针对序列级和词元级应用微调BERT
我们为自然语言处理应用设计了不同的模型,例如基于循环神经网络、卷积神经网络、注意力和多层感知机。这些模型在有空间或时间限制的情况下是有帮助的,但是,为每个自然语言处理任务精心设计一个特定的模型实际上是不可行的。
原始BERT模型的两个版本分别带有1.1亿和3.4亿个参数。因此,当有足够的计算资源时,我们可以考虑为下游自然语言处理应用微调BERT。
下面,我们将自然语言处理应用的子集概括为序列级和词元级。在序列层次上,介绍了在单文本分类任务和文本对分类(或回归)任务中,如何将文本输入的BERT表示转换为输出标签。在词元级别,我们将简要介绍新的应用,如文本标注和问答,并说明BERT如何表示它们的输入并转换为输出标签。在微调期间,不同应用之间的BERT所需的“最小架构更改”是额外的全连接层。在下游应用的监督学习期间,额外层的参数是从零开始学习的,而预训练BERT模型中的所有参数都是微调的。
单文本分类
单文本分类将单个文本序列作为输入,并输出其分类结果。 除了我们在这一章中探讨的情感分析之外,语言可接受性语料库(Corpus of Linguistic Acceptability,COLA)也是一个单文本分类的数据集,它的要求判断给定的句子在语法上是否可以接受。例如,“I should study.”是可以接受的,但是“I should studying.”不是可以接受的。
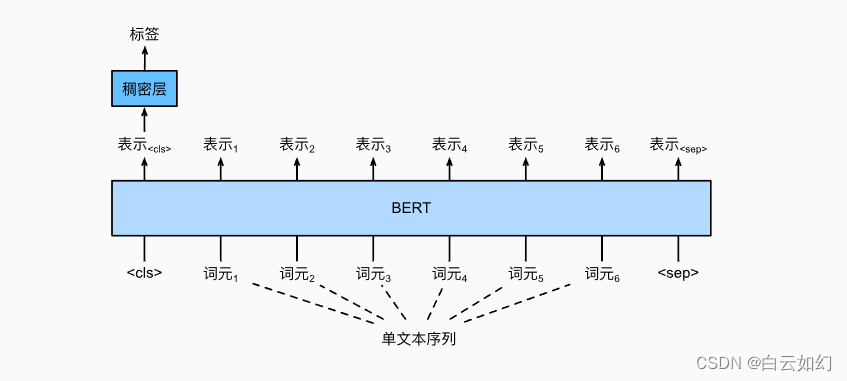
如上图所示,在单文本分类应用中,特殊分类标记“<cls>”的BERT表示对整个输入文本序列的信息进行编码。作为输入单个文本的表示,它将被送入到由全连接(稠密)层组成的小多层感知机中,以输出所有离散标签值的分布。
原文地址:https://blog.csdn.net/weixin_43227851/article/details/135857130
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63233.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






