前面介绍过,KafkaProducer可以有同步和异步两种方式发送消息,其实两者的底层实现相同,都是通过异步方式实现的。
主线程调用KafkaProducer.send方法发送消息的时候,先将消息放到RecordAccumulator中暂存,然后主线程就可以从send方法中返回了,此时消息并没有真正地发送给Kafka,而是缓存在了RecordAccumulator中。
之后,业务线程通过KafkaProducer.send()方法不断向RecordAccumulator追加消息,当达到一定的条件,会唤醒Sender线程发送RecordAccumulator中的消息。
下面我们就来介绍RecordAccumulator的结构。
首先需要注意的是,RecordAccumulator至少有一个业务线程和一个Sender线程并发操作,所以必须是线程安全的。
RecordAccumulator中有一个以TopicPartition为key的ConcurrentMap,每个value是ArrayDeque(ArrayDeque并不是线程安全的集合),其中缓存了发往对应TopicPartition的消息。
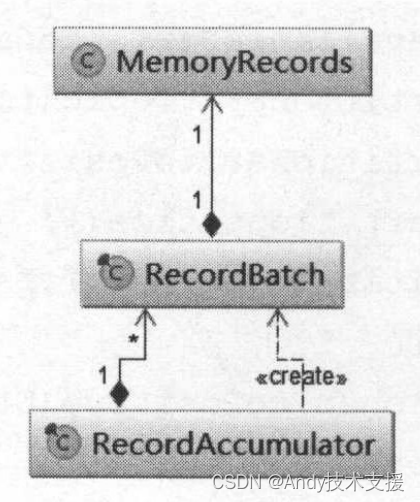
每个RecordBatch拥有一个MemoryRecords对象的引用。
MemoryRecords才是消息最终存放的地方。
这三个类的依赖关系如图所示。
MemoryRecords
大体了解了RecordAccumulator的结构之后,我们就从最底层的MemoryRecords开始分析。
MemoryRecords表示的是多个消息的集合,其中封装了Java NIO ByteBuffer用来保存消息数据,Compressor用于对ByteBuffer中的消息进行压缩,以及其他控制字段。

如图(左)所示,有四个字段比较重要,简单介绍一下。
- buffer:用于保存消息数据的Java NIO ByteBuffer。
- writeLimit:记录buffer字段最多可以写入多少个字节的数据。
- compressor:压缩器,对消息数据进行压缩,将压缩后的数据输出到buffer。
- writable:此MemoryRecords对象是只读的模式,还是可写模式。在MemoryRecords发送前时,会将其设置成只读模式。
在Compressor比较重要的字段和方法如图(右)所示,有两个输出流类型的字段,分别是bufferStream和appendStream。
前者是在buffer上建立的ByteBufferOutputStream(Kafka自己提供的实现)对象,ByteBufferOutputStream继承了java.io.OutputStream,封装了ByteBuffer,当写入数据超出ByteBuffer容量时,ByteBufferOutputStream会进行自动扩容;后者是DataOutputStream类型,它对前者进行了一层装饰,为其添加了压缩的功能。
MemoryRecords中的Compressor的压缩类型是由“compression.type”配置参数指定的,即KafkaProducer.compressionType字段的值。
下面来分析一下创建压缩流的方式,目前KafkaProducer支持GZIP、SNAPPY、LZ4三种压缩方式。
Compressor提供了一系列put*()方法,向appendStream流写入数据,如图所示。很明显,这是装饰器模式的典型,通过bufferStream装饰,添加自动扩容的功能;通过appendStream装饰后,添加压缩功能。

了解了Compressor的实现逻辑之后,我们回到MemoryRecords继续分析。
MemoryRecords的构造方法是私有的,只能通过emptyRecords)方法得到其对象。
MemoryRecords中有四个比较重要的方法。
- append()方法:先判断MemoryRecords是否为可写模式,然后调用Compressor.put*()方法,将消息数据写入ByteBuffer中。
- hasRoomFor()方法:根据Compressor估算的已写字节数,估计MemoryRecords剩余空间是否足够写入指定的数据。注意,这里仅仅是估算,所以不一定准确,通过hasRoomFor()方法判断之后写入数据,也可能就会导致底层ByteBuffer出现扩容的情况。
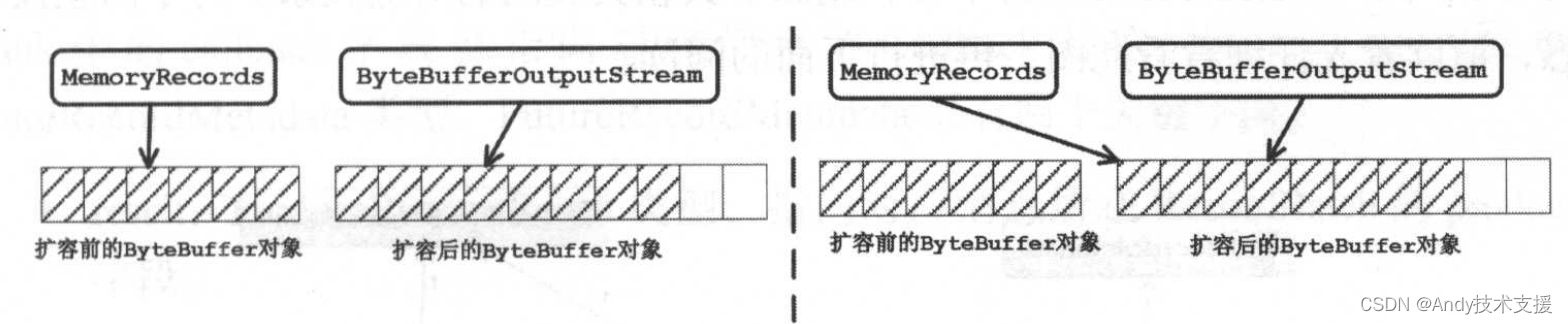
- close()方法:出现ByteBuffer扩容的情况时,MemoryRecords.buffer字段与ByteBufferOutputStream.buffer字段所指向的不再是同一个ByteBuffer对象,如图(左)所示。
- 在close()方法中,会将MemoryRecords.buffer字段指向扩容后的ByteBuffer对象,如图(右)所示。同时,将writable设置为false(即只读模式)。
- sizelnBytes()方法:对于可写的MemoryRecords,返回的是ByteBufferOutputStream.buffer字段的大小;对于只读MemoryRecords,返回的是MemoryRecords.buffer的大小。
RecordBatch
了解了MemoryRecords的具体实现之后,来分析RecordBatch类的实现。
每个RecordBatch对象中封装了一个MemoryRecords对象,除此之外,还封装了很多控制信息和统计信息,下面简单介绍一下。
- recordCount:记录了保存的Record的个数。
- maxRecordSize:最大Record的字节数。
- attempts:尝试发送当前RecordBatch的次数。
- lastAttemptMs:最后一次尝试发送的时间戳。
- records:指向用来存储数据的MemoryRecords对象。
- topicParition:当前RecordBatch中缓存的消息都会发送给此TopicPartition。
- produceFuture:ProduceRequestResult类型,标识RecordBatch状态的Future对象。
- lastAppendTime:最后一次向RecordBatch追加消息的时间戳。
- thunks:Thunk对象的集合,在后面会详细介绍。
- offsetCounter:用来记录某消息在RecordBatch中的偏移量。
- retry:是否正在重试。如果RecordBatch中的数据发送失败,则会重新尝试发送。
图中,以RecordBatch为中心,刻画了其相关类间的对应关系。
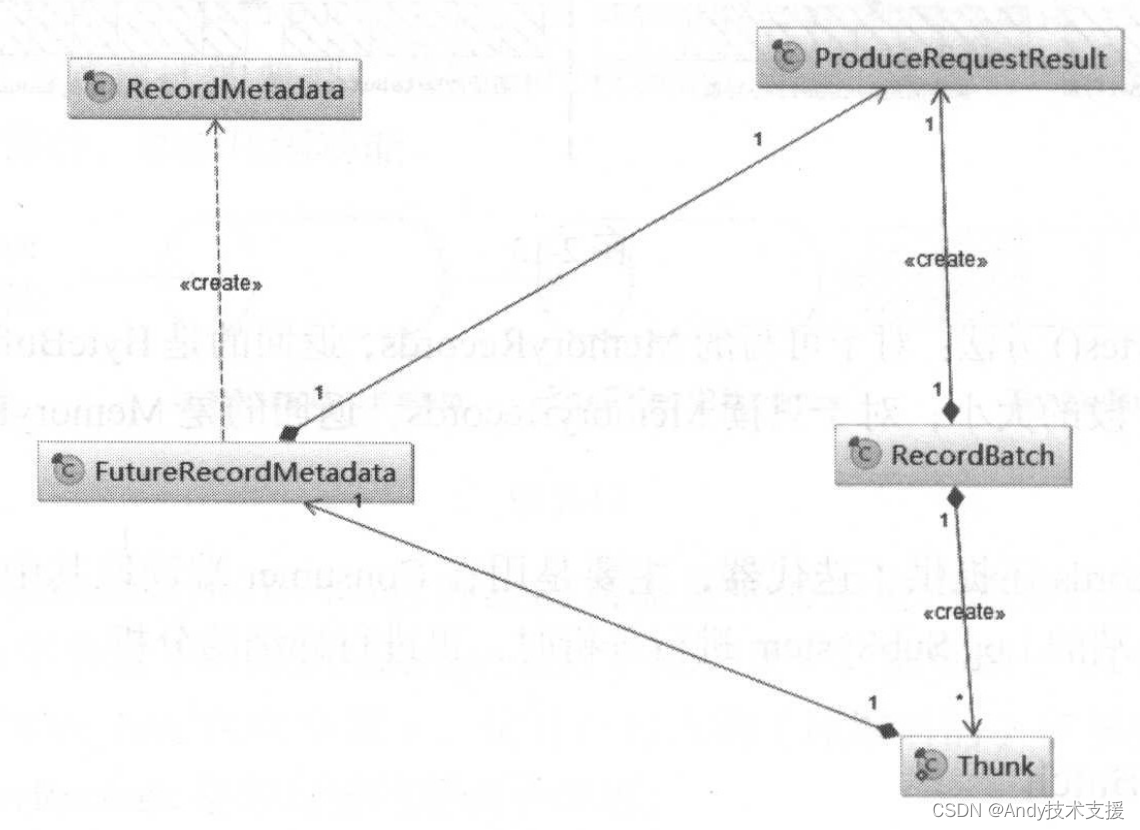
下面分析一下ProduceRequestResult这个类的功能。
ProduceRequestResult并未实现java.util.concurrent.Future接口,但是其通过包含一个count值为1的CountDownLatch对象,实现了类似于Future的功能(Future、CountDownLatch等工具的使用)。
当RecordBatch中全部的消息被正常响应、或超时、或关闭生产者时,会调用ProduceRequestResult.done方法,将produceFuture标记为完成并通过ProduceRequestResult.error字段区分“异常完成”还是“正常完成”,之后调用CountDownLatch对象的countDown方法。
此时,会唤醒阻塞在CountDownLatch对象的await方法的线程(这些线程通过ProduceRequestResult的await方法等待上述三个事件的发生)。
分区会为其中记录的消息分配一个offset并通过此offset维护消息顺序。
在ProduceRequestResult中还有一个需要注意的字段baseOffset,表示的是服务端为此RecordBatch中第一条消息分配的offset,这样每个消息可以根据此offset以及自身在此RecordBatch中的相对偏移量,计算出其在服务端分区中的偏移量了。
在介绍Tunk类之前,请回顾KafkaProducer.send方法的第二个参数,是一个Callback对象,它是针对单个消息的回调函数(每个消息都会有一个对应的Callback对象作为回调)。
RecordBatch.thunks字段可以理解为消息的回调对象队列,Thunk中的callback字段就指向对应消息的Callback对象,其另一个字段future是FutureRecordMetadata类型。
FutureRecordMetadata类有两个关键字段。
- result:ProduceRequestResult类型,指向对应消息所在RecordBatch的produceFuture字段。
- relativeOffset:long类型,记录了对应消息在RecordBatch中的偏移量。
FutureRecordMetadata实现了java.util.concurrent.Future接口,但其实现基本都是委托给了ProduceRequestResult对应的方法,由此可以看出,消息应该是按照RecordBatch进行发送和确认的。
当生产者已经收到某消息的响应时,FutureRecordMetadata.get方法就会返回RecordMetadata对象,其中包含消息在Partition中的offset等其他元数据,可供用户自定义Callback使用。
分析完RecordBatch依赖的组件,现在回来看看RecordBatch类的核心方法。tryAppend方法是最核心的方法,其功能是尝试将消息添加到当前的RecordBatch中缓存。

当RecordBatch成功收到正常响应、或超时、或关闭生产者时,都会调用RecordBatch的done()方法。
在done()方法中,会回调RecordBatch中全部消息的Callback回调,并调用其produceFuture字段的done()方法。RecordBatch.done()方法的调用关系如图所示。

RufferPool
ByteBuffer的创建和释放是比较消耗资源的,为了实现内存的高效利用,基本上每个成熟的框架或工具都有一套内存管理机制。
Kafka客户端使用BufferPool来实现ByteBuffer的复用。
图展示了BufferPool的核心字段。

首先需要了解的是,每个BufferPool对象只针对特定大小(由poolableSize字段指定)的ByteBuffer进行管理,对于其他大小的ByteBuffer并不会缓存进BufferPool。
一般情况下,我们会调整MemoryRecords的大小(RecordAccumulator.batchSize字段指定),使每个MemoryRecords可以缓存多条消息。
但也有例外情况,当一条消息的字节数大于MemoryRecords时,就不会复用BufferPool中缓存的ByteBuffer,而是额外分配ByteBuffer,在它被使用完后也不会放入BufferPool进行管理,而是直接丢弃由GC回收。
如果经常出现这种例外情况,就需要考虑调整batchSize的配置了。
下面介绍BufferPool的关键字段:
- free:是一个ArayDeque队列,其中缓存了指定大小的ByteBuffer对象。
- ReentrantLock:因为有多线程并发分配和回收ByteBuffer,所以使用锁控制并发,保证线程安全。
- waiters:记录因申请不到足够空间而阻塞的线程,此队列中实际记录的是阻塞线程对应的Condition对象。
- totalMemory:记录了整个Pool的大小。
- availableMemory:记录了可用的空间大小,这个空间是totalMemory减去free列表中全部ByteBuffer的大小。
BufferPool.allocate()方法负责从缓冲池中申请ByteBuffer,当缓冲池中空间不足时,就会阻塞调用线程。
下面简单分析一下allocate()方法申请空间的过程:

继续分析deallocate()方法的实现:

RecordAccumulator
介绍完了MemoryRecord、RecordBatch以及BufferPool的工作机制,再来看RecordAccumulator的实现就比较简单了。
下面来看RecordAccumulator中的关键字段和方法,如图所示。

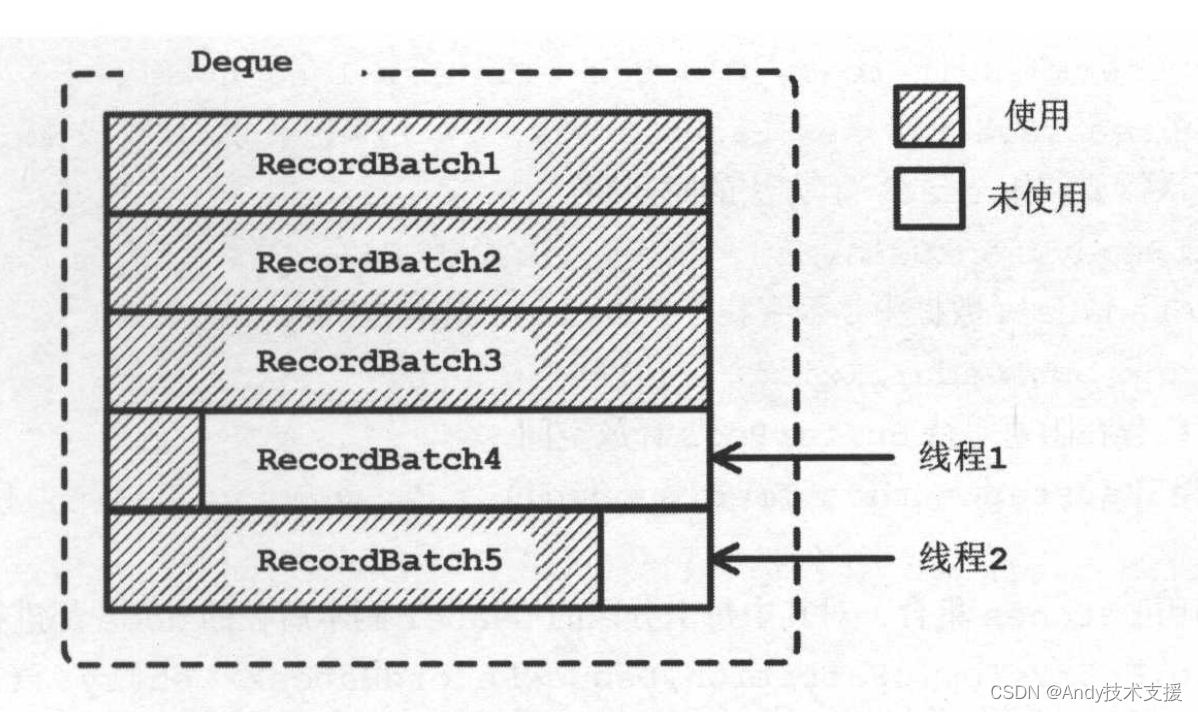
- batches:TopicPartition与RecordBatch集合的映射关系,类型是CopyOnWriteMap,是线程安全的集合,但其中的Deque是ArayDeque类型,是非线程安全的集合。在后面的介绍中可以看到,追加新消息或发送RecordBatch的时候,需要加锁同步。
每个Deque中都保存了发往对应TopicPartition的RecordBatch集合。
- batchSize:指定每个RecordBatch底层ByteBuffer的大小。
- Compression:压缩类型,参考MemoryRecords。
- incomplete:未发送完成的RecordBatch集合,底层通过Set集合实现。
- free:BufferPool对象,参考BufferPool。
- drainlndex:使用drain方法批量导出RecordBatch时,为了防止饥饿,使用drainIndex记录上次发送停止时的位置,下次继续从此位置开始发送。
KafkaProducer.send方法最终会调用RecordAccumulator.append方法将消息追加到RecordAccumulator中,其代码比较长,先来看其主要逻辑:
- 首先在batches集合中查找TopicPartition对应的Deque,查找不到,则创建新的Deque,并添加到batches集合中。
- 对Deque加锁(使用synchronized关键字加锁)。
- 调用tryAppendO方法,尝试向Deque中最后一个RecordBatch追加Record。
- synchronized块结束,自动解锁。
- 追加成功,则返回RecordAppendResult(其中封装了ProduceRequestResult)。
- 追加失败,则尝试从BufferPool中申请新的ByteBuffer。
- 对Deque加锁(使用synchronized关键字加锁),再次尝试第3步。
- 追加成功,则返回;失败,则使用第5步得到的ByteBuffer创建RecordBatch。
- 将Record追加到新建的RecordBatch中,并将新建的RecordBatch追加到对应的Deque尾部。
- 将新建的RecordBatch追加到incomplete集合。
- synchronized块结束,自动解锁。
- 返回RecordAppendResult,RecordAppendResult会中的字段会作为唤醒Sender线程的条件。
下面是RecordAccumulator.append方法的具体实现:

 现在回到KafkaProducer.doSend方法,doSend方法的最后一步就是判断此次向RecordAccumulator中追加消息后是否满足唤醒Sender线程条件,这里唤醒Sender线程的条件是消息所在队列的最后一个RecordBatch满了或此队列中不止一个RecordBatch。
现在回到KafkaProducer.doSend方法,doSend方法的最后一步就是判断此次向RecordAccumulator中追加消息后是否满足唤醒Sender线程条件,这里唤醒Sender线程的条件是消息所在队列的最后一个RecordBatch满了或此队列中不止一个RecordBatch。
在客户端将消息发送给服务端之前,会调用RecordAccumulator.ready方法获取集群中符合发送消息条件的节点集合。
这些条件是站在RecordAccumulator的角度对集群中的Node进行筛选的,具体的条件如下:
- Deque中有多个RecordBatch或是第一个RecordBatch是否满了。
- 是否超时了。
- 是否有其他线程在等待BufferPool释放空间(即BufferPool的空间耗尽了)。
- 是否有线程正在等待flush操作完成。
- Sender线程准备关闭。
下面来看一下ready方法的代码,它会遍历batches集合中每个分区,首先查找当前分区Leader副本所在的Node,如果满足上述五个条件,则将此Node信息记录到readyNodes集合中。
遍历完成后返回ReadyCheckResult对象,其中记录了满足发送条件的Node集合、在遍历过程中是否有找不到Leader副本的分区(也可以认为是Metadata中当前的元数据过时了)、下次调用ready方法进行检查的时间间隔。

调用RecordAccumulator.ready)方法得到readyNodes集合后,此集合还要经过NetworkClient的过滤(在介绍Sender线程的时候再详细介绍)之后,才能得到最终能够发送消息的Node集合。
RecordAccumulator.drain方法会根据上述Node集合获取要发送的消息,返回Map<Integer,List>集合,key是Nodeld,value是待发送的RecordBatch集合。
drain方法也是由Sender线程调用的。drain方法的核心逻辑是进行映射的转换:将RecordAccumulator记录的TopicPartition>RecordBatch集合的映射,转换成了Nodeld->RecordBatch集合的映射。
为什么需要这次转换呢?在网络I/O层面,生产者是面向Node节点发送消息数据,它只建立到Node的连接并发送数据,并不关心这些数据属于哪个TopicPartition;而在调用KafkaProducer的上层业务逻辑中,则是按照TopicPartition的方式产生数据,它只关心发送到哪个TopicPartition,并不关心这些TopicPartition在哪个Node节点上。
在下文介绍到Sender线程的时候会发现,它每次向每个Node节点至多发送一个ClientRequest请求,其中封装了追加到此Node节点上多个分区的消息,待请求到达服务端后,由Kafka对请求记性解析。
下面来看看drain方法的代码:

原文地址:https://blog.csdn.net/zhuyufan1986/article/details/135635205
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_59110.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!