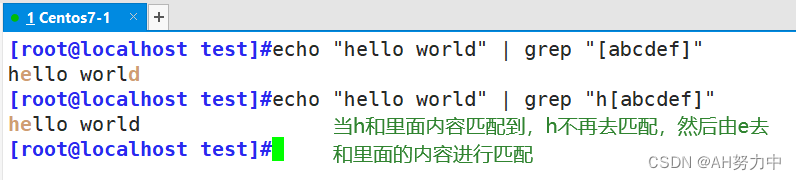
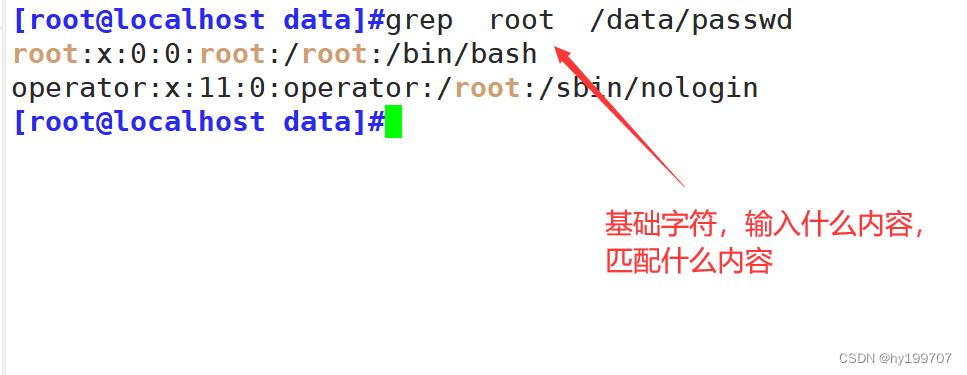
本文介绍: shell与正则表达式的结合
正则表达式
| 特殊字符 | 描述 |
|---|---|
[] |
方括号表达式,表示匹配的字符集合,例如 [0-9]、[abcde] |
() |
标记子表达式起止位置 |
* |
匹配前面的子表达式零或多次 |
+ |
匹配前面的子表达式一或多次 |
? |
匹配前面的子表达式零或一次 |
|
转义字符,除了常用转义外,还有:b 匹配单词边界;B 匹配非单词边界等 |
. |
匹配除 n(换行)外的任意单个字符 |
{} |
标记限定符表达式的起止。例如 {n} 表示匹配前一子表达式 n 次;{n,} 匹配至少 n 次;{n,m} 匹配 n 至 m 次 |
| |
表明前后两项二选一 |
$ |
匹配字符串的结尾 |
^ |
匹配字符串的开头,在方括号表达式中表示不接受该方括号表达式中的字符集合 |
正则表达式实例
匹配Email地址
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$
^[a-zA-Z0-9._%+-]+的解释:
^: 表示匹配字符串的开头。[a-zA-Z0-9._%+-]: 是一个字符类,包含了大小写字母(a-zA-Z)、数字(0-9)以及一些特殊字符(._%+-)。+: 表示前面的字符类中的字符可以出现一次或多次。
这个正则表达式的含义是:匹配以大小写字母、数字、点(.)、下划线(_)、百分号(%)、加号(+)或减号(-)开头的字符串。
匹配身份证号码
^(^[1-9]d{5}(18|19|20)d{2}(0[1-9]|1[0-2])([0-2][1-9]|10|20|30|31)d{3}(d|X|x)$
^[1-9]d{5} 是一个正则表达式,用于匹配一个六位的正整数。让我们解释一下这个正则表达式的各个部分:
^: 表示匹配字符串的开头。[1-9]: 匹配第一个字符是1到9之间的任意一个数字。d: 匹配任意数字(等同于[0-9])。{5}: 表示前一个元素(d)必须重复出现5次。
shell脚本与正则表达式结合的实例
有一个文本文件 data.txt 包含一些数据,每一行都有一个字符串,你想从中提取符合特定条件的数据。
#!/bin/bash
# 文件路径
file="data.txt"
# 匹配并提取所有包含数字的行
echo "Lines containing numbers:"
grep -E "[0-9]" "$file"
# 匹配并提取所有包含邮箱地址的行
echo -e "nLines containing email addresses:"
grep -E "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+.[A-Z|a-z]{2,}b" "$file"
# 匹配并提取所有包含日期的行 (YYYY-MM-DD)
echo -e "nLines containing dates (YYYY-MM-DD):"
grep -E "bd{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])b" "$file"
# 匹配并提取所有以"Product:"开头的行,提取产品名称
echo -e "nProduct names:"
grep -E "^Product: (.+)$" "$file" | sed -E 's/^Product: (.+)$/1/'
# 匹配并提取包含特定关键字的行,并统计其出现次数
keyword="important_keyword"
echo -e "nLines containing the keyword '$keyword' and their count:"
grep -E "$keyword" "$file" | tee /dev/tty | wc -l
原文地址:https://blog.csdn.net/qq_44091004/article/details/135736259
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60056.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。