What is AI
AI 目前是什么?
目前的人工智能(AI)是指使计算机和机器能够模仿人类智能的技术,包括学习、推理、解决问题、知觉、语言理解等能力。AI 可以在数据科学、机器学习、深度学习、自然语言处理等多个领域中找到应用。从智能助手、推荐系统到自动驾驶汽车和机器人,AI 正在改变我们的生活方式、工作方式,甚至思考方式。它代表了科技发展的前沿,正在逐渐成为现代社会的基石。
什么是思维链?
通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这一系列推理的中间步骤就被称为思维链(Chain of Thought)。
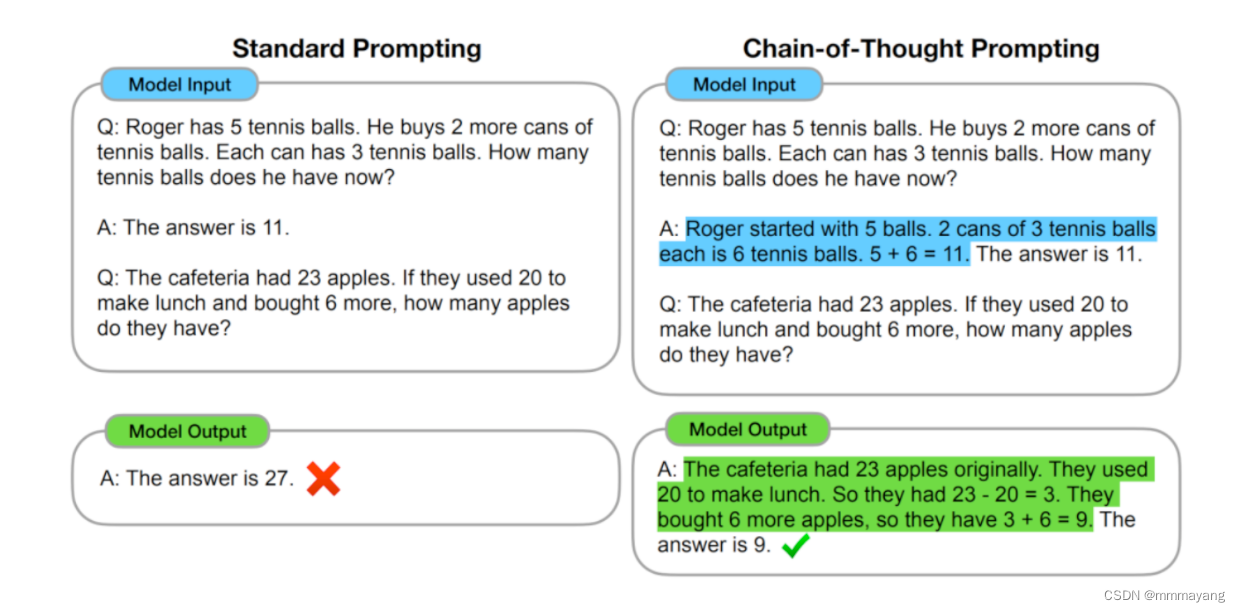
为什么要使用 CoT ?
自从 CoT 问世以来,CoT 的能力已经被无数工作所验证,如果对使用 CoT 的好处做一个总结,那么可以归纳为以下四点:
- 增强了大模型的推理能力:CoT 通过将复杂问题分解为多步骤的子问题,相当显著的增强了大模型的推理能力,也最大限度的降低了大模型忽视求解问题的“关键细节”的现象,使得计算资源总是被分配于求解问题的“核心步骤”;
- 增强了大模型的可解释性:对比向大模型输入一个问题大模型为我们仅仅输出一个答案,CoT 使得大模型通过向我们展示“做题过程”,使得我们可以更好的判断大模型在求解当前问题上究竟是如何工作的,同时“做题步骤”的输出,也为我们定位其中错误步骤提供了依据;
- 增强了大模型的可控性:通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成为无法控制的“完全黑盒”;
- 增强了大模型的灵活性:仅仅添加一句“Let’s think step by step”,就可以在现有的各种不同的大模型中使用 CoT 方法,同时,CoT 赋予的大模型一步一步思考的能力不仅仅局限于“语言智能”,在科学应用,以及 AI Agent 的构建之中都有用武之地。
为了更加直观的展现出 CoT 对大模型能力带来的提升,论文作者在七个不同的推理任务数据集中对 CoT 的效果进行了实验,如下图所示,可以看到,相较于直接 Prompt, CoT 对所有的推理任务都带来了显著的提升。
何时应该使用 CoT ?
关于何时应该使用 CoT 事实上还是一个开放问题,但是这篇论文从“工程”与“理论”两个角度为我们带来了一些 CoT 适用场景的洞见。
首先,从工程的角度而言,CoT 的适用场景抽象一下可以被归纳为三点,分别是使用大模型(1),任务需要复杂推理(2),参数量的增加无法使得模型性能显著提升(3)。此外,现有的论文实验也表明,CoT 更加适合复杂的推理任务,比如计算或编程,不太适用于简单的单项选择、序列标记等任务之中,并且 CoT 并不适用于那些参数量较小的模型(20B以下),在小模型中使用 CoT 非常有可能会造成机器幻觉等等问题。
为什么 CoT 会生效?
关于 CoT 为什么会生效,目前尚且没有一套被大家广泛接受的普遍理论。但是,有许多论文对 CoT 与大模型的互动进行了一系列实验,类似物理实验与物理理论的关系,在实验中一些有意思的现象或许可以帮助我们理解 CoT 的工作原理:
- 模型规模小会导致 CoT 失效;
- 简单的任务 CoT 不会对模型性能带来提升;
- 训练数据内部彼此相互联结程度的增加可以提升 CoT 的性能;
- 示例中的错误,或者无效的推理步骤不会导致 CoT 性能的下降;
如果我们对这些现象做一些总结与延申,或许可以认为:首先,CoT 需要大模型具备一些方面“最基础”的知识,如果模型过小则会导致大模型无法理解最基本的“原子知识”,从而也无从谈起进行推理;其次,使用 CoT 可以为一些它理解到的基础知识之间搭起一座桥梁,使得已知信息形成一条“链条”,从而使得大模型不会中途跑偏;最后,CoT 的作用,或许在于强迫模型进行推理,而非教会模型如何完成推理,大模型在完成预训练后就已经具备了推理能力,而 CoT 只是向模型指定了一种输出格式,规范模型让模型逐步生成答案。
CoT 与 AI Agent 有何关系?
回忆我们上一篇中介绍的关于 Agent 的定义,我们期望通过各种AI 技术构建的 Agent 事实上是一类拥有“自主智能的实体”,可以自主的发现问题、确定目标、构想方案、选择方案、执行方案、检查更新。基于大模型解决问题的“通用性”与预训练得到的“先天知识”,构建的大模型智能体可以被认为具有如下图的结构:
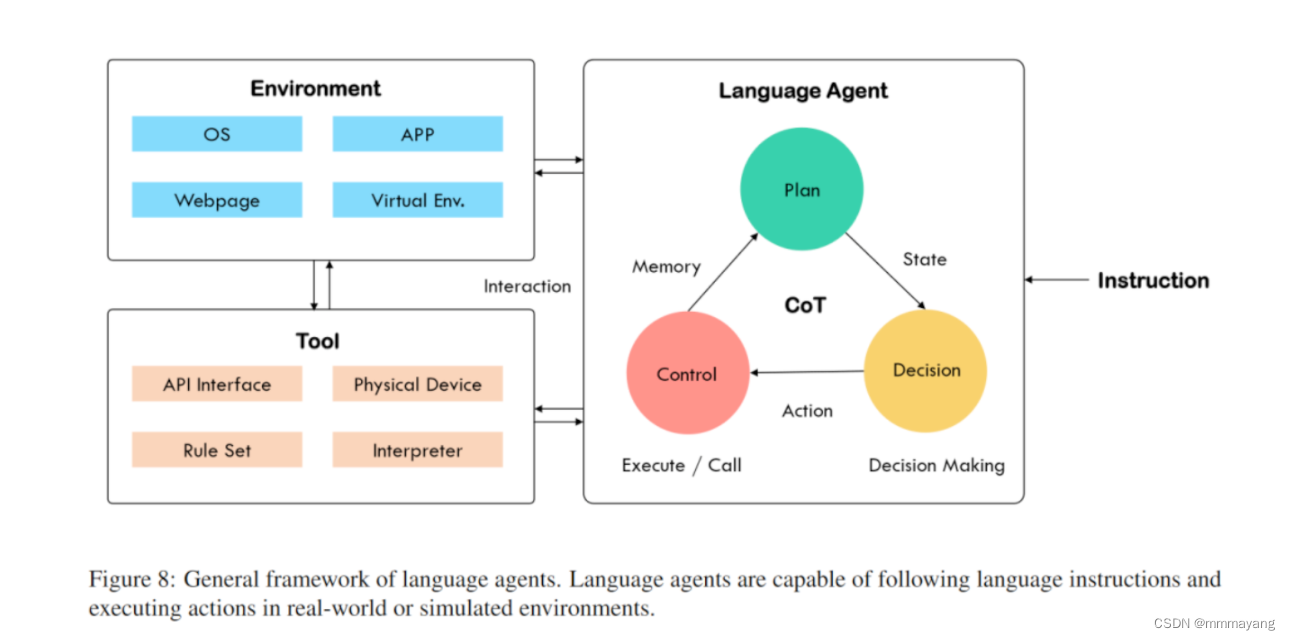
COT:这通常指的是“Chain of Thought”,或者称为“思维链”。在 AI 或机器学习领域,这可能指一种模型解决问题时的逻辑思考过程。简单地说,就像是 AI 在“思考”时的一步步推理过程。
Agent:在 AI 中,代理(Agent)通常指的是一个能够感知环境并作出决策的实体。就像是一个小机器人,它可以观察周围的世界,然后根据所见做出决定。
想象一下,如果你有一个智能机器人(Agent),它在解决问题时会像人一样思考和推理(COT),这样它就能更好地理解问题并找到解决方案。
什么是 AI Agents


GPT 与 ChatGPT 的差别?
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的大规模自然语言处理算法,用于生成文本。这种算法首先在大量文本数据上进行预训练,学习语言模式和知识,然后可以在特定任务上进行微调(fine-tuning),以提高在该任务上的表现。GPT的版本有多个,最新的是GPT-4。
ChatGPT是GPT的一个变体,专门针对生成对话式文本进行了优化。它使用了与GPT相同的基本技术,但在对话理解和生成上进行了特别的训练,以便更好地模仿人类的对话方式。ChatGPT能够回答问题、提供解释、解决问题等,就像一个人类在进行聊天时所做的那样。
从通用概念上讲,GPT是一个通用的文本生成模型,而ChatGPT是这个模型的一个特化应用,更专注于对话上下文。本质上,ChatGPT是GPT的一个特定实例,它被训练和优化以在对话环境中更好地工作。
那么 chatGPT 可以看作是一个用于对话的 agent 是吗?agent 在 AI 中的概念又是什么呢?
是的,ChatGPT可以被看作是一个用于对话的智能代理(agent)。
在人工智能中,代理(Agent)是一个广泛的概念,指的是能够观察环境并在该环境中采取行动以达成某种目标的实体。AI代理可以是简单的(如自动化的温度调节器),也可以是复杂的(如自动驾驶汽车或智能个人助理)。
一个AI代理通常具备以下特性:
1. 感知(Perception):
代理能够通过传感器或数据输入来感知其环境。对于ChatGPT来说,它的“感知”是通过接收用户输入的文本数据。
2. 行动(Action):
代理可以对其环境采取行动。在ChatGPT的案例中,行动是生成文本回复。
3. 自主性(Autonomy):
代理能够在没有外部干预的情况下自主地进行决策和行动。
4. 目标导向(Goal-oriented):
代理的行动旨在完成某些目标或任务。对于ChatGPT,目标可能是提供信息、解答问题或进行娱乐对话。
5. 适应性(Adaptability):
智能代理能够从经验中学习,并改进它们的行为以更好地实现其目标。
所以,ChatGPT作为一个AI代理,在与用户进行对话时,它会根据用户的输入(感知)生成响应(行动),并且尽可能地独立于外部控制地进行(自主性),旨在满足用户的需求或解决用户的问题(目标导向),同时通过用户的反馈和互动持续优化其性能(适应性)。
强化学习和机械学习的区别
- 强化学习:想象一下,你在玩一个视频游戏,你需要通过尝试来学习如何赢得游戏。每次你做出一个动作,游戏会告诉你这是好的(给你奖励)还是不好的(没有奖励或惩罚)。强化学习就像这样,它教会计算机通过尝试和错误来学习做事。比如,用它来训练机器人如何走路,或者用在游戏中,让计算机学会如何下棋。
- 机器学习:这就像你在学校里学习。你看很多书(数据),然后试着回答问题(做预测)。如果你回答正确,就意味着你学得不错。机器学习是让计算机通过查看很多数据来学习知识。比如,用机器学习来识别照片中的猫,或者根据过去的天气数据来预测明天会不会下雨。
- 强化学习:就像有反馈的指导,帮助你完成一个有明确目标的任务。通过不断尝试和从结果中学习(获得奖励或受到惩罚),你学会如何最好地达到这个目标。
- 机器学习:更像是通过查看大量数据获得某个领域的基本能力。它通过分析数据来找出模式或规律,然后使用这些知识来做出预测或决策。
引用
1、从 Cot 到 Agent,最全综述!
2、https://www.simplilearn.com/what-is-intelligent-agent-in-ai-types-function-article#what_is_an_agent_in_ai
原文地址:https://blog.csdn.net/weixin_43501634/article/details/134634347
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_5953.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





