本文介绍: 打开pycharm安装成功会提示successfully。
Python网络通信
1、requests模块的使用
1.1、安装requests模块
pip install requests
打开pycharm
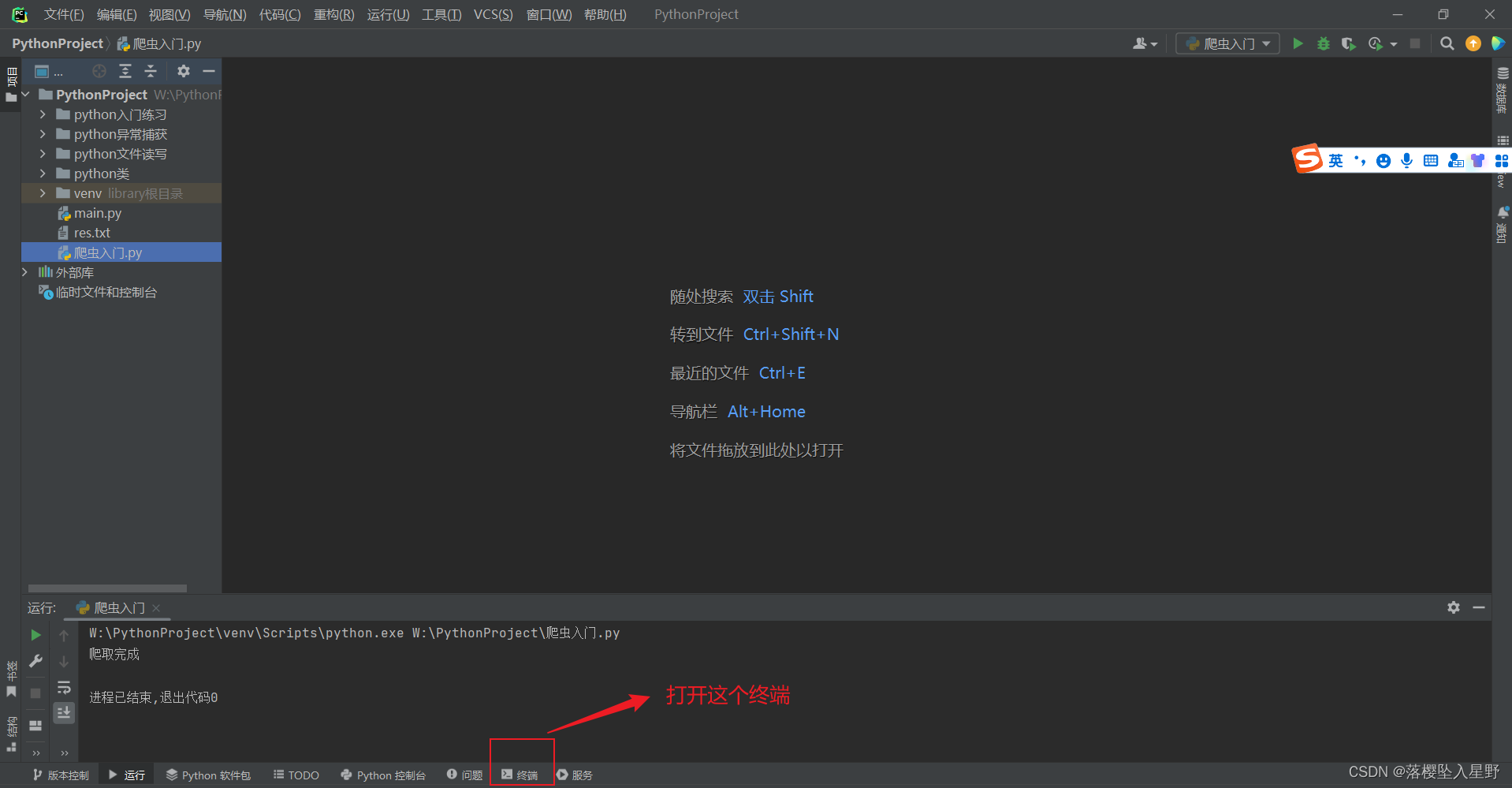
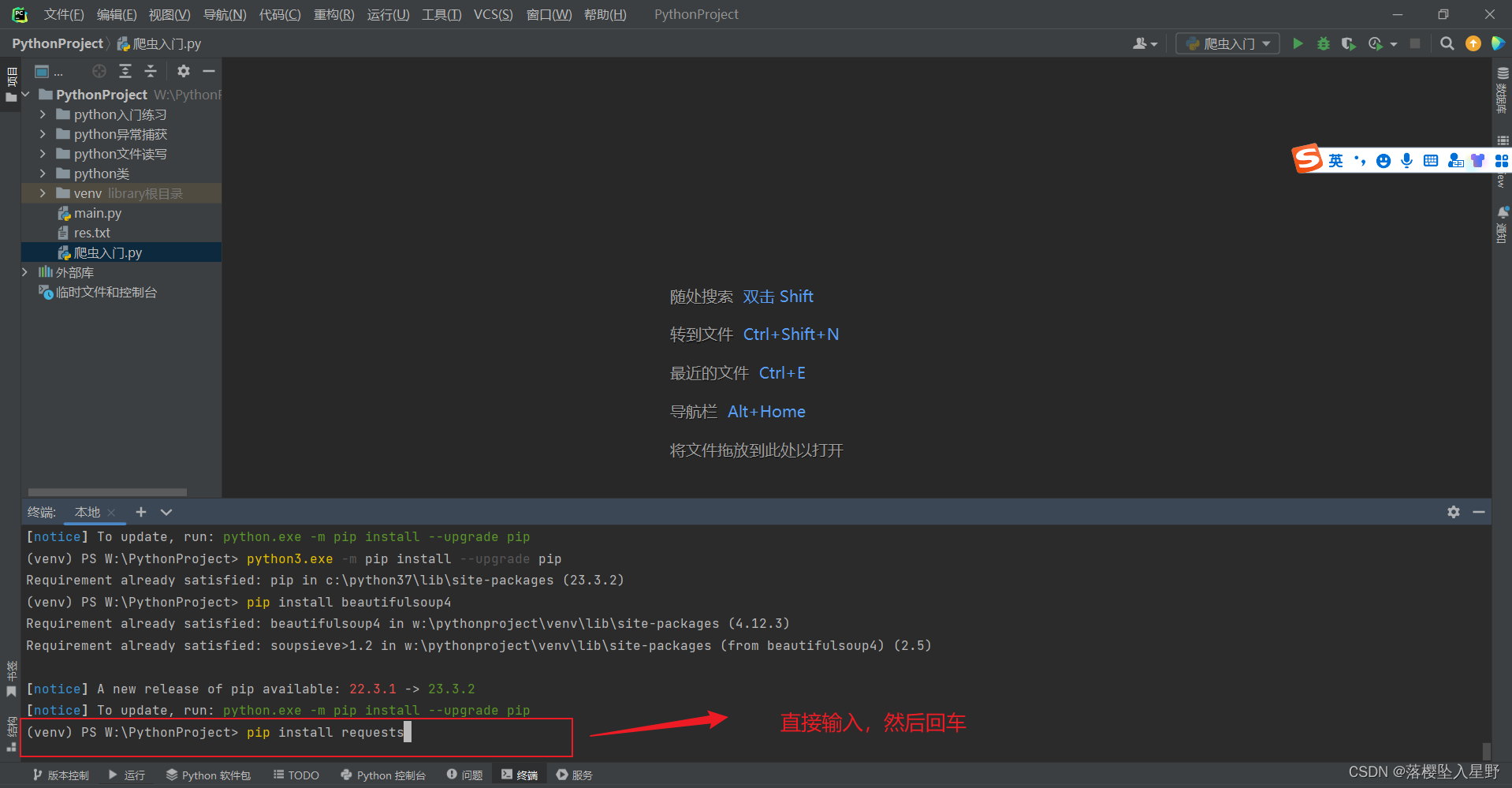
安装成功会提示successfully
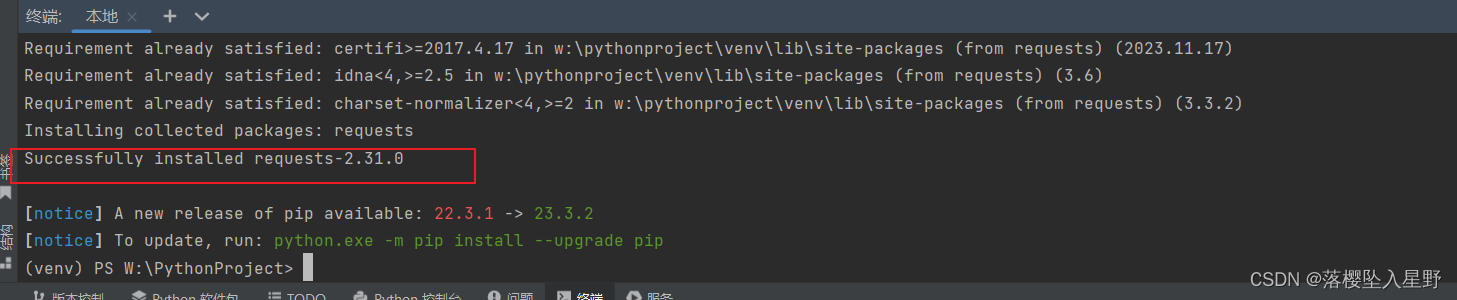
1.2、发送GET请求
-
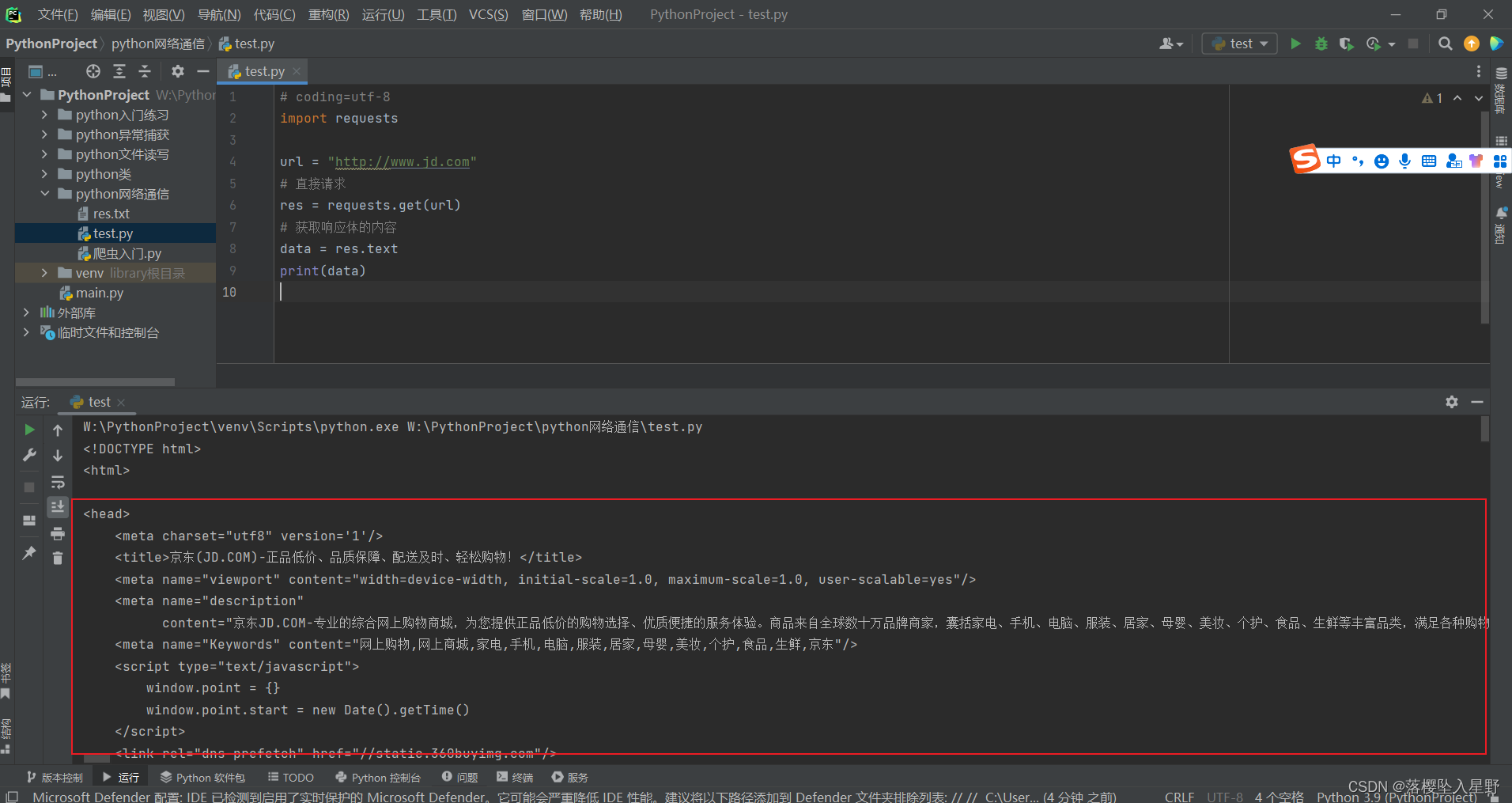
简单请求(以京东举例)
# coding=utf-8 import requests url = "http://www.jd.com" # 直接请求 res = requests.get(url) # 获取响应体的内容 data = res.text # 把结果打印出来(结合文件读取就可以爬取网页内容) print(data)运行结果
-
添加请求头(以百度举例)
为什么要添加请求头呢,因为有些网页在你请求的时候会检查你是否有请求头,如果没有请求头,就不会返回正常的内容,下面我来验证
创建两个python文件test01,test02
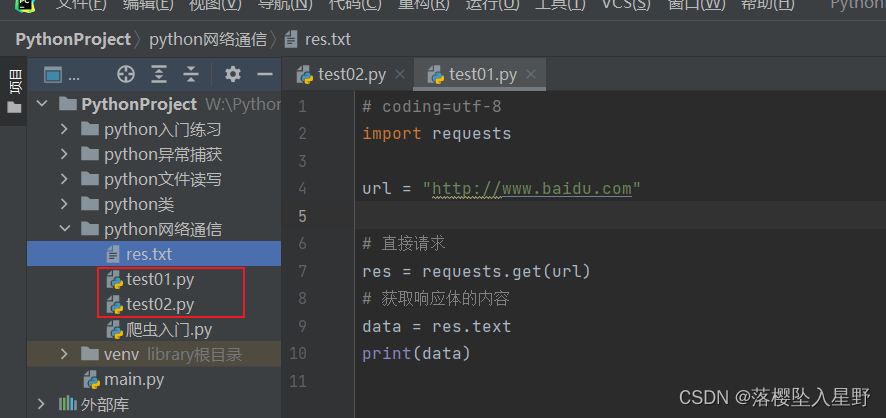
# test01 内容如下 # coding=utf-8 import requests url = "http://www.baidu.com" # 直接请求 res = requests.get(url) # 获取响应体的内容 data = res.text print(data)test01运行结果
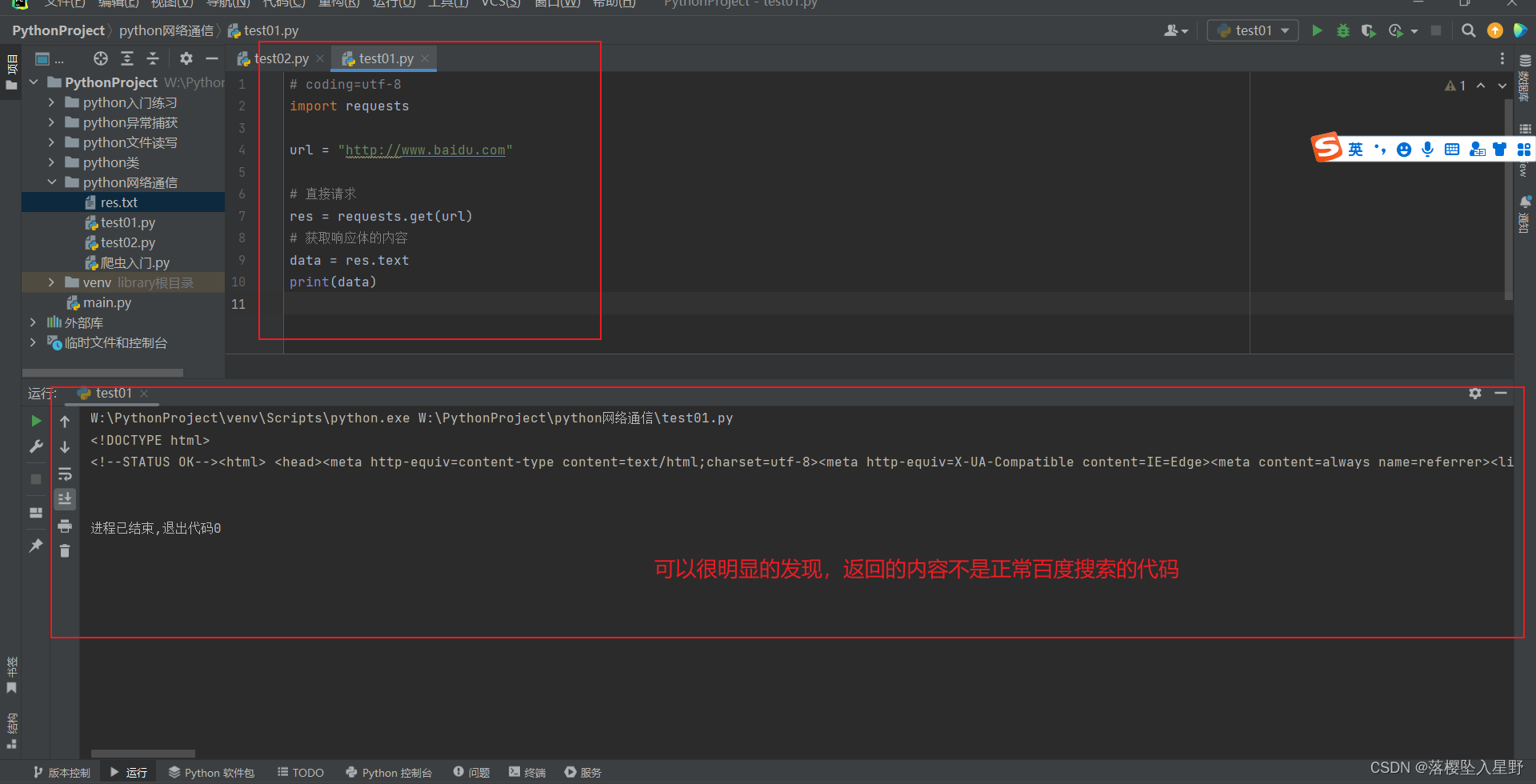
test02
# test02 内容如下 # coding=utf-8 import requests url = "http://www.baidu.com" header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 直接请求 res = requests.get(url, headers=header) # 获取响应体的内容 data = res.text print(data)test02运行结果
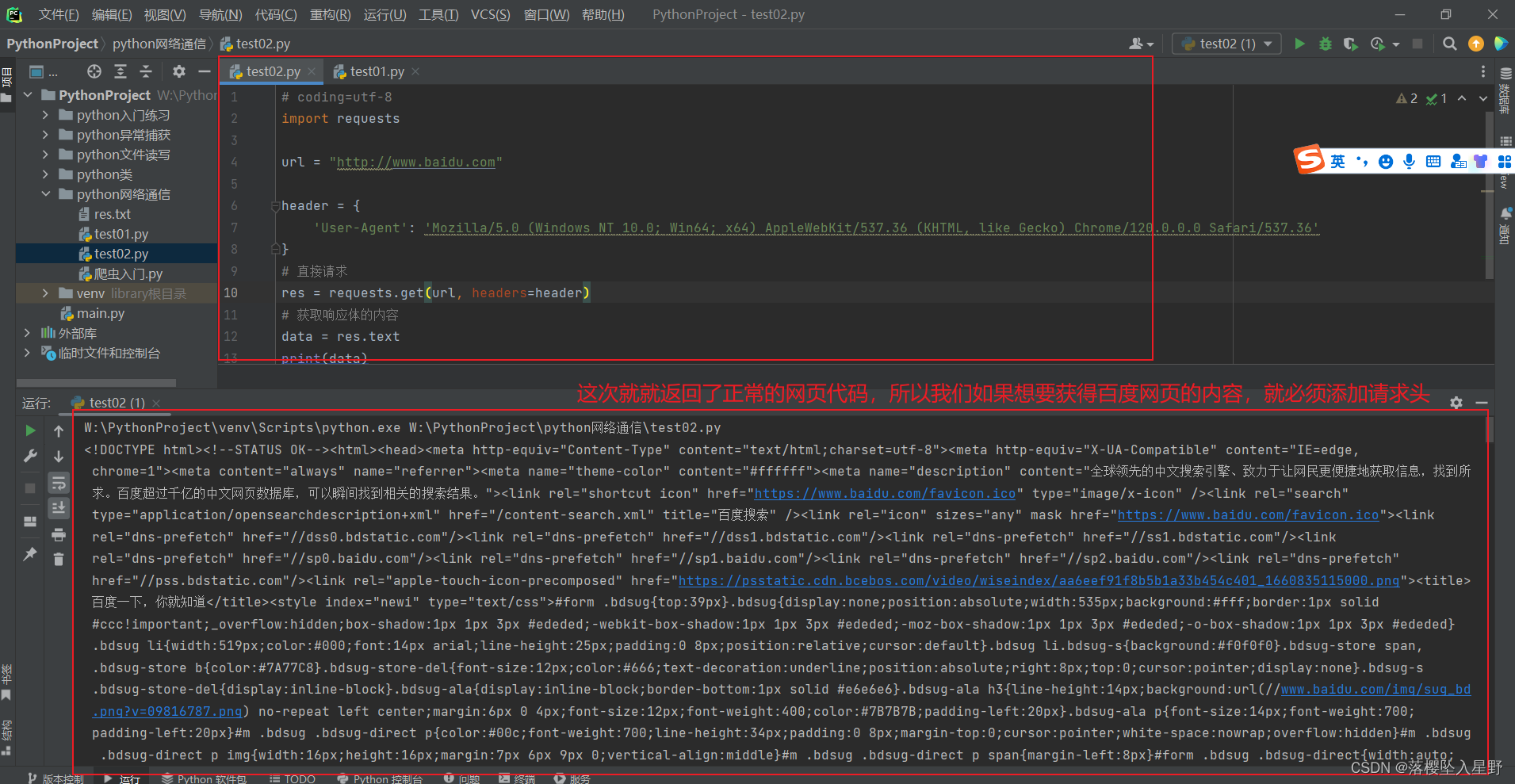
1.2.1请求头的获取
-
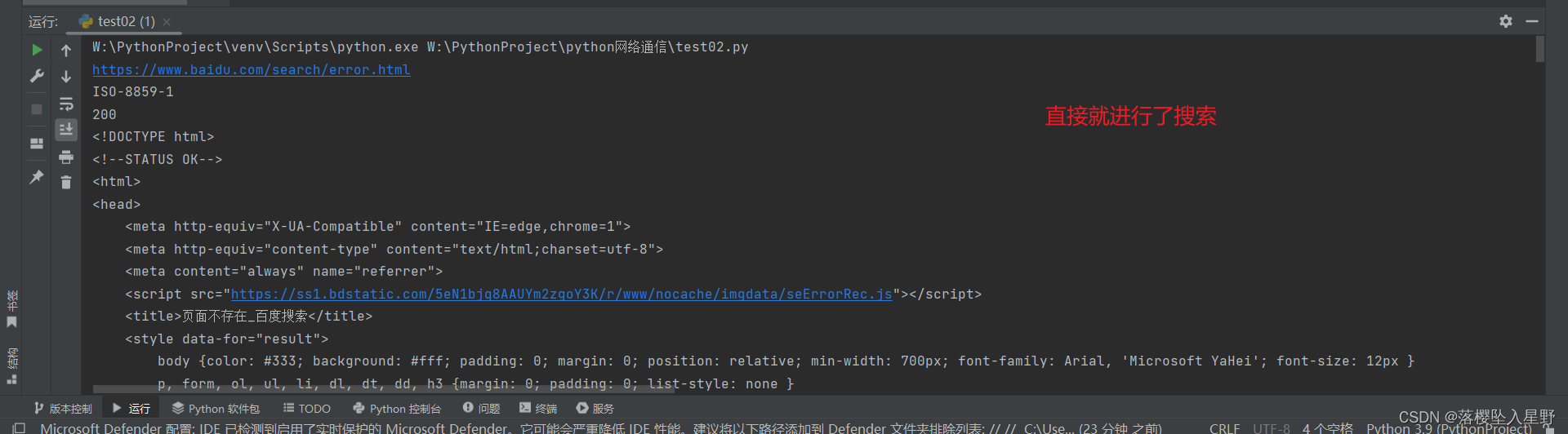
添加请求参数
# coding=utf-8 import requests url = "http://www.baidu.com" header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' } # 直接请求 res = requests.get(url=url, params=params, headers=header) # 直接在这里添加上面的定义的参数即可 # 获取响应体的内容 data = res.text print(data) -
响应字符编码设置
# coding=utf-8 import requests url = "http://www.baidu.com" # 请求头 header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 直接请求 res = requests.get(url=url, params=params, headers=header) # 获取响应体的内容 data = res.text print(data) # 如果乱码,可以设置响应数据的编码 print(res.content.decode("utf-8")) -
查看请求URL,响应编码,状态码
# coding=utf-8 import requests url = "http://www.gxaedu.com" # 请求头 header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 请求参数 params = { 'id': 10 } # 直接请求 res = requests.get(url=url, params=params, headers=header) # 查看完整的请求URL print(res.url) # 查看响应头编码 print(res.encoding) # 查看响应状态码 print(res.status_code) -
获取响应的cookie
有些网页要登录之后才能看到内容,所以要先注册一个账户,登录之后拿到自己的cookie去进行下一步操作
# coding=utf-8 import requests url = "http://www.baidu.com" # 请求头 header = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36' } # 请求参数(网页有参数采用参数,视具体情况来的) params = { 'id': 10 } # 直接请求 res = requests.get(url=url, params=params, headers=header) # 查看完整的请求URL print(res.url) # 查看响应头编码 print(res.encoding) # 查看响应状态码 print(res.status_code) # 获取响应cookie cookie_data = list(res.cookies) # 遍历获取cookie值 for cookie in cookie_data: print(cookie.value)
1.3、发送POST请求
和get一致,只是方法名字变成了post
# coding=utf-8
import requests
url = "http://www.baidu.com"
# 请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 请求参数
data = {
'wd': 'python'
}
# 直接请求
res = requests.post(url=url, headers=header, data=data)
# 查看完整的请求URL
print(res.url)
# 查看响应头编码
print(res.encoding)
# 查看响应状态码
print(res.status_code)
# 获取响应数据
print(res.content.decode("utf-8"))
1.4、挂代理(这个要自行学习科学上网,才能操作)
请求时,先将请求发给代理服务器,代理服务器请求目标服务器,然后目标服务器将数据传给代理服务器,代理服务器再将数据给爬虫。
直接请求:
# coding=utf-8
import requests
# 测试回显IP的地址
url = "http://httpbin.org/ip" # 这个网址可以返回自己的ip
# 请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 直接请求
res = requests.get(url=url, headers=header)
print(res.text)
结果:显示的是自己的IP
{
"origin": "xxx.xxx.xx.x"
}
利用代理请求:
# coding=utf-8
import requests
# 测试回显IP的地址
url = "http://httpbin.org/ip"
# 请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 使用代理
proxy = {
# 准备的代理地址
'http': 'http://xxx.xxx.xxx.xxx:端口号',
'https': 'http://xxx.xxx.xxx.xxx:端口号'
}
# 直接请求
res = requests.get(url=url, proxies=proxy, headers=header)
print(res.text)
1.5、简单爬虫实战
后续就可以进行简单的爬虫了,这个我会持续更新的
原文地址:https://blog.csdn.net/weixin_59047731/article/details/135756973
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_60989.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。


![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)


