温故而知新,可以为师矣!
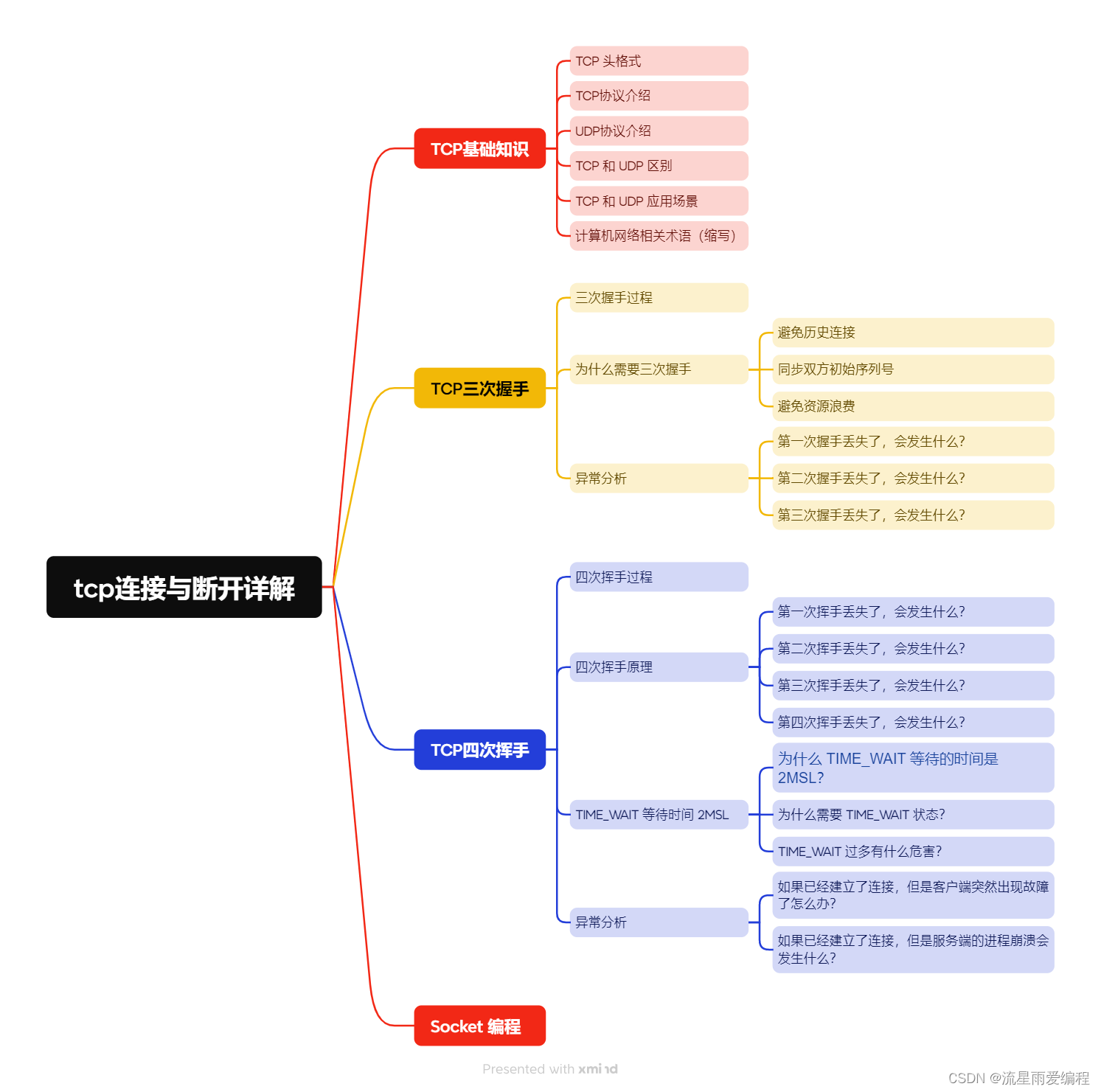
一、参考资料
深度学习笔记(二十三)Semantic Segmentation(FCN/U-Net/PSPNet/SegNet/U-Net++/ICNet/DFANet/Fast-SCNN)
二、FCN相关介绍
1. FCN简介
FCN(Fully Convolutional Networks),是利用深度学习进行语义分割的开山之作。FCN将传统的分类网络改造成分割网络:替换全连接层为卷积层,利用转置卷积的上采样获得高分辨率的语义特征图,输出feature map的每一维通道预测一个类别的分割结果。
FCN主要用来做 pixel-wise 的 image segmentation 预测,先用传统的CNN结构得到 feature map, 再将传统的 full connected 转换成了对应参数的卷积层。比如,传统pool5层的尺寸是7×7×512,fc6的尺寸是4096, full connected weight 是7×7×512×4096;将全连接层转成卷积层,kernel size 为7×7,input channel 为512,output channel 为4096,这就实现了将传统的网络(分别带有卷积层和全连接层)转成了全卷积网络(fully convolutional network, FCN)。简单理解,FCN全卷积网络就是全部都由卷积层构成的网络,没有FC层。
FCN的一个好处是输入图片尺寸可以任意,不受传统网络全连接层尺寸限制,传统的方法还要用类似SPP结构来避免这个问题。FCN中为了得到 pixel-wise 的prediction,也要把 feature map 通过转置卷积转化到像素空间。
2. FCN网络结构
FCN大致网络结构如下:

上图模型结构为针对VOC数据集的21个语义分割,即数据集包含21种不同分割类型。当图像进入神经网络,第一个卷积层将图像由三通道转换为96通道 feature map,第二个卷积层转换为256个通道,第三个卷积层384个通道,直到最后一个卷积层变为21个通道,每个通道对应不同分割类型。实际上,卷积层整个网络结构中卷积层的通道数可以根据不同任务进行调整,前面每经过一层会对图像进行一次宽高减半的下采样,经过5个卷积层以后,feature map 的尺寸为输入的1/32,最后通过转置卷积层将 feature map 宽高恢复到原始输入图像尺寸。
3. FCN网络结构分解
FCN模型结构可以根据分割细粒度使用FCN32s、FCN16s、FCN8s等结构,32s即从32倍下采样的 feature map 恢复到原始输入尺寸,16s和8s则是从16倍和8倍下采样恢复到原始输入尺寸,当然还可以使用4s、2s结构,数字越小使用的转置卷积层进行上采样越多,对应模型结构更加复杂,理论上分割的效果更精细。
3.1 FCN32s模型结构
FCN32s模型结构示意图:

3.2 FCN16s模型结构
FCN16s模型结构示意图:

3.3 FCN8s模型结构
FCN8s模型结构示意图:

4. FCN的特征融合(Add)
在FCN论文中,作者采用对 low-level 和 high-level 特征进行融合的方式。这是因为:
- 网络比较深的时候,特征图尺寸通常比较小,对这种特征图进行上采样,有很好的语义信息,但分辨率很差。
- 网络比较浅的时候,特征图尺寸通常比较大(接近input image),对这种特征图进行上采样,有很好的细节,但语义信息很差。
因此,对 low-level 和 high-level 特征进行融合,可以在得到很好的细节基础上,也能获得尽可能强的图像语义信息。
三、相关经验
(MindSpore)代码实现
图像语义分割网络FCN(32s、16s、8s)原理及MindSpore实现
(TensorFlow)代码实现
github代码:tensorflow-fcn
四、参考文献
原文地址:https://blog.csdn.net/m0_37605642/article/details/135813375
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_61657.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!