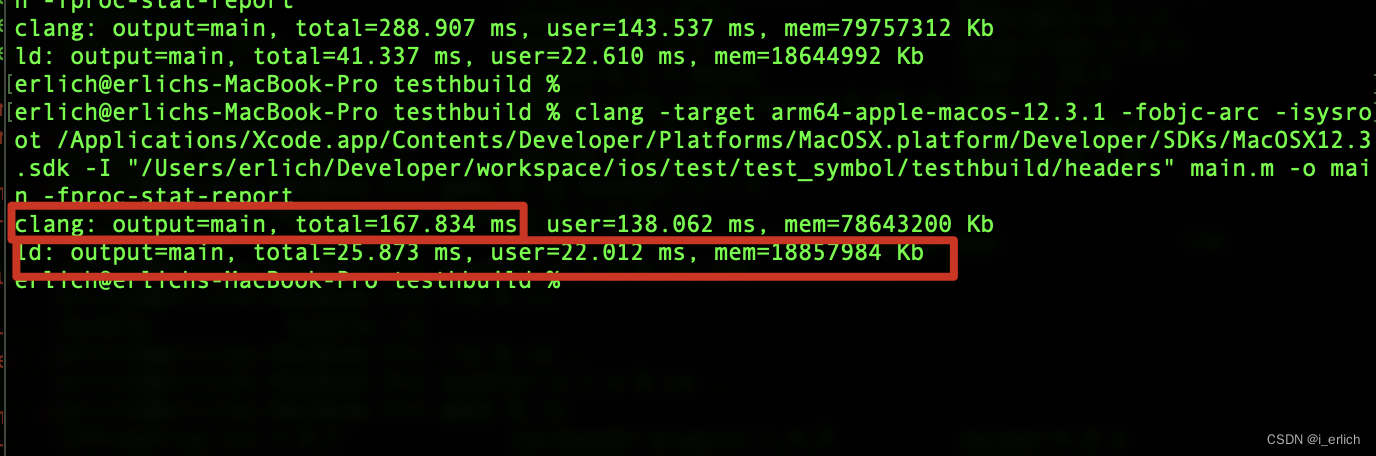
这两个阶段都需要时间,要考虑如何加快编译速度,首先得选择在以上哪个阶段处理,选择的标准就是看哪个阶段的耗时更长,处理才变得更有意义
编译消耗时间 167毫秒,链接消耗时间
如果头文件目录很多,意味着耗时进一步增加
header编译?
header是否参与编译
简单设想一下,在.h中定义个函数,在.m中调用定义的函数,是否执行,若执行的话,如果.h不编译,函数又从何而来呢
如果有研究过oc底层源码的话, .h中有很多定义, 可以看下 objc_class .h中定义
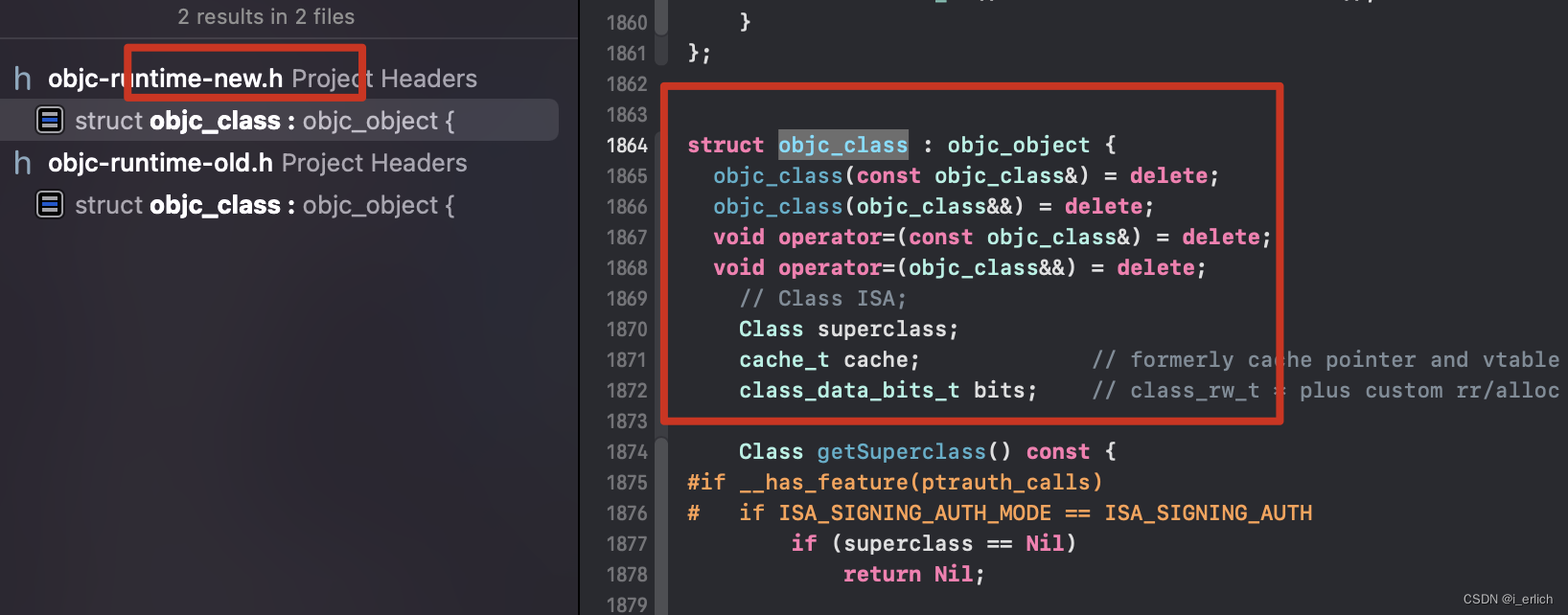
.h如何编译进来 (组件二进制 = 二进制 + .h)
.h存在于何处 如何查找
最终 目录/xxx.h 找到头文件
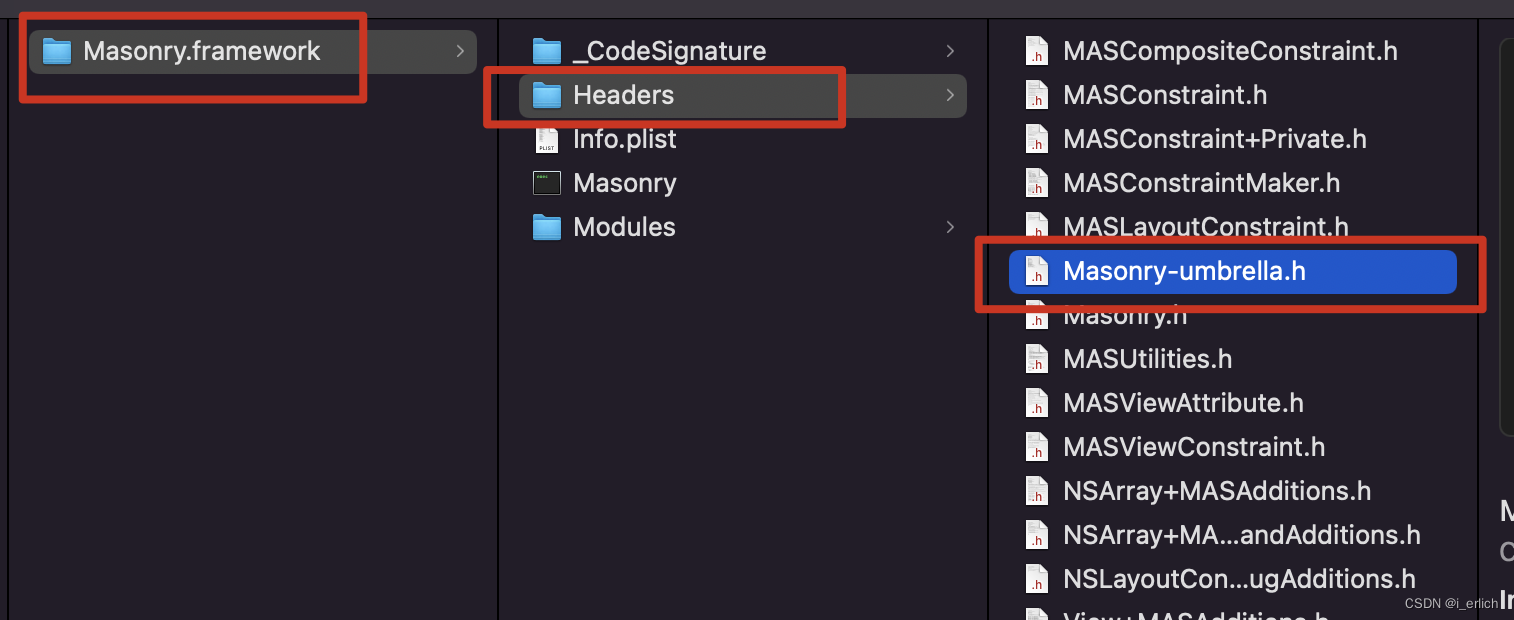
framework的头文件引入方式 <xxxxFramework/xxxx.h>, 也就是module/头文件
framework -> module -> 映射头文件
比如 pod安装 Masonry, Masonry.framework 包内容,存在 Modules/module.modulemap 这样一个文件
framework module Masonry {
umbrella header "Masonry-umbrella.h"
export *
module * { export * }
}
umbrella 指向一个头文件 Masonry-umbrella.h
umbrella header Masonry-umbrella.h 就是 module的伞柄
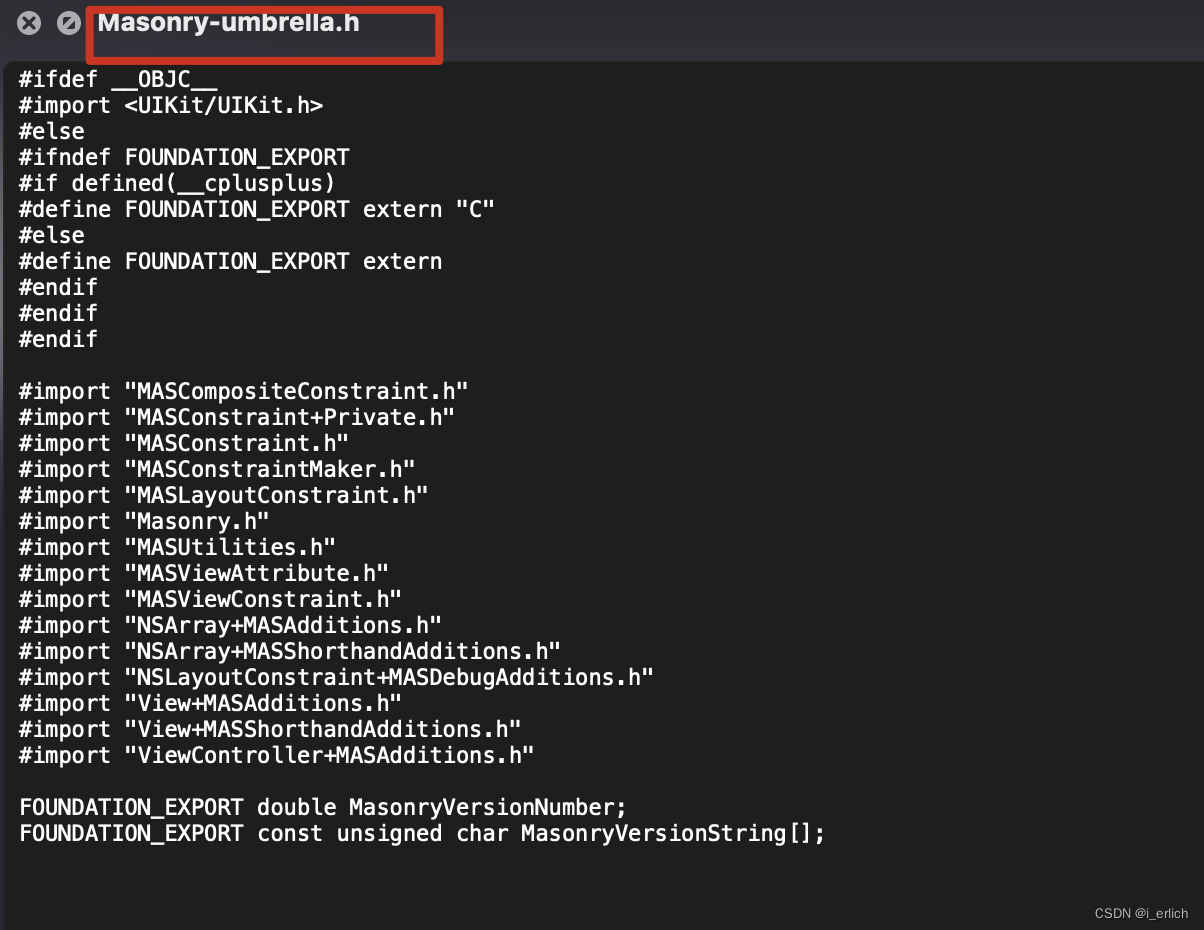
.a 头文件引入 – 目录/xxx.h
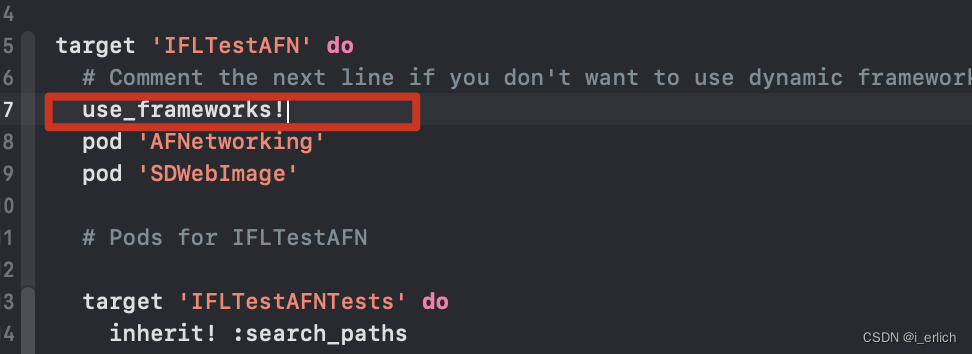
注释掉 Podfile use_frameworks!
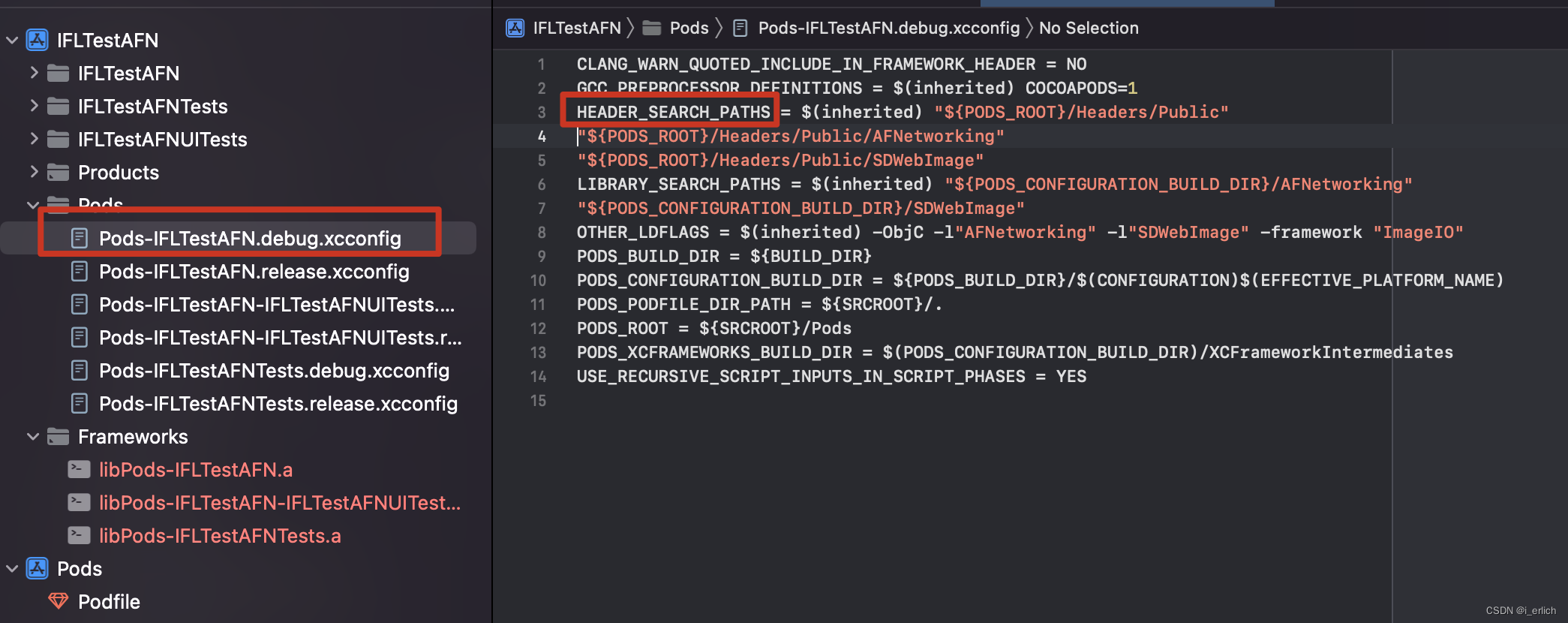
比如配置了 ${PODS_ROOT}/Headers/Public
就可以通过 Public目录下 AFNetworking/xxx.h的方式查找头文件了
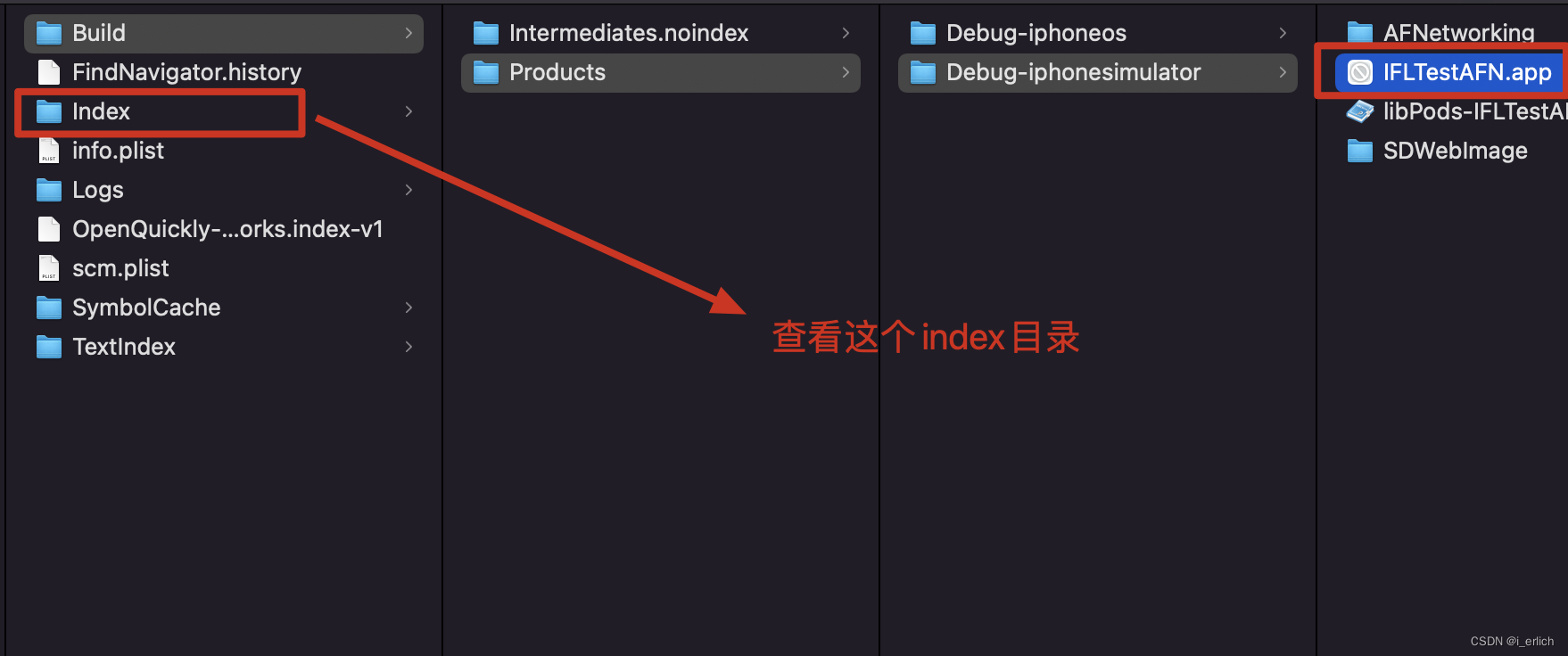
以下就是头文件编译之后的二进制形式了
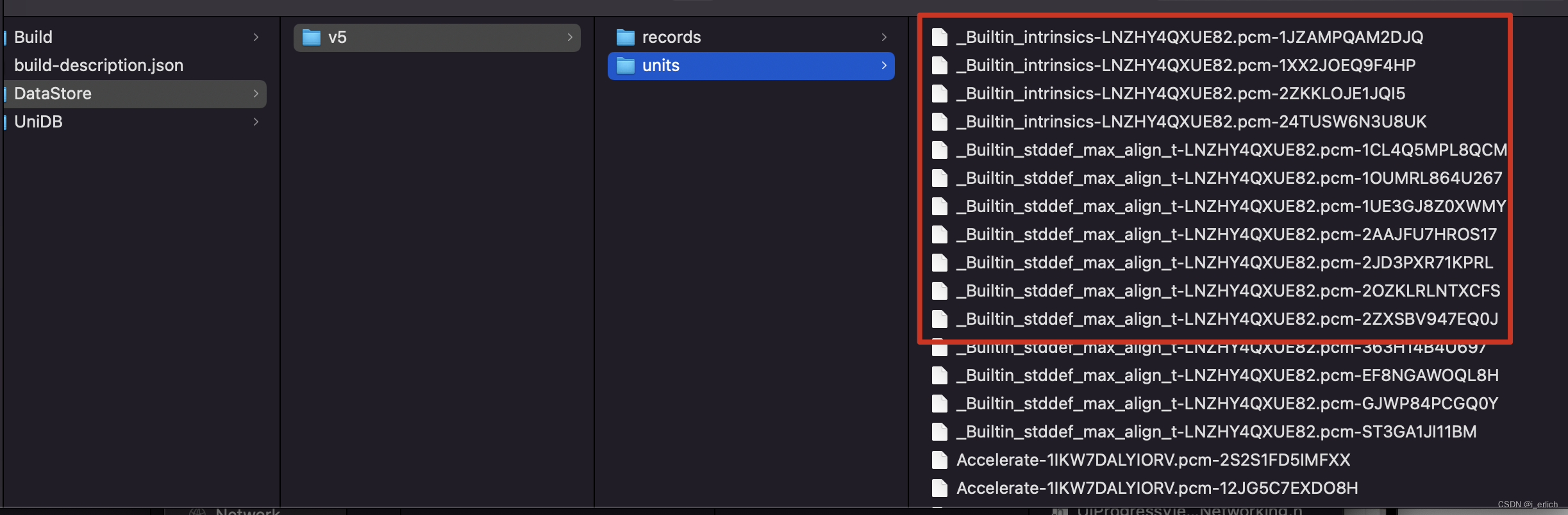
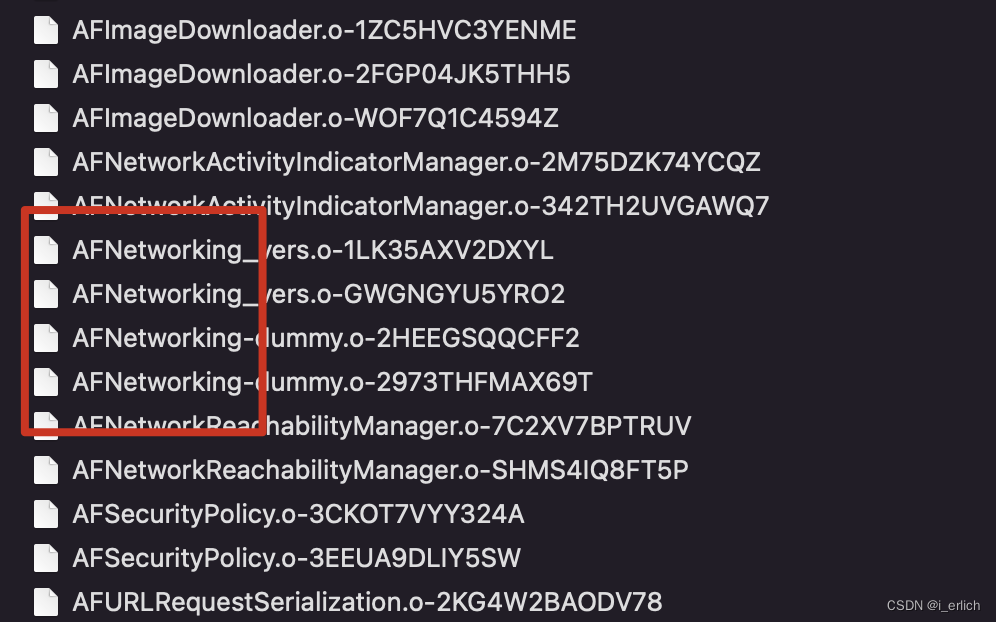
再次编译的时候,直接读取.h编译的二进制文件,节省了目录搜索的过程,效率会高一些
如何找到 这些 二进制文件呢?
引出hmap
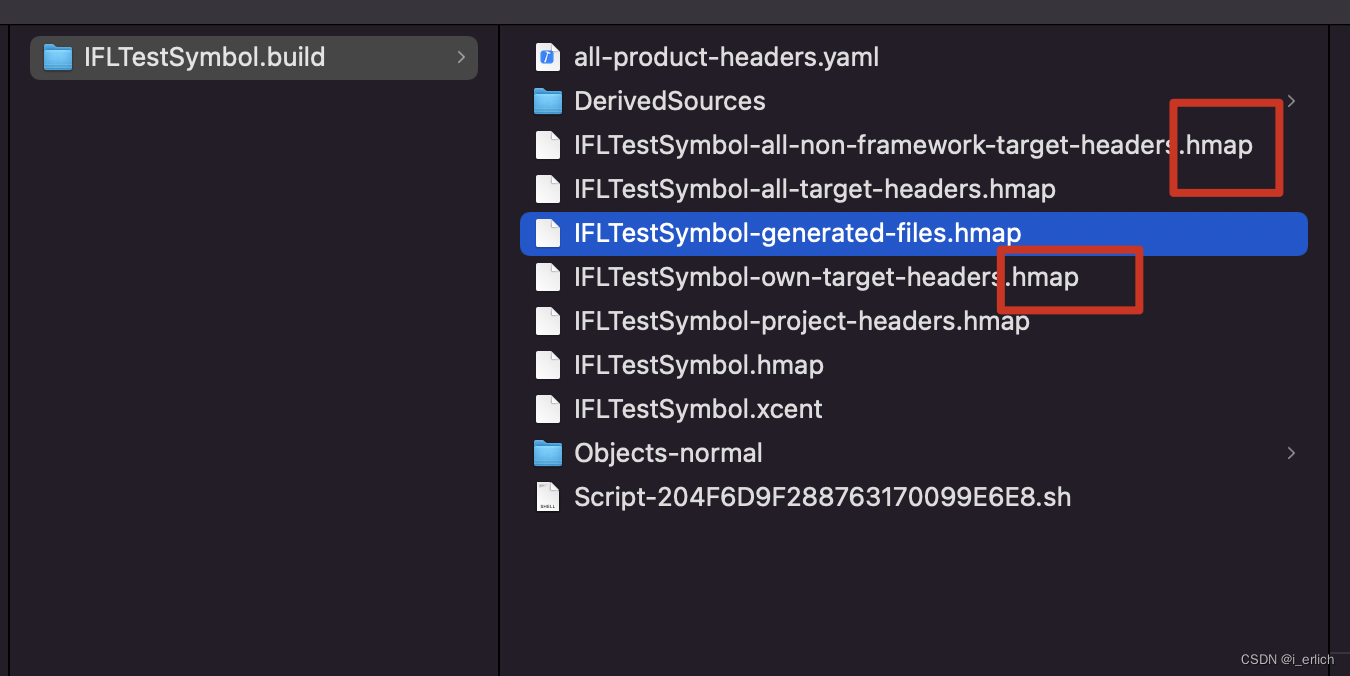
再次编译时,就是通过这些 hmap文件 找到对应的 .h编译的二进制文件
hmap 字面理解就是 header映射,里面至少是 key – value这样的映射结构
简单看下,xcode在编译 一个.m文件时,-I 引入了.hmap文件
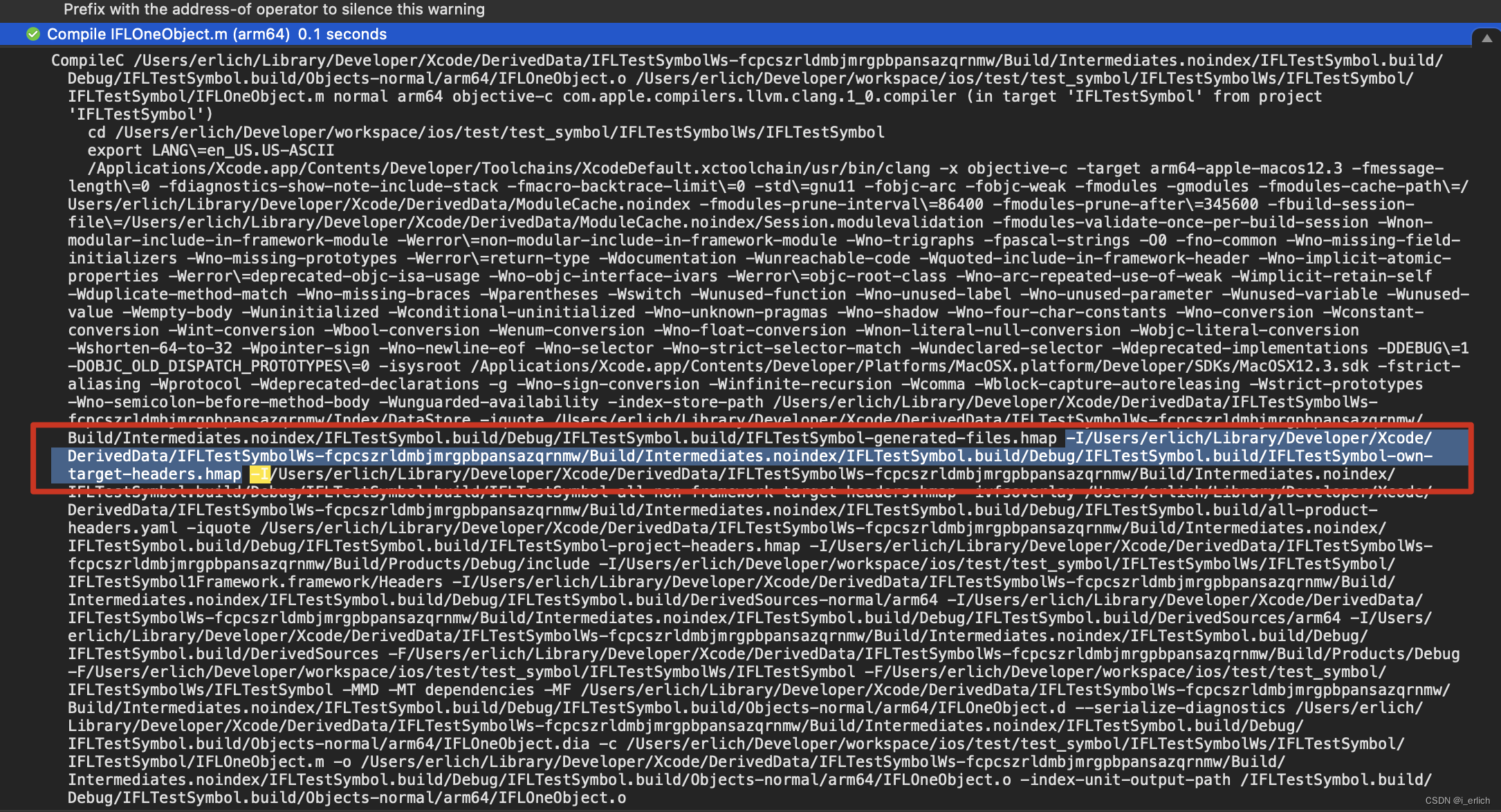
cat命令查看下 主工程项目的hmap文件 – IFLTestSymbol-project-headers.hmap
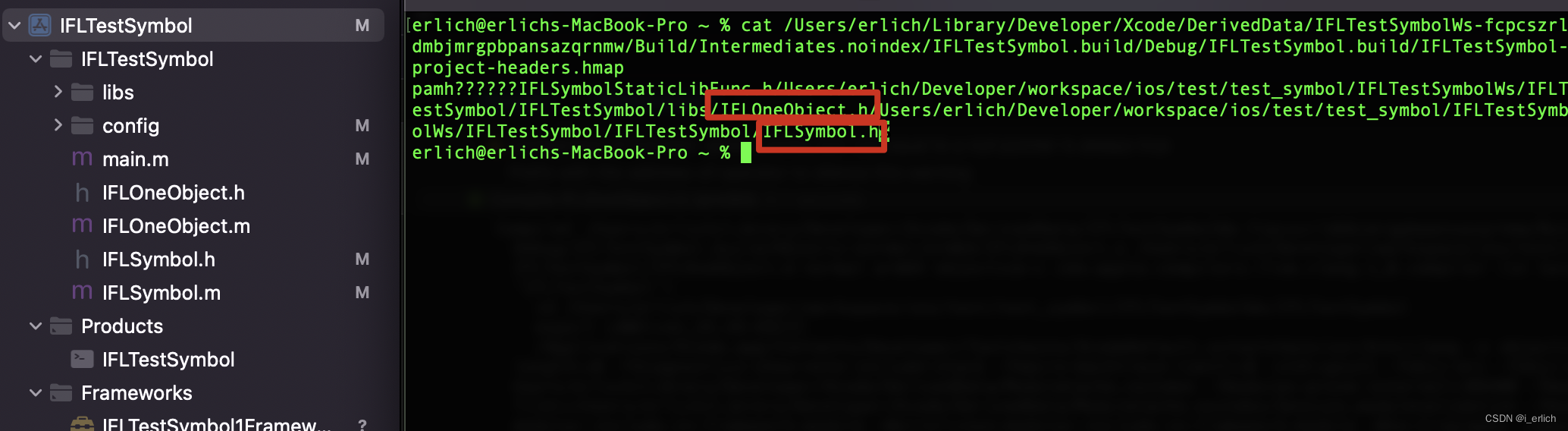
图中能看到大概信息包含3个.h文件,一个静态库.a头文件,两个主工程中的.h文件
hmap数据结构
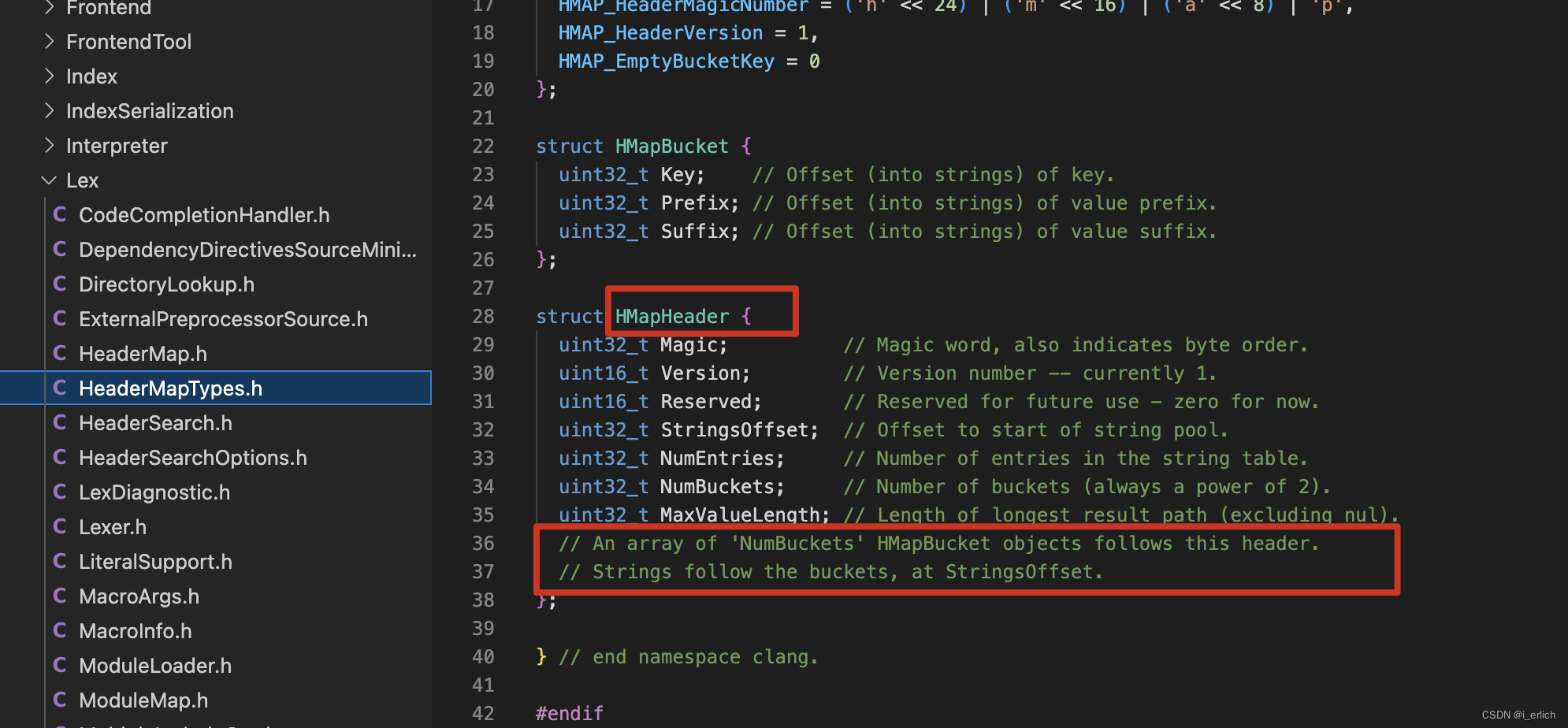
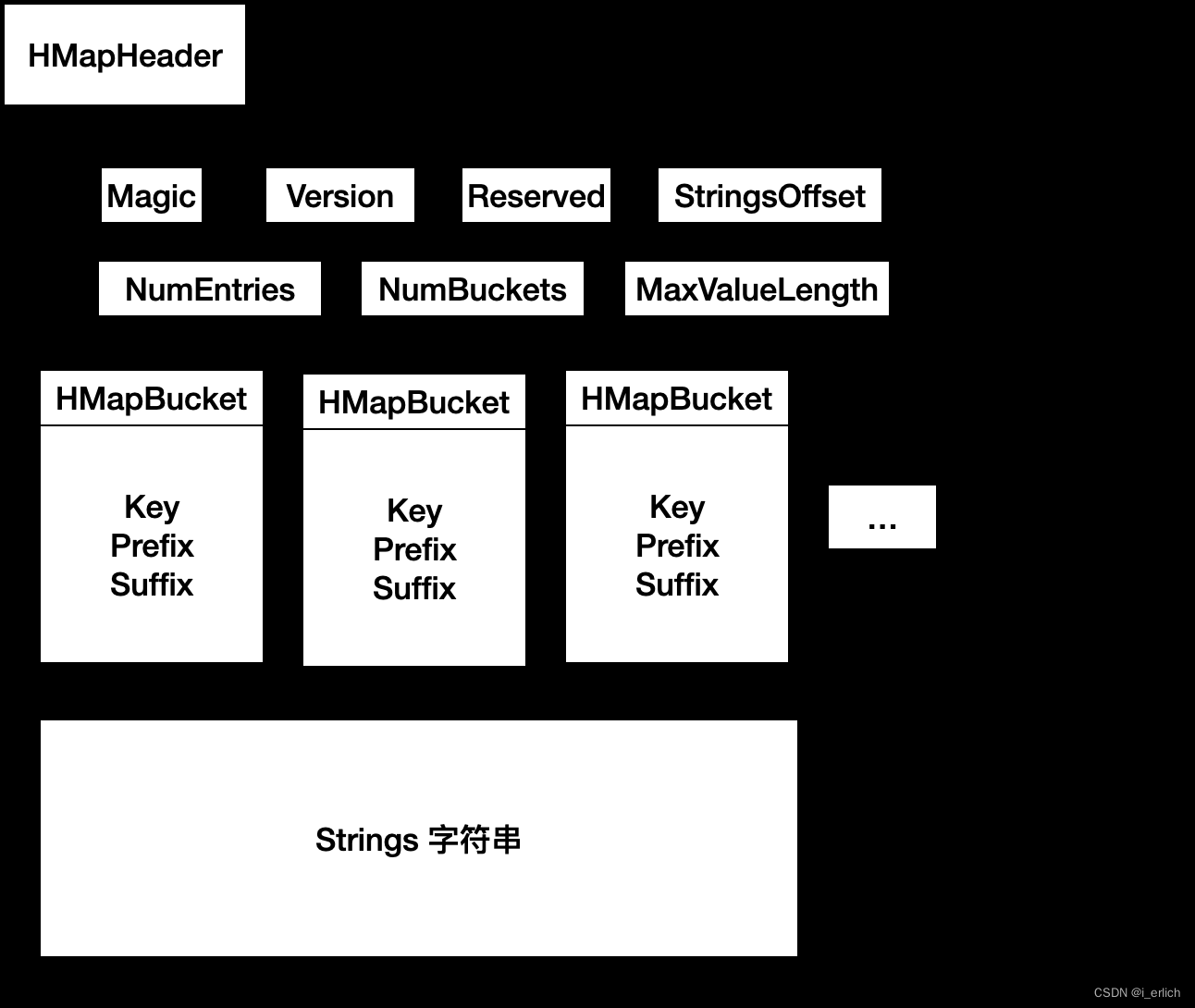
其中 HMapBucket结构中的 Key,Prefix,Suffix并不是字符串,而是各自代表的字符串在 长字符串中的偏移量
可以这样理解,hmap 的关键信息 key:目录前缀/头文件
读取到key的偏移,上 字符串中 根据key的偏移取出 key字符串
读取到前缀偏移,上 字符串中 根据前缀的偏移取出 前缀字符串
读取到后缀偏移,上 字符串中 根据后缀的偏移取出 后缀字符串
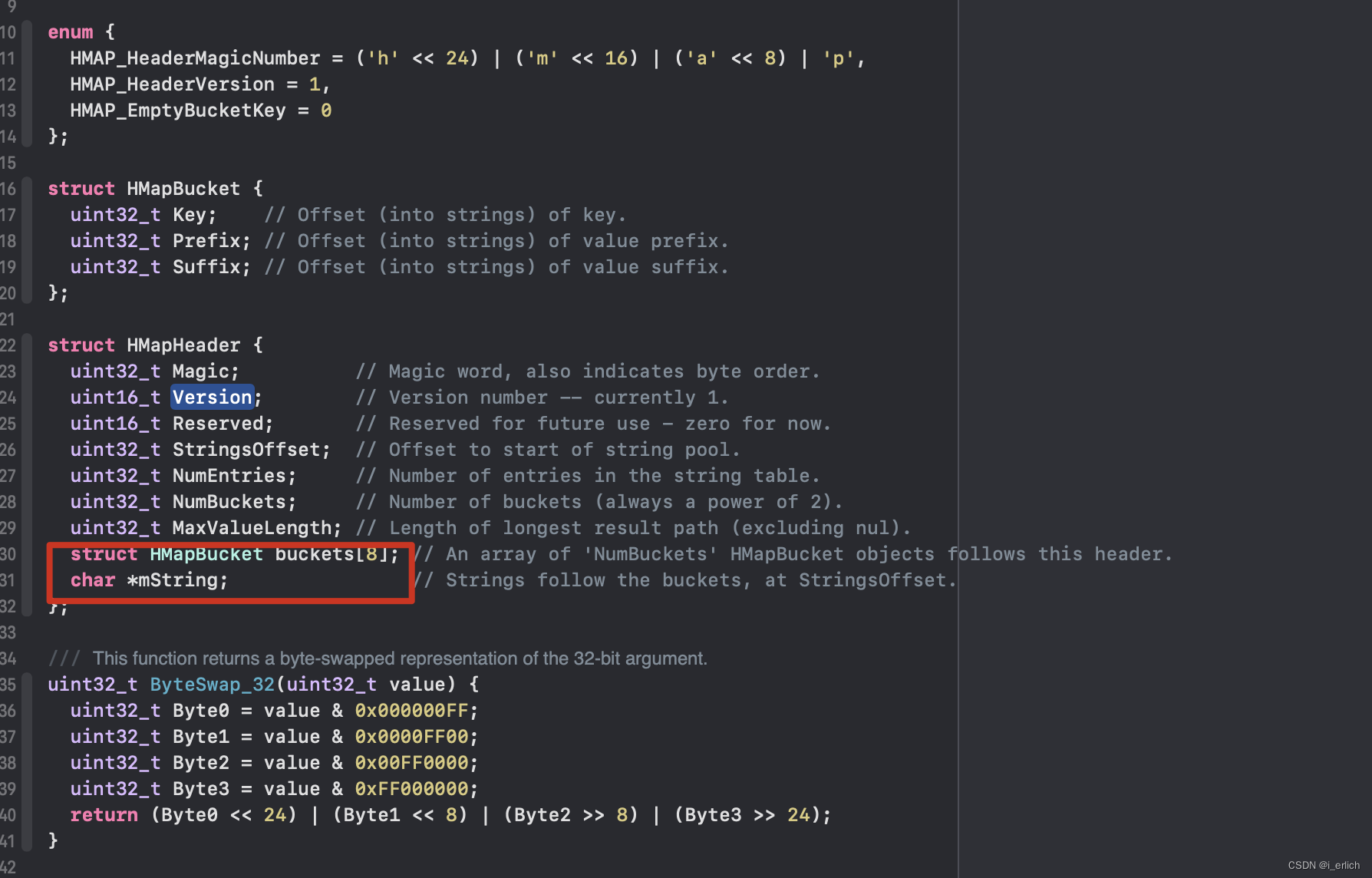
c++读hmap
void read_hmap(void) {
// test_hmap/Test111-all-non-framework-target-headers.hmap
// test_hmap/Test111-all-target-headers.hmap
// test_hmap/Test111-own-target-headers.hmap
// test_hmap/Test111-project-headers.hmap
// test_hmap/IFLTestSymbol-all-target-headers.hmap
// test_hmap/IFLTestSymbol-generated-files.hmap
// test_hmap/IFLTestSymbol-own-target-headers.hmap
// test_hmap/IFLTestSymbol-project-headers.hmap
// char *path = "/Users/erlich/Developer/workspace/ios/test/test_symbol/Test111/HMap/Test111.build/Debug-macosx/Test111.build/Test111-project-headers.hmap";
char *path = "/Users/erlich/Developer/workspace/ios/test/test_symbol/Test111/Test111/test_hmap/Test111-project-headers.hmap";
int file = open(path, O_RDONLY|O_CLOEXEC);
if (file < 0) {
printf("cannot open file %s", path);
return;
}
struct HMapHeader *header = malloc(100 * sizeof(struct HMapHeader));
ssize_t headerRead = read(file, header, 100 * sizeof(struct HMapHeader));
if (headerRead < 0 || (size_t)headerRead < sizeof(struct HMapHeader)) {
printf("read %s fail", path);
close(file);
return;
}
close(file);
// Sniff it to see if it's a headermap by checking the magic number and version.
bool needsByteSwap = false;
if (header->Magic == ByteSwap_32(HMAP_HeaderMagicNumber) && header->Version == ByteSwap_32(HMAP_HeaderVersion)) {
// 高低位变换
needsByteSwap = true;
}
uint32_t NumBuckets = needsByteSwap ? ByteSwap_32(header->NumBuckets) : header->NumBuckets;
uint32_t StringsOffset = needsByteSwap ? ByteSwap_32(header->StringsOffset) : header->StringsOffset;
const void *raw = (const void *)header;
// HMapBucket 数组
const void *buckets = raw + 24;
// 长字符串
const void *string_table = raw + 24 + 8 + header->StringsOffset;
printf("buckets 初始化了: %inn", NumBuckets);
// printf("长字符串:%snn", string_table);
int mBucketsCount = 0;
for (uint32_t i = 0; i < NumBuckets; i++) {
struct HMapBucket *bucket = (struct HMapBucket *)(buckets + i * sizeof(struct HMapBucket));
bucket->Key = needsByteSwap ? ByteSwap_32(bucket->Key) : bucket->Key;
bucket->Prefix = needsByteSwap ? ByteSwap_32(bucket->Prefix) : bucket->Prefix;
bucket->Suffix = needsByteSwap ? ByteSwap_32(bucket->Suffix) : bucket->Suffix;
if (bucket->Key == 0 && bucket->Prefix == 0 && bucket->Suffix == 0) {
continue;
}
mBucketsCount++;
const char *key = string_table + bucket->Key;
const char *prefix = string_table + bucket->Prefix;
const char *suffix = string_table + bucket->Suffix;
printf("key: %s, offset: %i nprefix: %s, offset: %i, nsuffix: %s, offset: %inn", key, bucket->Key, prefix, bucket->Prefix, suffix, bucket->Suffix);
}
printf("buckets 初始化了%i个,实际使用了%i个nn", NumBuckets, mBucketsCount);
free(header);
}
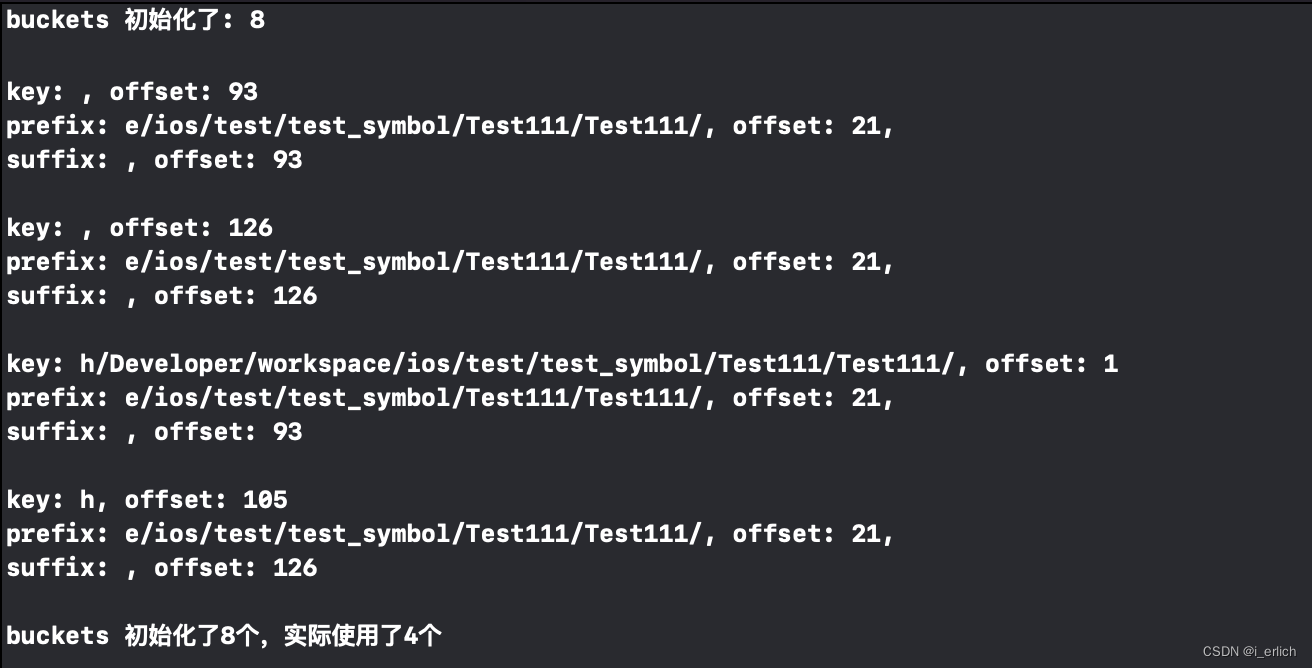
由于读取hmap内容的c++代码并没有 内存偏移处理,所以做了取巧处理
- 将HMapBucket数组作为 HMapHeader的成员
- 长字符串具体长度目前未知,读取hmap缓冲大小设定了一定的冗余空间
- header结构体内容 参考llvm源码中的逻辑,需要做高低位反转判断
- 长字符串部分初始需要做偏移 – header->StringsOffset
获取到的key prefix suffix 与预期的有一定的偏差
读取环节有纰漏,大概可以推断出错的缘由在于字符串偏移上,明显是偏移过多了,也就是偏移起始出错了

读取hmap内容就显示正常了
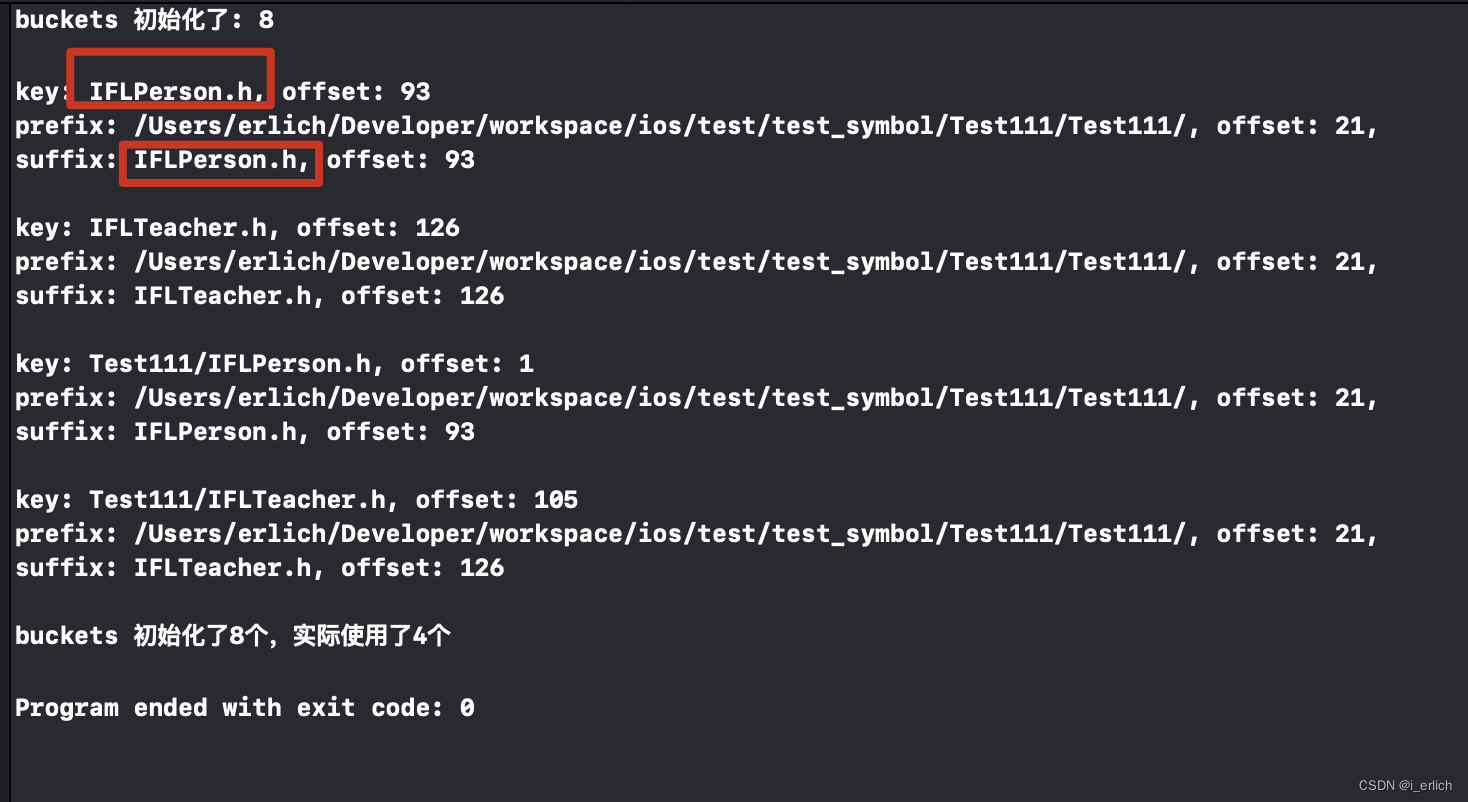
hmap理解
理解pod xcconfig header search path
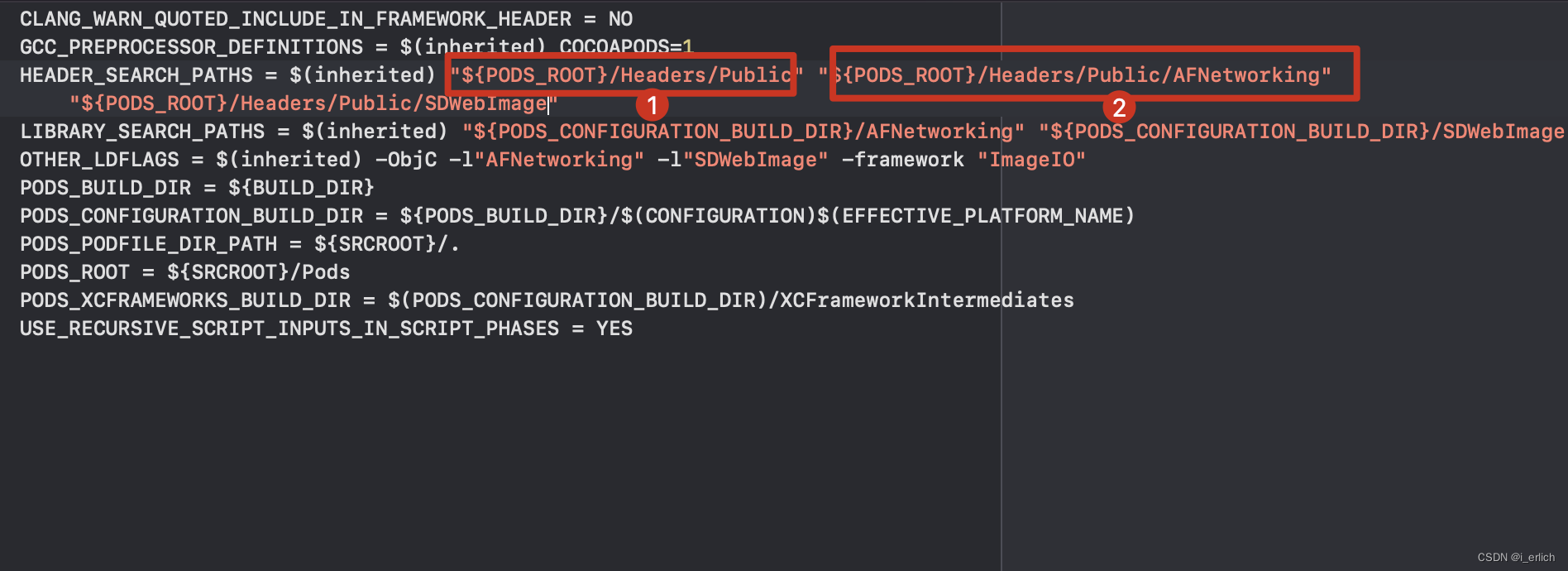
剩下的就是hmap配置了
当前配置是根据 header search paths 最终找到 前缀目录+后缀头文件.h
现在换成 不查找目录,直接查找hmap中的 key,拿到 prefix + suffix拼接的结果
原文地址:https://blog.csdn.net/qq_42431419/article/details/125962714
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6005.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!