本文介绍: 随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应用较为广泛的几个former架构。
随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应用较为广泛的几个former架构。
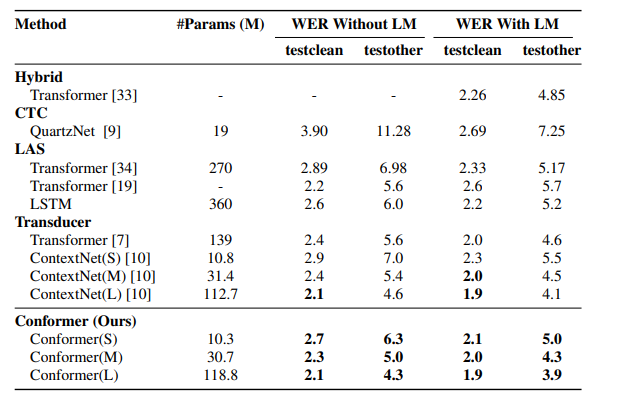
1. Conformer

💡 Motivation & Method
Transformer模型擅长获取基于内容的全局信息但是对高细粒度的局部特征效果不佳,而CNN擅长获取局部特征信息对于全局信息则需要更多的层。他们希望将CNN和Transformer优势结合起来对音频序列的局部和全局依赖关系进行建模。




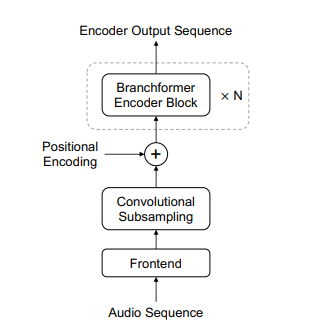
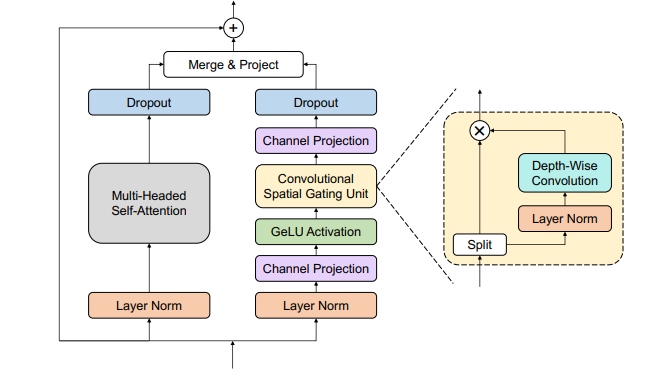
2. Branchformer


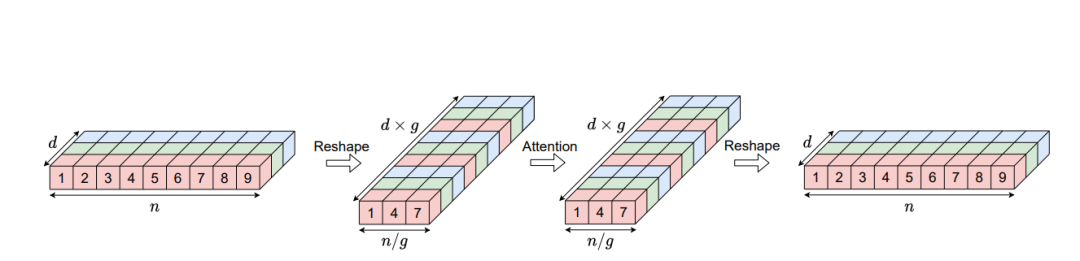
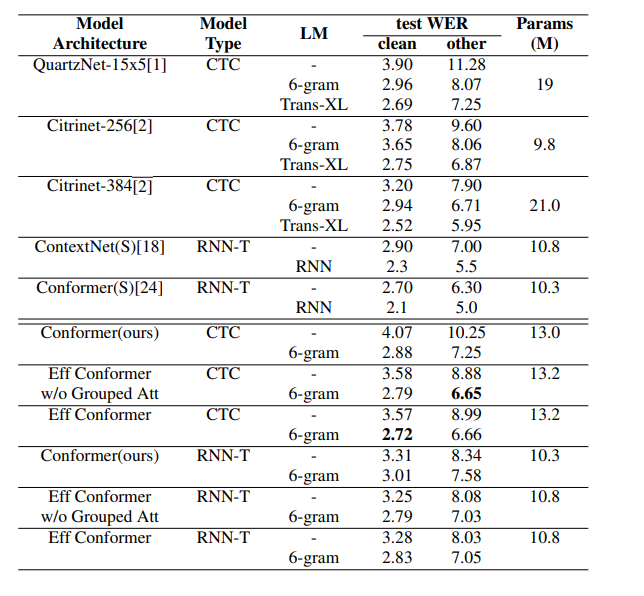
3. EfficientConformer



4. Squeezeformer




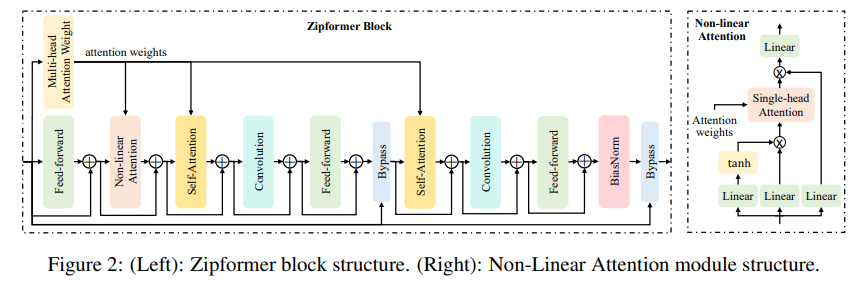
5. Zipformer




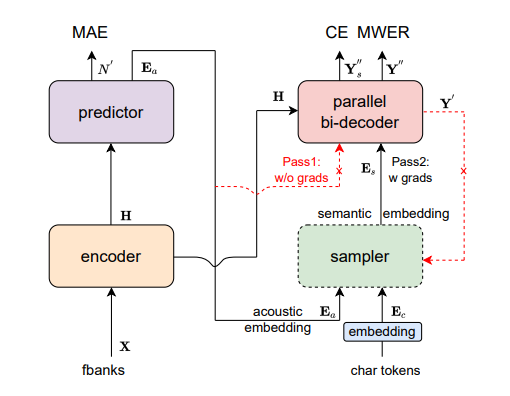
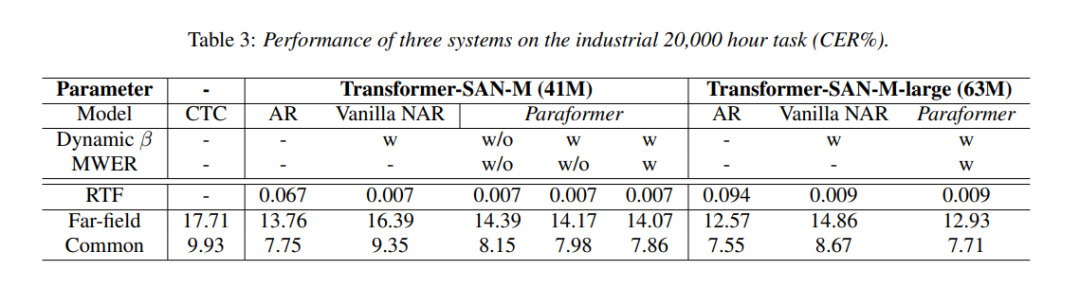
6. Paraformer



7. 总结
参考文献:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[全连接神经网络]Transformer代餐,用MLP构建图像处理网络](https://img-blog.csdnimg.cn/direct/bde5b15bef464542b6efbbfb84b05d86.png)

