今天来和大家聊聊Redis的主从架构以及Redis分区这两个知识点的内容。
Redis 主从架构
单机的 redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master–slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
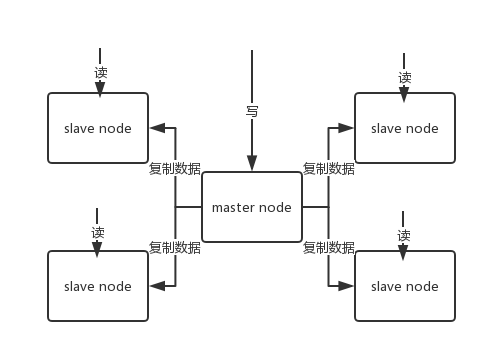
redis replication -> 主从架构 -> 读写分离 -> 水平扩容支撑读高并发
redis replication 的核心机制
redis 采用异步方式复制数据到 slave 节点,不过 redis2.8 开始,slave node 会周期性地确认自己每次复制的数据量;
一个 master node 是可以配置多个 slave node 的;
slave node 也可以连接其他的 slave node;
slave node 做复制的时候,不会 block master node 的正常工作;
slave node 在做复制的时候,也不会 block 对自己的查询操作,它会用旧的数据集来提供服务;但是复制完成的时候,需要删除旧数据集,加载新数据集,这个时候就会暂停对外服务了;
slave node 主要用来进行横向扩容,做读写分离,扩容的 slave node 可以提高读的吞吐量。
注意,如果采用了主从架构,那么建议必须开启 master node 的持久化,不建议用 slave node 作为 master node 的数据热备,因为那样的话,如果你关掉 master 的持久化,可能在 master 宕机重启的时候数据是空的,然后可能一经过复制, slave node 的数据也丢了。
另外,master 的各种备份方案,也需要做。万一本地的所有文件丢失了,从备份中挑选一份 rdb 去恢复 master,这样才能确保启动的时候,是有数据的,即使采用了后续讲解的高可用机制,slave node 可以自动接管 master node,但也可能 sentinel 还没检测到 master failure,master node 就自动重启了,还是可能导致上面所有的 slave node 数据被清空。
redis 主从复制的核心原理
当启动一个 slave node 的时候,它会发送一个 PSYNC 命令给 master node。
如果这是 slave node 初次连接到 master node,那么会触发一次 full resynchronization 全量复制。此时 master 会启动一个后台线程,开始生成一份 RDB 快照文件,
同时还会将从客户端 client 新收到的所有写命令缓存在内存中。RDB 文件生成完毕后, master 会将这个 RDB 发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中,
接着 master 会将内存中缓存的写命令发送到 slave,slave 也会同步这些数据。
slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
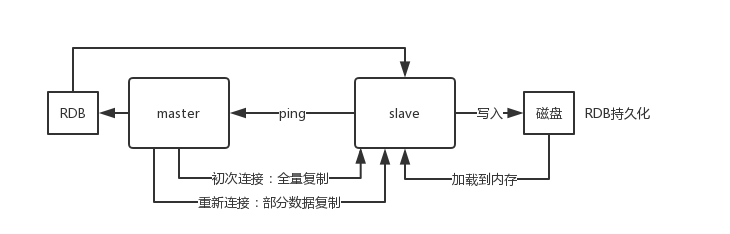
过程原理
当从库和主库建立MS关系后,会向主数据库发送SYNC命令
主库接收到SYNC命令后会开始在后台保存快照(RDB持久化过程),并将期间接收到的写命令缓存起来
当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis
从Redis接收到后,会载入快照文件并且执行收到的缓存的命令
之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致
缺点
所有的slave节点数据的复制和同步都由master节点来处理,会照成master节点压力太大,使用主从从结构来解决
Redis集群的主从复制模型是怎样的?
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品
生产环境中的 redis 是怎么部署的?
redis cluster,10 台机器,5 台机器部署了 redis 主实例,另外 5 台机器部署了 redis 的从实例,每个主实例挂了一个从实例,5 个节点对外提供读写服务,每个节点的读写高峰qps可能可以达到每秒 5 万,5 台机器最多是 25 万读写请求/s。
机器是什么配置?
32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 redis 进程的是10g内存,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
你往内存里写的是什么数据?
每条数据的大小是多少?商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。
其实大型的公司,会有基础架构的 team 负责缓存集群的运维。
说说Redis哈希槽的概念?
Redis集群没有使用一致性hash,而是引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,集群的每个节点负责一部分hash槽。
Redis集群会有写操作丢失吗?为什么?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
Redis集群之间是如何复制的?
异步复制
Redis集群最大节点个数是多少?
16384个
Redis集群如何选择数据库?
Redis集群目前无法做数据库选择,默认在0数据库。
Redis 分区
Redis是单线程的,如何提高多核CPU的利用率?
可以在同一个服务器部署多个Redis的实例,并把他们当作不同的服务器来使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下分片(shard)。
为什么要做Redis分区?
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
有哪些Redis分区实现方案?
客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
Redis分区有什么缺点?
涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
同时操作多个key,则不能使用Redis事务.
分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)
当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
分布式问题
Redis实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。
当且仅当 key 不存在,将 key 的值设为 value。 若给定的 key 已经存在,则 SETNX 不做任何动作
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
原文地址:https://blog.csdn.net/weixin_44797327/article/details/134676214
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6353.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!