目录
摘要
本周学习了多视角自注意力网络,在统一的框架下联合学习输入句子的不同语言学方面。具体来说,提出并利用多种诱导性偏差来规则化常规的注意力分配。然后通过混合注意力机制聚合不同的视图,以方便地量化和利用特定的视图及其相关的表示。Self-attention是一种在自然语言处理(NLP)和深度学习领域中广泛应用的机制。它允许模型关注输入序列中的不同部分,并根据这些部分生成输出。通过学习输入序列中不同位置之间的关系,self-attention可以帮助模型更好地理解输入并产生更有意义的输出。在Transformer架构中,self-attention作为核心组件,提高了模型在各种NLP任务中的性能,包括机器翻译、文本分类和问答等。本文将介绍self-attention的基本原理、应用和未来的研究方向。
Abstract
This week, we learnt about multi-perspective self-attention networks that jointly learn different linguistic aspects of input sentences in a unified framework. Specifically, multiple induced biases are proposed and utilised to regularise regular attention allocation. The different views are then aggregated via a hybrid attention mechanism to facilitate the quantification and exploitation of specific views and their associated representations.Self-attention is a widely used mechanism in the fields of natural language processing (NLP) and deep learning. It allows a model to focus on different parts of an input sequence and generate output based on those parts. By learning the relationships between different locations in the input sequence, self-attention helps the model to better understand the input and produce more meaningful output. In the Transformer architecture, self-attention serves as a core component that improves the model’s performance in a variety of NLP tasks, including machine translation, text categorisation, and Q&A. In this paper, we present the fundamentals, applications, and future research directions of self-attention.
一、文献阅读
1.论文标题
Multi-view self-attention networks
2.论文摘要
最近的研究证明,通过利用不同的归纳偏见,SAN可以得到进一步的改进,这些偏见指导SAN学习输入句子的特定视图,如短期依赖关系、前后视图和短语模式。然而,较少有研究探讨这些归纳技术如何互补地提高SAN的能力,这将是一个有趣的问题。在本文中,我们选取了五个简单且不过度参数化的归纳偏误来考察它们的互补性。本文提出了多视角自注意力网络,在统一的框架下联合学习输入句子的不同语言学方面。具体来说,提出并利用多种诱导性偏差来规则化常规的注意力分配。然后通过混合注意力机制聚合不同的视图,以方便地量化和利用特定的视图及其相关的表示。在各种翻译任务上的实验表明,不同的视图能够逐步改善SAN的性能,并且所提出的方法在Transformer – base和Transformer – big设置上优于强Transformer基线和相关模型。
3.论文背景
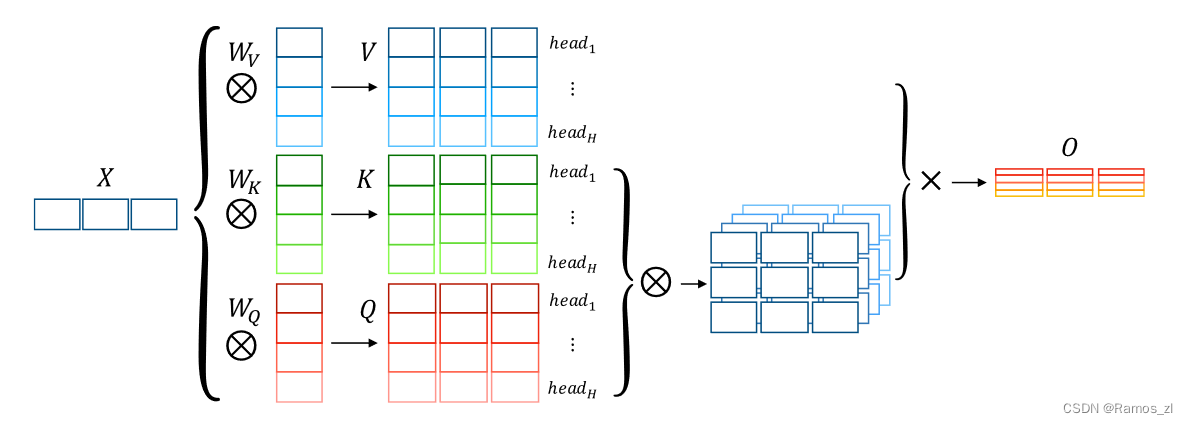
作为注意力机制的一种变体,SAN通过计算每对输入token之间的相关性来产生输入序列的单词级表示。在相同的表示上应用多个单独的注意力函数可以进一步提高基于注意力机制的性能,即多头机制,如图所示。多中心语机制的每个中心语都可以作为对输入句的特定看法。在这里,我们首先介绍了该机制的流程。在形式上,该模型首先将输入序列X = { x1,…,xN }∈RN × d映射到具有不同线性投影的H个子空间(视图)中:
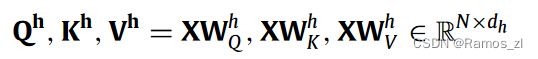
序列Oh = { Oh1,…,OhN }的第i个输出Ohi是值Vh的加权和:
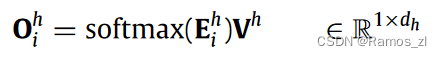
Ehi∈R1 × N表示当前查询Qhi和关键字Kh之间的注意力能量,它是通过一个缩放的点积注意力来计算的。为了整合从多头注意力机制的每个头收集的信息,将输出状态进行级联,然后进行线性变换:
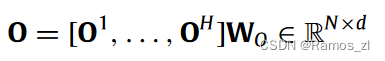
多头机制较好地兼顾了整个序列,没有任何的指导方针。因此,不同的头脑可能会学习相同的语言属性,并抑制一些重要关系的提取。为了解决这些问题,一种替代的方法是给多个中心点分配特定的任务,例如,引导每个中心点专注于输入句子的某一方面。
4.论文方案
为了研究和利用不同类型的视图,例如距离感知,方向信息和短语模式,该论文提出了多视图自注意力网络,将每个头部作为一个视图。这些任务特定的头脑不仅可以从单独的潜在空间,而且可以从不同的角度共同增强表征的语言信息。
4.1 多视角自注意力网络
下图说明了所提出模型的总体架构。取其中一个注意力头来解释该模型。这项工作的基本原则是保持SANs的优点,即有效性和简单性,同时用语言特性来补充SANs。对具有归纳偏差的观点进行建模。为此,我们提出对注意力分布进行正则化,从而引导中心点从特定角度关注输入句子。具体地,设计电感偏置Bhi∈R1 × N来修正原能量分布Ehi,即:
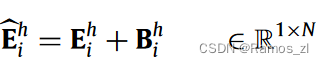
感应偏置Bh i是一个有利的对准位置矢量。元素Bh i,j∈( -∞,0 ]衡量了当前查询Qh i与第j个键Kh j之间的注意力能量在特定视图下的惩罚紧密度。本研究设计了几种诱导性偏向,以实现长短期、前向和后向的观点,以及短语模式。
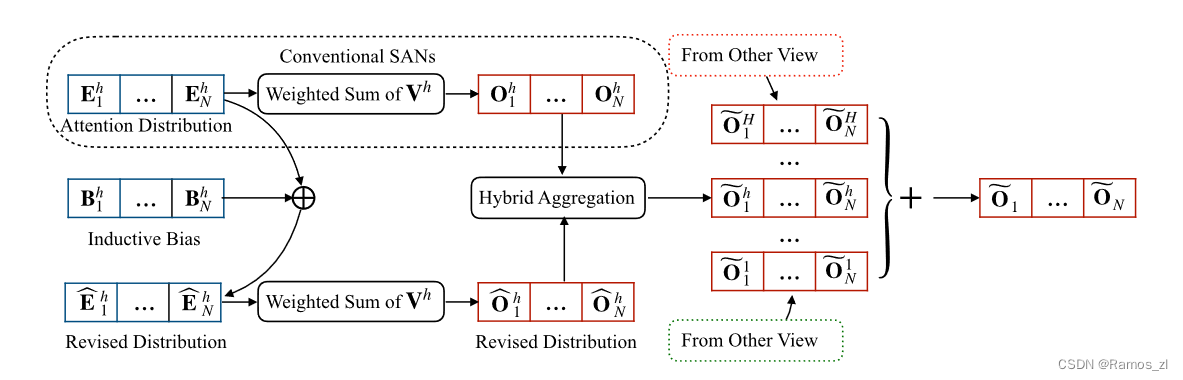
混合视图聚合。多个视图从相同的输入中提取不同的语言属性,对序列建模具有不同的贡献。然而,贡献度的度量成为造成困扰的问题。针对这个问题,可以将这个问题转化为量化视图表示和全局表示之间的重要性。为此,提出一种混合视图聚合来平衡和量化每个视图中的表示( Oh i )及其关联的常规表示Oh i。通过这种方式,该模型提供了利用局部信息的能力,同时保留了SANs在捕获全局上下文方面的优势。具体来说,每个头部的第i个最终表示可以计算如下:
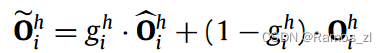
4.2 距离感知
给定一个输入句子,SAN不管词对之间的距离远近,都会构建词对之间的关系。距离感知信息的缺乏限制了SANs对语言建模的能力。为了解决这个问题,我们引入了两种归纳偏差来区分长短期信息。
Long-term view.。SAN在建模长程依赖方面并不优于循环神经网络。为了增强这种上下文信息,我们提出了一种长期的观点,旨在鼓励长距离词对之间的相关性,同时惩罚那些短距离的词对。
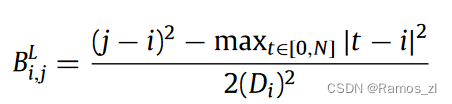
式中:N表示序列长度。分子的第二项表示当前词xi与序列中其他词之间的最大距离。随着xi与xj之间距离的增加,惩罚趋于0,直到距离达到最大值。我们提出使用指数分布来生成窗口大小,以鼓励学习到的范围倾向于一个较小的值:
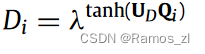
Short-term view。一些工作已经验证了SAN从建模短期信息中获益。根据他们的研究,我们使用高斯分布来自动修正 vanilla attention energy。从数学上讲,惩罚强度BS i,j可以计算为:
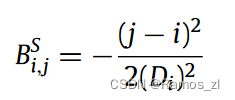
4.3 方向信息
方向信息是句子建模的另一个有用的语言学知识。我们使用前向和后向视图,为SAN提供识别前后上下文的能力。
Forward view:Forward view的目的在于关注气的左向信号:
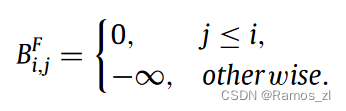
Backward view:Backward view将注意分数限制在向右的信号上:
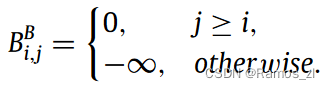
不同于三种掩模,即对角禁用、前向和后向掩模,该方法消除了前者,并将对角禁用偏置整合到后两种偏置中。因此,引导模型考虑方向信息或当前单词的内容。
4.4 短语模式
直观地说,在语言建模中,包含有用的局部上下文信息的短语模式更重要。与增强当前词xi的相邻信息的短期视图不同,短语视图背后的直觉是,围绕注意词xj的单词也被期望对齐,从而捕获短语信息,即:
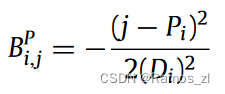
二、self-attention
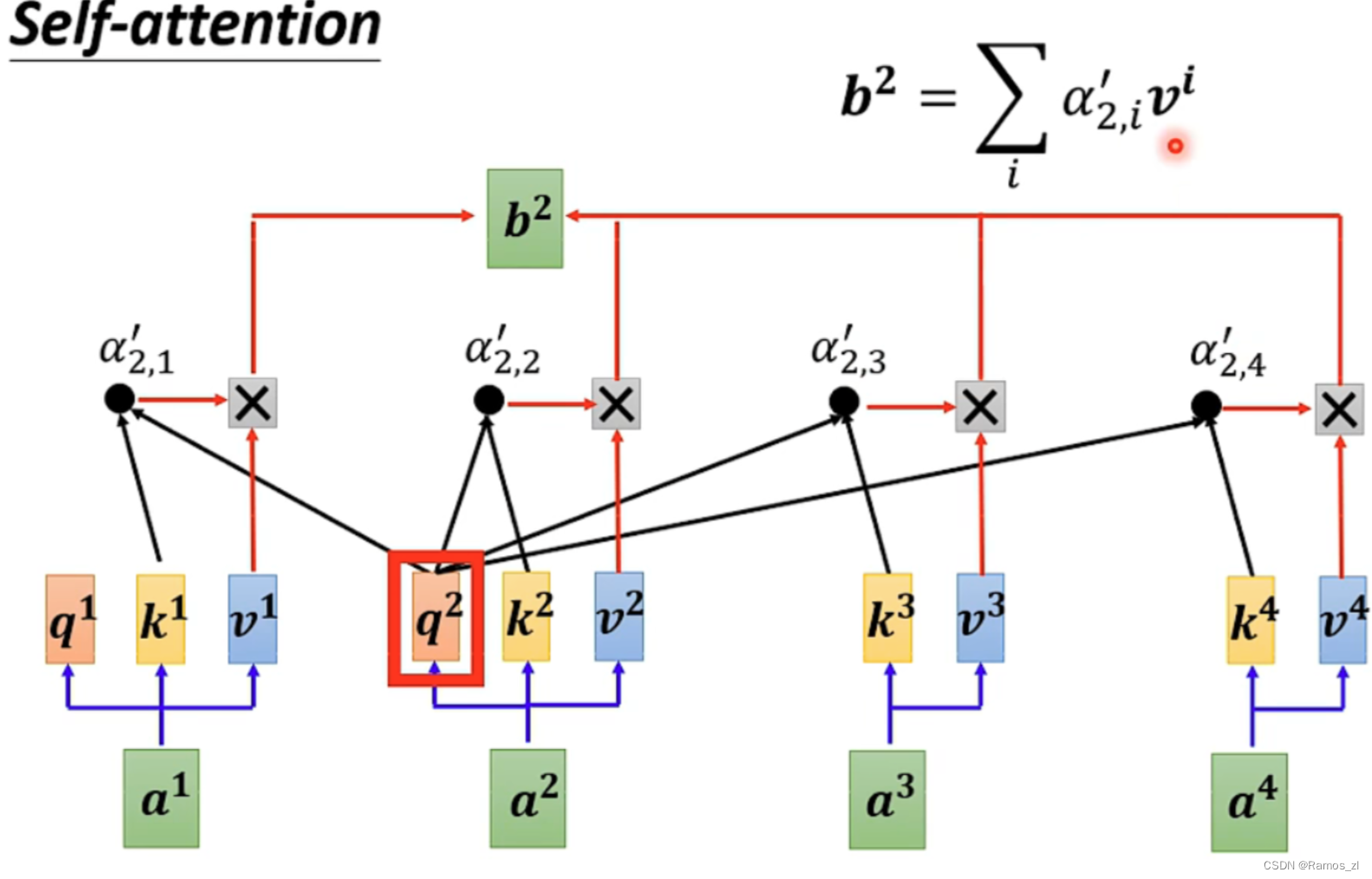
1.首先计算输入的向量之中,如a1,是否有其他向量与之相关。相关度记为α。计算过程如下。
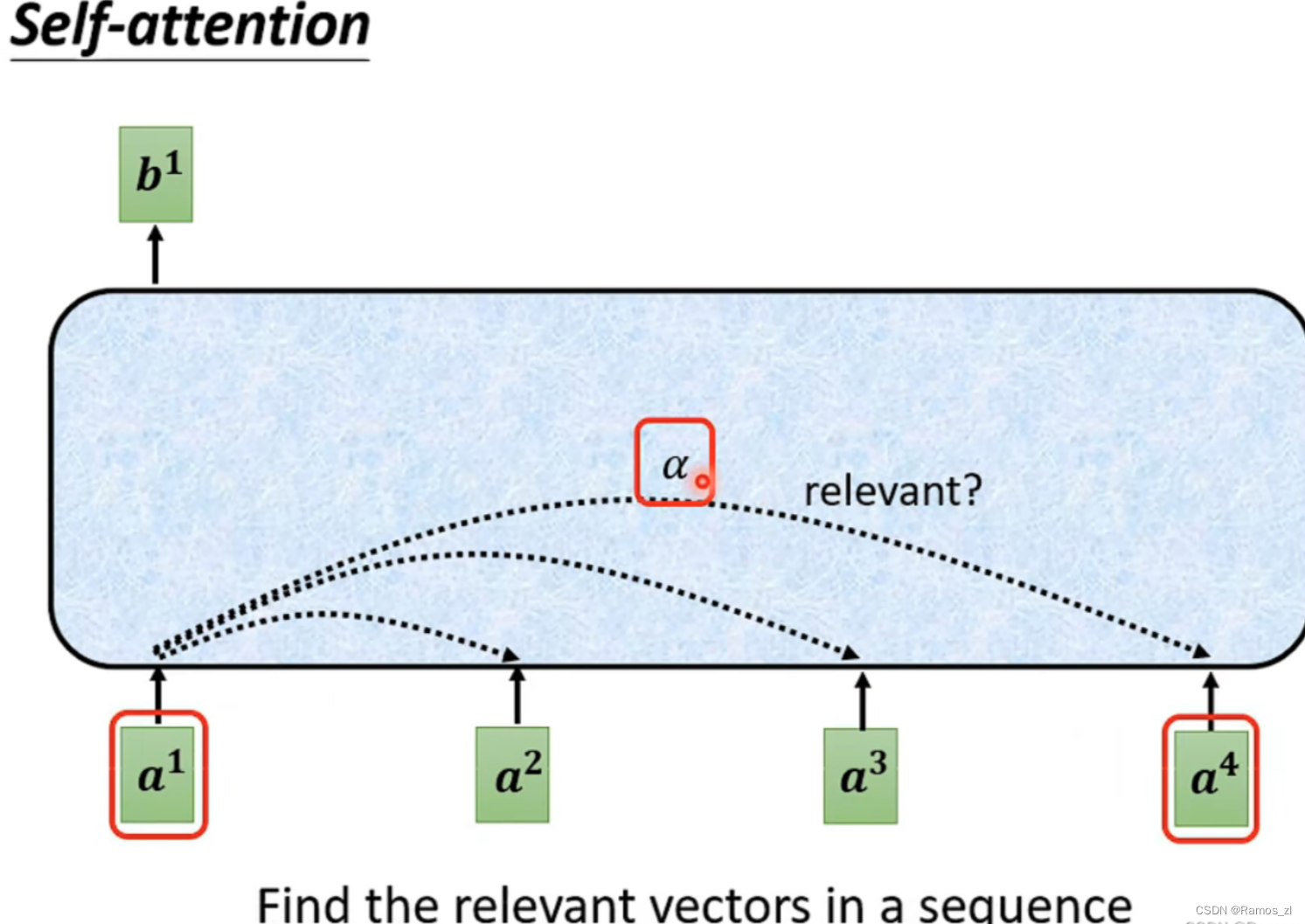
计算过程如图所示。将输入的向量分别乘上不同的矩阵Wq和Wk得到q和k,再将q和k进行点乘。
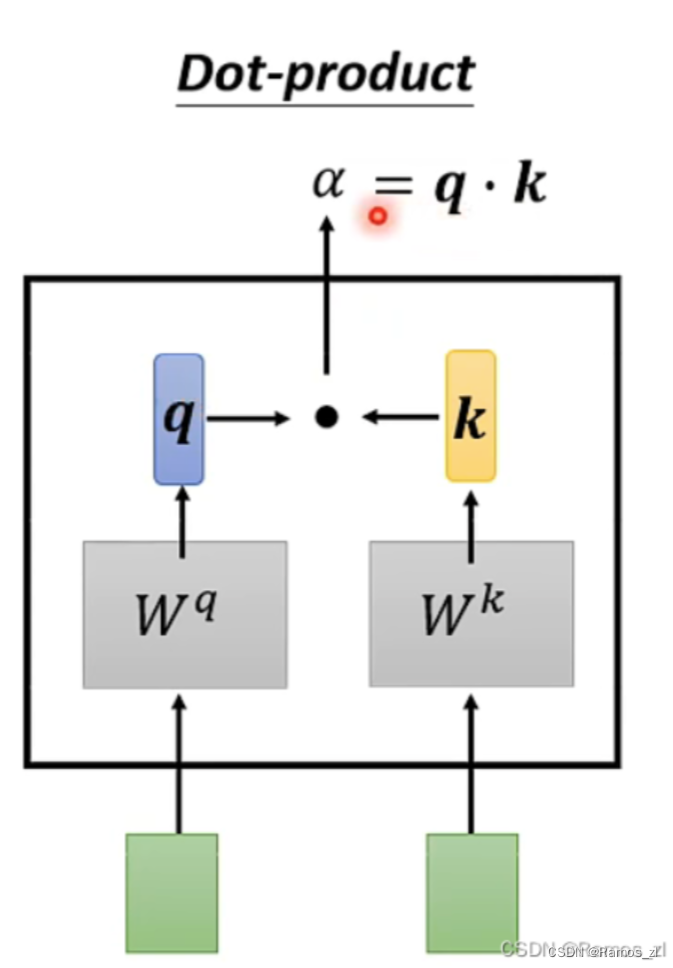
以a1为例,计算与其他向量的相似度时,将a1乘上Wq,其余的向量乘上Wk,再将得到的qi和ki进行点乘。得到的α 再经过一层softmax得到最后的输出预测值。
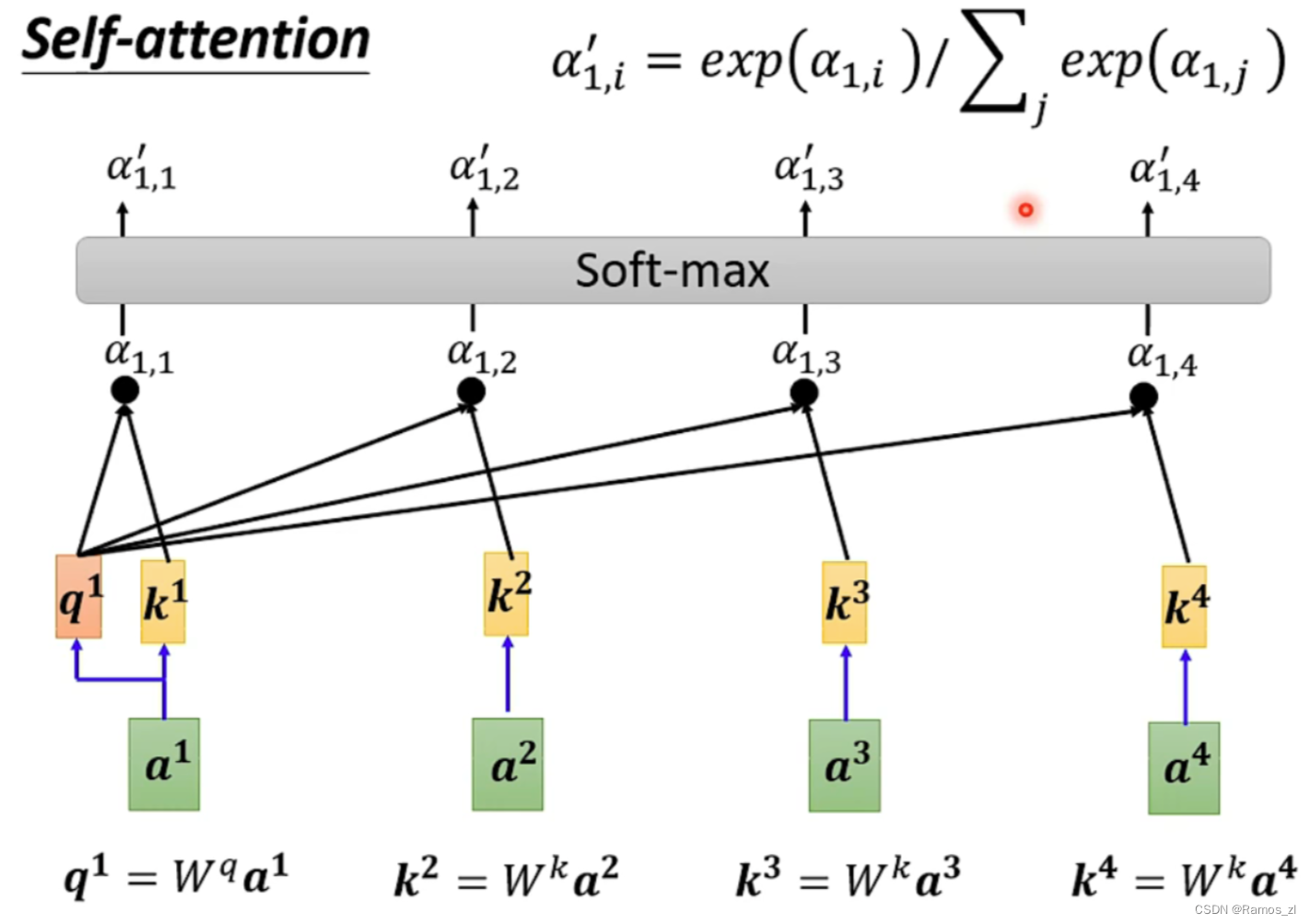
最后,将经过softmax的α与v相乘,再将其累加,则得到对应的输出b值。
对于注意力机制的理解,假如我们有一个问题:给出一段文本,使用一些关键词对它进行描述。
为了方便统一正确答案,这道题可能预先已经给大家写出了一些关键词作为提示,其中这些给出的提示就可以看作为key。而整个的文本信息就相当于是query。value的含义则更抽象,可以比作是你看到这段文本信息后,脑子里浮现的答案信息。这里我们又假设大家最开始都不是很聪明,第一次看到这段文本后脑子里基本上浮现的信息就只有提示这些信息因此key与value基本是相同的,但是随着我们对这个问题的深入理解,通过我们的思考脑子里想起来的东西越来越多。并且能够开始对我们query也就是这段文本,提取关键信息进行表示,这就是注意力作用的过程,通过这个过我们最终脑子里的value发生了变化,
根据提示key生成了query的关键词表示方法,也就是另外一种特征表示方法.
刚刚我们说到key和value一般情况下默认是相同,与query是不同的,这种是我们一般的注意力输入形式,但有一种特殊情况,就是我们query与key和value相同,这种情况我们称为自注意力机制,就如同我们的刚刚的使用一般注意力机制,是使用不同于给定文本的关键词表示它。
回顾所学的知识,当一个Self-Attention所处理的序列长度为N时,其内部的query和key的长度也为N,此时Attention Matrix就等于Ntimes N。因此,当N越大时,Attention内部的Attention Matrix越大,计算的复杂程度越高。
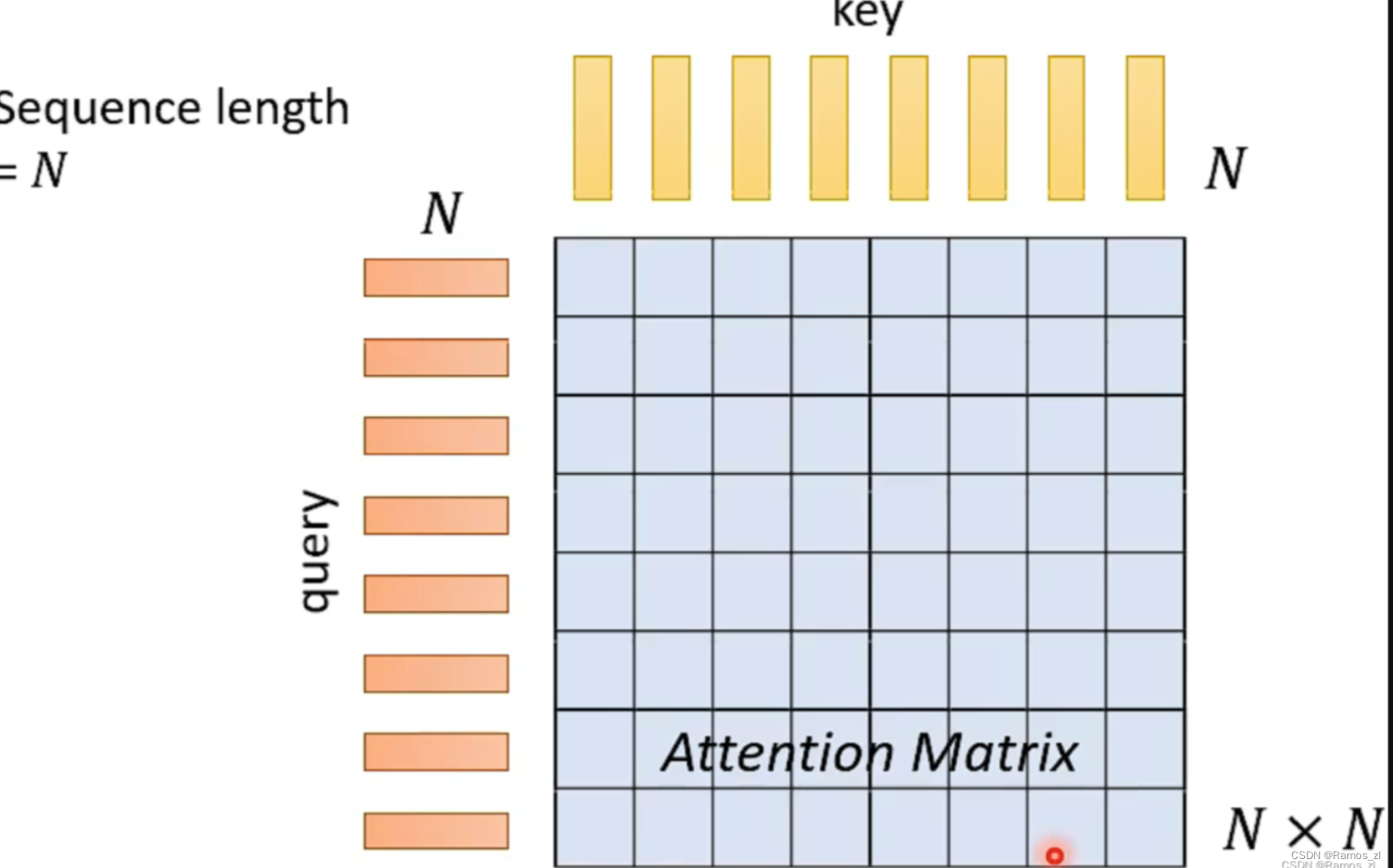
Skip some calculations with human knowledge
第一种方法是只让Self-Attention计算Attention Matrix中的部分值,另一部分的值由人类经验与认知值来补充。
比如说,让序列的每一个成员只考虑其附近成员的值,也就是将其query值与较远成员的key值的乘积直接设为零。这样的处理方式类似于CNN。
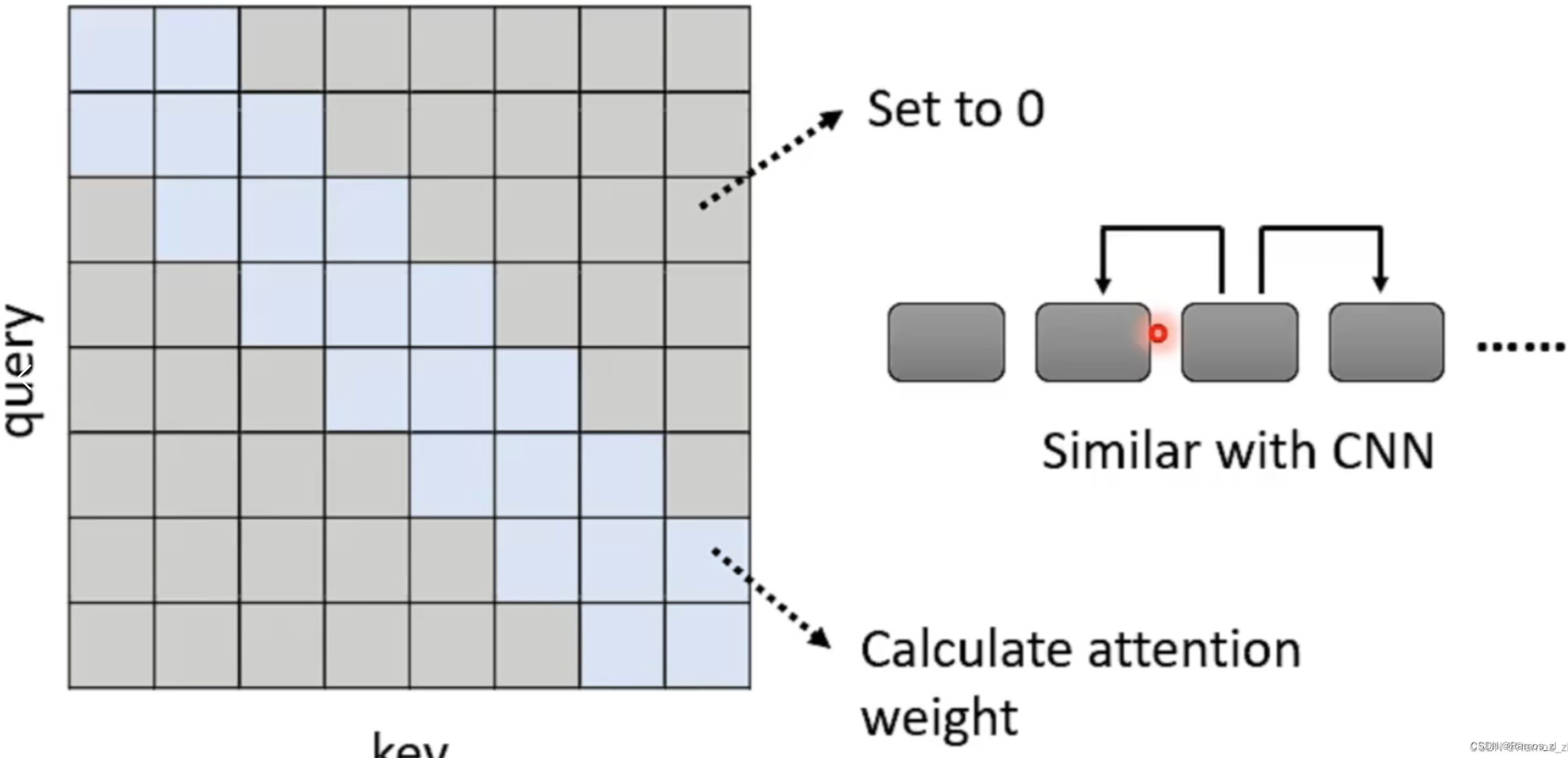
再比如说,让序列的成员每隔一定数量的成员考虑一次对应位置成员的值,也就是跳跃式地进行query和key的product。步长为1和2的Attention Matrix如下图所示。
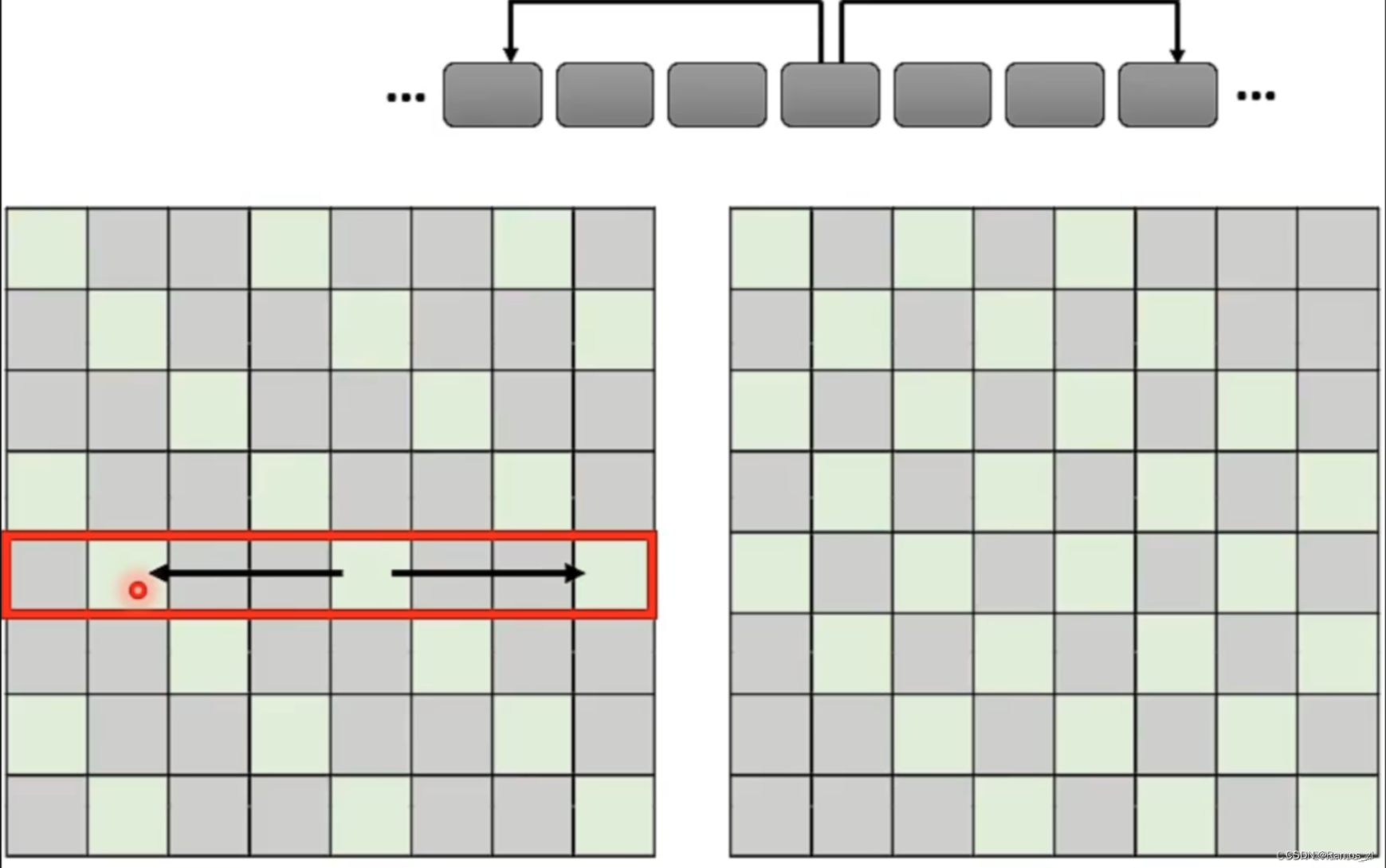
还比如说,在序列中加入Special Token,表示在这个位置要做Global Attention。 Global Attention主要做两件事,第一件事是让Special Token收集全局信息,也就是要考虑序列的每一个Token。第二件事是让Special Token被序列的每一个Token所考虑。实现Global Attention有两种方式,其一为在序列原有的Token中选一些作为Special Token。其二为外加Special Token,在计算Attention Matrix时,只考虑Special Token的query乘Token的key以及Special Token的key乘Token的query,而Token之间的query与Token之积不予计算。
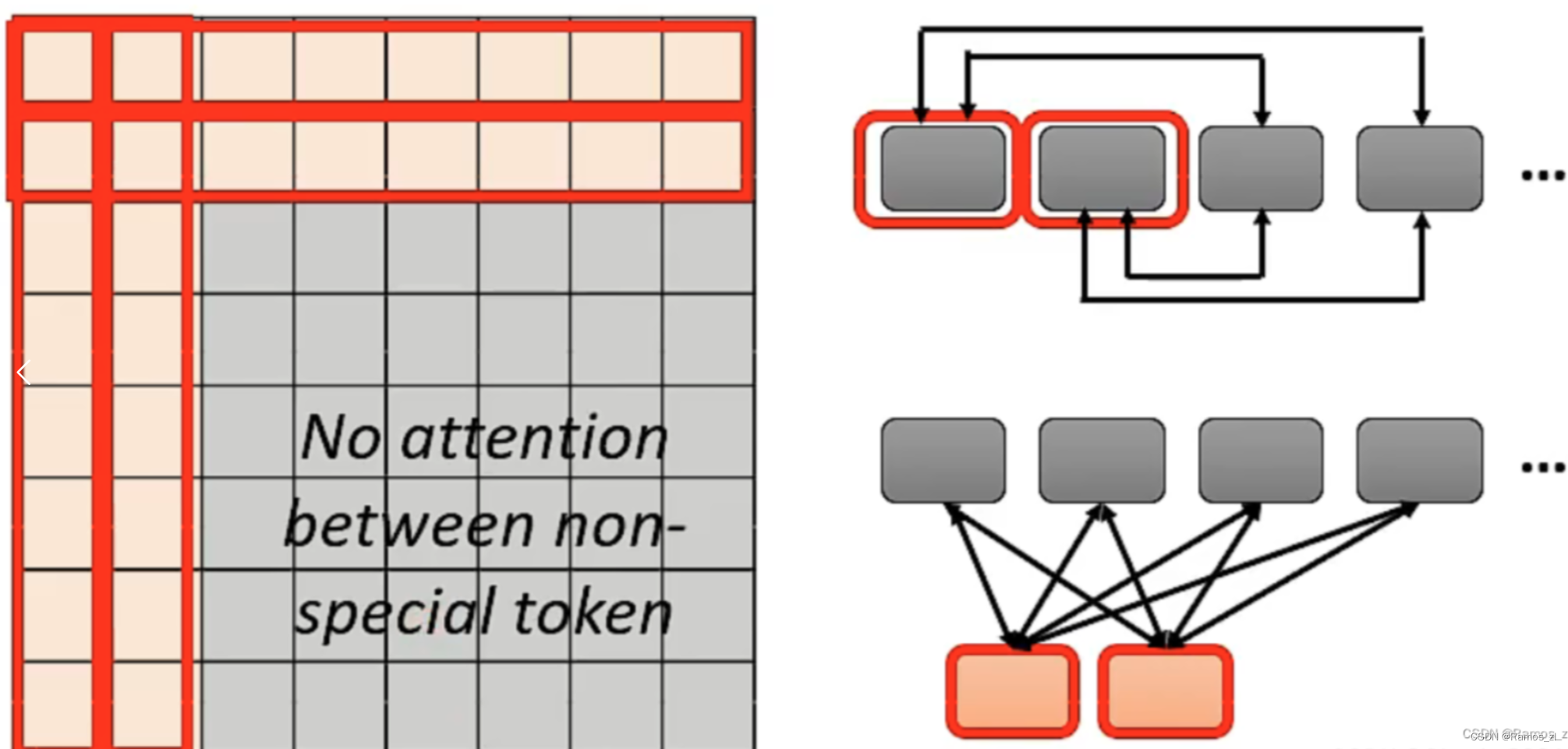
总的来说,Global Attention的作用可以类比为一个村庄,村民(Token)之间互不相识,而每一个村民(Token)都认识村长(Special Token),且村长(Special Token)都认识每一个村民(Token),因此村民(Token)之间的交流通过村长(Special Token)来实现。
上述三种减少Attention Matrix计算量的方法可以同时被使用,只要让Multi-head Self-Attention的不同head使用这三种不同方法即可。例如Longformer模型同时使用了Local Attention、Stride Attention以及Global Attention。Big Bird模型同时使用了Local Attention、Global Attention以及Random Attention(随机计算Attention Matrix的部分值)。
原文地址:https://blog.csdn.net/2301_78609379/article/details/135711814
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60054.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






