始搜索,并从根节点尽可能远地探索这些节点。使用堆栈数据结构来记住下一个节点访问。
-
类似于树的 先序遍历
-

9. 请写出求斐波那契数列任意一位的值的算法
static int Fn(int n) {
if (n <= 0) {
throw new ArgumentOutOfRangeException();
}
if (n == 1||n==2)
{
return 1;
}
return checked(Fn(n - 1) + Fn(n - 2)); // when n>46 memory will overflow
}
10. 下列代码在运行中会产生几个临时对象?
string a = new string("abc");
a = (a.ToUpper() +"123").Substring(0,2);
- 实在C#中第⼀⾏是会出错的(Java中倒是可⾏)。
应该这样初始化:
string b = new string(new char[] {'a','b','c'});
- 三个临时对象:abc、ABC、AB
11. 怎么判断一个点是否在直线上?
-
已知点P(x,y),以及直线上的两点A(x1,y1)、B(x2,y2),可以通过计算向量AP与向量AB的叉乘是否等于0来计算点P是否在直线AB上。
-
知识点:叉乘
/// <summary>
/// 2D叉乘
/// </summary>
/// <param name="v1">点1</param>
/// <param name="v2">点2</param>
/// <returns></returns>
public static float CrossProduct2D(Vector2 v1,Vector2 v2)
{
//叉乘运算公式 x1*y2 - x2*y1
return v1.x * v2.y - v2.x * v1.y;
}
/// <summary>
/// 点是否在直线上
/// </summary>
/// <param name="point"></param>
/// <param name="lineStart"></param>
/// <param name="lineEnd"></param>
/// <returns></returns>
public static bool IsPointOnLine(Vector2 point, Vector2 lineStart, Vector2 lineEnd)
{
float value = CrossProduct2D(point - lineStart, lineEnd - lineStart);
return Mathf.Abs(value) <0.0003 /* 使用 Mathf.Approximately(value,0) 方式,在斜线上好像无法趋近为0*/;
}
12. 判断点是否在线段上?
-
已知点P(x,y),以及线段A(x1,y1),B(x2,y2)。
-
方法一
可以进行下面两部来判断点P是否在线段AB上:- 点是否在线段AB所在的直线上(点是否在直线上)
- 点是否在以线段AB为对角线的矩形上,来忽略点在线段AB延长线上
/// <summary>
/// 2D叉乘
/// </summary>
/// <param name="v1">点1</param>
/// <param name="v2">点2</param>
/// <returns></returns>
public static float CrossProduct2D(Vector2 v1,Vector2 v2)
{
//叉乘运算公式 x1*y2 - x2*y1
return v1.x * v2.y - v2.x * v1.y;
}
/// <summary>
/// 点是否在直线上
/// </summary>
/// <param name="point"></param>
/// <param name="lineStart"></param>
/// <param name="lineEnd"></param>
/// <returns></returns>
public static bool IsPointOnLine(Vector2 point, Vector2 lineStart, Vector2 lineEnd)
{
float value = CrossProduct2D(point - lineStart, lineEnd - lineStart);
return Mathf.Abs(value) <0.0003 /* 使用 Mathf.Approximately(value,0) 方式,在斜线上好像无法趋近为0*/;
}
/// <summary>
/// 点是否在线段上
/// </summary>
/// <param name="point"></param>
/// <param name="lineStart"></param>
/// <param name="lineEnd"></param>
/// <returns></returns>
public static bool IsPointOnSegment(Vector2 point, Vector2 lineStart, Vector2 lineEnd)
{
//1.先通过向量的叉乘确定点是否在直线上
//2.在拍段点是否在指定线段的矩形范围内
if (IsPointOnLine(point,lineStart,lineEnd))
{
//点的x值大于最小,小于最大x值 以及y值大于最小,小于最大
if (point.x >= Mathf.Min(lineStart.x, lineEnd.x) && point.x <= Mathf.Max(lineStart.x, lineEnd.x) &&
point.y >= Mathf.Min(lineStart.y, lineEnd.y) && point.y <= Mathf.Max(lineStart.y, lineEnd.y))
return true;
}
return false;
}
13. 解决哈希冲突的方法
- 开放定址法:冲突位置向后移动一个单位,直到不发生冲突。
- 平方探测法:按照+1,-1,+2²,-2²,+3²…顺序查找
- 再哈希法:对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
- 拉链法
14. 常用的hash算法
- 加法Hash,就是把输入元素一个一个的加起来构成最后的结果
- 位运算Hash,这类型Hash函数通过利用各种位运算(常见的是移位和异或)来充分的混合输入元素
- 乘法Hash,这种类型的Hash函数利用了乘法的不相关性
- 混合Hash,混合以上方式
15. 逆矩阵的作用
- 当我们将一个向量经过旋转或其他的变换后,如果想撤销这个变换,就乘以变换矩阵的逆矩阵。
16. 数组和 List 的区别
- 在C#中,数组(Array)和列表(List)都是常用的集合类型,它们各自有不同的使用场景和特性。下面是它们之间的一些主要区别:
- 固定大小 vs 可变大小:数组的大小是固定的,一旦创建,其大小就无法更改。而列表的大小是可变的,可以随时添加或删除元素。
- 声明方式:数组在声明时需要指定大小,而列表在声明时不需要指定大小
// 数组
int[] array = new int[5]; // 声明一个可以容纳5个整数的数组
// 列表
List<int> list = new List<int>(); // 声明一个整数列表
- 索引方式:数组使用基于零的索引,即第一个元素的索引为0。而列表使用基于零的索引,但因为列表的大小可变,所以它的实际索引可能不是连续的。
- 性能:对于随机访问元素,数组通常比列表更快,因为数组的访问是常数时间复杂度O(1)。对于列表,访问特定索引的元素需要线性时间复杂度O(n)。但是,对于列表的插入和删除操作,列表通常更快,因为数组需要重新分配和复制来改变大小。
- 类型安全:两者都是类型安全的。这意味着你只能向列表添加指定类型的元素,不能添加其他类型的元素。
- 内存管理:由于数组的大小是固定的,因此一旦分配了内存,即使你不再需要数组中的某些元素,这些内存也不会被释放。而列表则可以自动管理内存,当元素被删除时,相关的内存会被自动释放。
- 范围检查:对于数组,如果尝试访问超出其范围的索引,将会抛出异常。而对于列表,如果尝试访问超出当前范围的索引,将会抛出异常。但是,如果你使用
List<T>.Add添加元素超出当前容量时,会自动分配新的容量并复制元素。 - 易用性:在很多情况下,由于列表提供了更多的功能(如自动增长、遍历、查找等),它们比数组更易于使用。
- 总的来说,你应该根据你的具体需求来选择使用数组还是列表。如果你需要一个大小固定的、类型安全的集合,并且对性能有严格要求,那么数组可能是更好的选择。如果你需要一个可以动态增长和缩小的集合,或者需要频繁地添加、删除元素,那么列表可能是更好的选择。
17. 数据结构中数组和链表各有什么特点,什么场合下应该使用数组,什么 场合下应该使用链表
- 数组必须事先定义固定的长度(元素个数),不能适应数据动态地增减的情况。当数据增加时,可能超出原先定义的元素个数;当数据减少时,造成内存浪费;数组可以根据下标直接存取。
- 链表动态地进行存储分配,可以适应数据动态地增减的情况,且可以方便地插入、删除数据项。(数组中插入、删除数据项时,需要移动其它数据项,非常繁琐)链表必须根据 next 指针找到下一个元素从内存存储来看1. (静态)数组从栈中分配空间, 对于程序员方便快速,但是自由度小
- 链表从堆中分配空间, 自由度大但是申请管理比较麻烦。从上面的比较可以看出,如果需要快速访问数据,很少或不插入和删除元素,就应该用数组;相反,如果需要经常插入和删除元素就需要用链表数据结构了。
18. 请简要介绍Unity中常用数据结构
- 数组(Array):数组是一种线性数据结构,元素在内存中是连续存放的。数组的元素类型必须相同,可以通过下标直接访问元素。数组的查找速度非常快,但新增和删除速度慢。
- ArrayList:ArrayList是为了解决数组创建时必须指定长度以及只能存放相同类型的缺点而推出的数据结构。ArrayList无需指定长度,会根据存储的数据动态地增加或减少长度。但所有元素都被当做Object处理,可以存储不同数据类型的元素。
- List:List是为了解决ArrayList不安全类型与装箱拆箱的缺点而推出的数据结构。List融合了Array可以快速访问的优点以及ArrayList长度可以灵活变化的优点。
- LinkedList:LinkedList是一种双向链表,其存储的元素在内存中可能不连续。访问LinkedList中的元素时,不能直接使用下标,而需要从头结点开始,逐个遍历下一个节点,直到找到目标。
- Queue:Queue是一种先进先出的线性表,只能在一端进行插入,在另一端进行删除。
- Stack:Stack是一种后进先出的线性表,只允许在表的一端进行增删操作。
- Dictionary:Dictionary是一种键值对的数据结构,可以通过键来快速查找和访问值。在Unity中,Dictionary通常用于存储游戏对象之间的关联关系。
19. Unity中常见的碰撞算法
-
在Unity中,处理碰撞检测主要依赖于内置的物理引擎,它使用了一系列的算法来检测和处理物体之间的碰撞。Unity的碰撞检测主要基于边界盒(Bounding Boxes)或边界球(Bounding Spheres)的初步检测,随后是更精确的碰撞形状检测。以下是Unity中常见的碰撞检测相关概念和技术:
-
边界盒碰撞检测(Axis-Aligned Bounding Box, AABB):
- AABB是最简单的碰撞检测形状,它是一个与坐标轴对齐的矩形盒子,包裹着物体的最大范围。
- Unity中的每个Collider组件都有一个AABB,用于快速排除不会发生碰撞的物体。
-
. 边界球碰撞检测(Bounding Sphere):
- 边界球是一个包围物体的最小球体。
- 虽然不如AABB精确,但边界球计算简单,适用于快速筛选可能发生碰撞的物体。
-
网格碰撞器(Mesh Collider):
- 对于复杂形状的物体,可以使用网格碰撞器,它基于物体的实际三角形网格进行碰撞检测。
- 网格碰撞器提供了更精确的碰撞检测,但性能开销较大。
-
凸包碰撞器(Convex Hull Collider):
- 凸包碰撞器是基于物体形状的凸包进行碰撞检测的。
- 它比网格碰撞器性能更好,但可能不如网格碰撞器精确。
-
简单碰撞器(Primitive Colliders):
- Unity提供了多种简单形状的碰撞器,如盒子碰撞器(Box Collider)、球体碰撞器(Sphere Collider)、胶囊碰撞器(Capsule Collider)等。
- 这些碰撞器适用于简单的物体形状,性能开销小。
-
. 碰撞检测阶段:
-
. 碰撞事件:
- Unity提供了多种碰撞事件,如
OnCollisionEnter、OnCollisionStay和OnCollisionExit,用于处理碰撞发生、持续和结束时的情况。
- Unity提供了多种碰撞事件,如
-
触发器(Triggers):
- 触发器是Unity中一种特殊的碰撞器,它不会引起物理反应,但可以用于检测物体何时进入或离开其区域。
- 触发器事件包括
OnTriggerEnter、OnTriggerStay和OnTriggerExit。
-
20. Unity中常见的路径搜索算法
- Dijkstra算法:Dijkstra算法是一种用于在图中查找最短路径的算法。它从起点开始,逐步扩展到相邻节点,直到找到目标节点。Dijkstra算法适用于网格地图或具有规则格子的环境。
- A*寻路算法:A算法是一种广泛使用的路径搜索算法,它结合了最佳优先搜索和Dijkstra算法的特性。A算法使用启发式函数来估计从当前节点到目标的代价,从而优先选择代价最小的节点。A*算法适用于大多数搜索场景,尤其适用于不规则地形或障碍物较多的环境。
- 广度优先搜索(BFS):BFS是一种从根节点开始,逐层遍历图的算法。它适用于那些不需要考虑路径长度的问题,例如确定两个节点之间是否存在路径。BFS通常用于搜索大范围的环境,但可能不是最短路径的解决方案。
- 深度优先搜索(DFS):DFS是一种深入搜索图的算法,直到达到目标节点或无法再深入为止。然后回溯并继续搜索其他路径。DFS适用于较小的搜索空间和已知起始点和目标点的场景。
- 动态规划(Dynamic Programming):动态规划是一种通过将问题分解为子问题并存储子问题的解来避免重复计算的方法。它可以用于路径搜索问题中,通过存储和重用子问题的解来加速搜索过程。
21. Unity中常见的曲线插值算法
- 线性插值(Linear Interpolation):线性插值是最简单的插值方法,它通过连接两个已知点之间的直线段来估算中间的值。线性插值的公式为
(y2 - y1) * t + y1,其中t是从0到1之间的参数,表示当前位置与起点之间的相对位置。 - 贝塞尔曲线(Bezier Curves):贝塞尔曲线是一种参数曲线,用于在二维空间中绘制平滑的曲线。贝塞尔曲线通过一系列控制点来定义曲线的形状。根据控制点的数量,贝塞尔曲线可以分为一次、二次、三次等类型。Unity中提供了内置的贝塞尔曲线工具,可以方便地创建和操作贝塞尔曲线。
- 样条曲线(Spline Curves):样条曲线是另一种参数曲线,它通过一系列的样条段来连接已知点。样条曲线在处理复杂曲线时比贝塞尔曲线更加灵活和逼真。Unity中也提供了样条曲线的工具,可以用于创建和编辑样条曲线。
- 插值函数(Interpolation Functions):Unity还提供了一些内置的插值函数,用于在动画和过渡效果中平滑地改变数值。例如,
Lerp函数用于线性插值,SmoothDamp函数用于平滑地减小或增大数值,而SmoothFollow函数则用于使一个对象平滑地跟随另一个对象。 - 这些曲线插值算法在Unity中广泛应用于动画、图形渲染、物理模拟和路径规划等领域。通过选择适当的插值方法,可以创建平滑、自然和逼真的效果。
22. 请解释Unity中的递归算法的性能问题,以及如何避免性能问题?
-
递归算法在Unity中可能会带来性能问题,主要原因在于递归算法需要大量的堆栈空间来存储每一层的函数调用,这可能会导致堆栈溢出。此外,如果递归算法没有正确地被优化,它可能会在处理大量数据时消耗大量的计算资源,从而导致性能问题。
- 使用循环代替递归:如果可能,尝试使用循环代替递归。循环在处理大量数据时通常比递归更高效。
- 优化递归:尽可能减少递归的深度,避免在每次递归中执行不必要的计算。同时,如果可能,将递归转化为迭代算法。
- 使用尾递归:在某些情况下,使用尾递归可以减少堆栈空间的使用。尾递归是指递归调用是函数体中最后一个操作的情况。
- 使用缓存:对于某些递归问题,可以将已经计算过的结果存储起来,以便在需要时可以快速访问。
- 使用栈帧优化:在某些情况下,可以通过优化栈帧来减少堆栈空间的使用。例如,可以尽可能地减少每个栈帧中的变量数量。
- 注意数据结构的选择:选择适合问题的数据结构可以减少递归的次数和深度。例如,对于搜索问题,使用二叉搜索树或哈希表等数据结构可以有效地减少递归的深度。
23. 简要介绍Unity中的常用的随机化算法?
- 在Unity中,常用的随机化算法主要有伪随机数生成器和基于随机函数的算法。伪随机数生成器可以用于模拟随机数的生成过程,而随机函数则提供了各种用于生成不同类型随机数的工具。这些函数包括但不限于Random.Range、Random.value、Random.insideUnitCircle等,可以生成指定范围内的随机整数、浮点数,以及在单位圆内的随机二维向量等。
- 此外,还可以使用RandomSeed来设置随机种子,以便在相同的种子下生成相同的随机数序列,这在需要复现某个特定的随机数序列时非常有用。
24. 简要介绍Unity中常用的光照算法?
- Phong光照模型:Phong光照模型是一种常用的表面光照模型,它考虑了环境光、漫反射光和镜面高光三个部分。漫反射光照指光线在物体表面均匀散射的成分,它与视角和表面法线之间的角度有关;镜面高光指光线在物体表面反射的成分,它与表面法线和光源方向之间的角度有关。
- Blinn-Phong光照模型:Blinn-Phong光照模型是对Phong光照模型的一种改进,它在计算镜面高光时使用了半角向量,从而减少了高光反射的计算量。Blinn-Phong光照模型也考虑了高光反射的饱和度,使得高光效果更加自然。
- 各向异性高光:各向异性高光是一种模拟非金属表面反射特性的技术,它可以用来模拟金属和非金属表面的高光效果。各向异性高光的原理是,对于非金属表面,高光反射的方向与表面法线方向有关,而与视角方向无关。因此,可以通过调整高光反射的方向来模拟非金属表面的高光效果。
- 逐顶点计算光照:在某些情况下,为了提高计算效率,可以使用逐顶点计算光照的方式来进行光照计算。逐顶点计算光照的方式是将顶点所在的面片上的光照值传递给顶点,然后通过插值的方式将面片上的光照值传递给像素。这种计算方式可以减少光照的计算量,但可能会带来一定的精度损失。
- 延迟渲染:延迟渲染是一种用于实现复杂光照效果的渲染技术。它将场景中的光照分为环境光、漫反射光和镜面高光三个部分,并将它们分别存储在不同的缓冲区中。然后,在每个像素的渲染过程中,延迟渲染会根据场景中的几何体信息、材质属性和光源位置等计算出每个像素点的光照效果。延迟渲染可以提高渲染效率,但需要更多的内存和计算资源。
原文地址:https://blog.csdn.net/backlighting2015/article/details/135427642
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_58946.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!