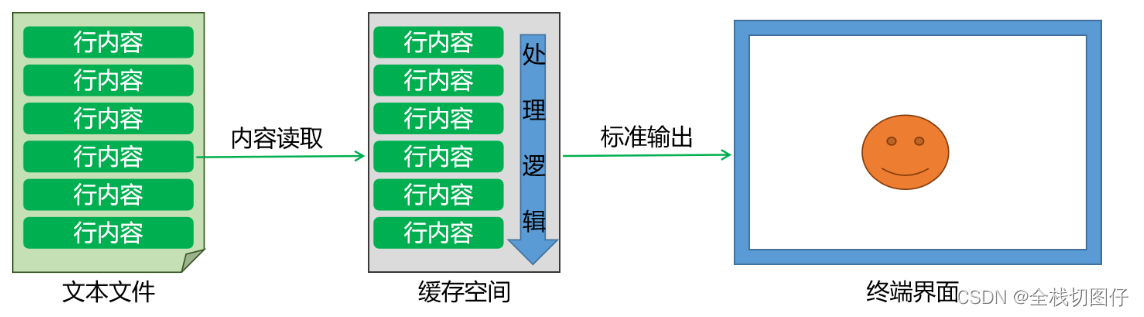
今日内容
sed 替换,取行 (增删查改)
grep
sed
awk
sed命令选项
| 选项 | 含义 | |
|---|---|---|
| -n | 取消默认输出,sed操作文件的时候会默认把每一行输出到屏幕 | |
| -r | sed可以支持选择正则,sed支持扩展正则 | |
| -i | sed修改文件内容(危险),不进行输出 | |
| -i.bak | 先对文件进行备份以.bak为结尾,然后源修改文件的内容 |
| sed的指令 | |
|---|---|
| p | print输出/显示 |
| s | sub替换 |
| d | del删除 |
| cai | a append在指定行后追加一行. |
| i insert在指定行上面插入一行. | |
| c replace替换,把指定行内容替换成… |
sed的查找功能
- 找行
- 找行(根据内容查找)
1)案例1 查找文件的第2行
[root@hb-sre-001 hb]# sed -n '2p' sed.txt
102,zhangya,CTO
-n: 取消sed默认输出
p:sed指令,print 显示/输出
2)案例2 查找文件中包含oldboy的行(类似egrep)
[root@hb-sre-001 hb]# sed -n '/oldboy/p' sed.txt
101,oldboy,CEO
[root@hb-sre-001 hb]#
3)案例3 过滤出文件中包含oldboy或lidao的行
[root@hb-sre-001]sed -rn '/oldboy|lidao/p' sed.txt
101,oldboy,CEO
103,lidao996,COO
110,lidao,COCO
-r sed 可以支持扩展正则,sed支持基础正则
4)案例4 过滤出文件从第2行到第5行的内容
[root@hb-sre-001 hb]# sed -n '2,5p' sed.txt
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
5)过滤出文件中包含101的行到105的行(范围)
[root@hb-sre-001 hb]# sed -n '/101/,/105/p' sed.txt
101,oldboy,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
看到题目是从哪里到哪里,并知道行号就用’,p’
看到是包含就’//p’
6)sed命令小结
- 格式:
sed -n '???p' sed.txt - sed查找中可用条件:
- 行号:
sed -n '2p' sed.txt - 行号范围:
sed -n '2,5p' sed.txt - 模糊匹配:
sed -n '/支持正则/p' sed.txt #使用扩展正则加上-r即可. - 模糊化过滤表示范围:
sed -n '/从哪里来/,/到哪里去/p' sed.txt
- 行号:
sed的替换功能
- 目标:能够把文件内容进行替换与修改即可
1)案例01 把文件中oldboy替换为oldgirl
s###g
[root@hb-sre-001 hb]# sed -i 's#oldboy#oldgirl#g' sed.txt
[root@hb-sre-001 hb]# cat sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
3)sed替换功能小结
sed 's###g' sed.txt###- `@@@
///- .bak 修改内容前进行备份.
sed的替换功能之反向引用
*目标:取出ip地址,任何想要的内容
1)#后面##之间想调用,前面两个##之间的内容,叫后向引用
[root@hb-sre-001 hb]# echo 123456
123456
[root@hb-sre-001 hb]# echo '<123456>'
<123456>
[root@hb-sre-001 hb]# echo 123456 |sed -r 's#(.*)#<1>#g'
<123456>
# 反向引用使用流程:
# .*表示0或1以上的字符,也即是(123456)
# 先把你要的内容通过正则....匹配出来并加上() 保护(分组1.2.3....)
# sed 后面2个##之间调用(引用) 1 2 3 ...
# 1表示前面括号的内容,1=123456
# 如果想匹配数字部分,更加精确,反向引用的一般需要修改正则部分即可
# 如果只给数字两边加上<>
[root@hb-sre-001 hb]# echo {1..10}
1 2 3 4 5 6 7 8 9 10
[root@hb-sre-001 hb]# echo {1..10} |sed -r 's#([0-9])#<1>#g'
<1> <2> <3> <4> <5> <6> <7> <8> <9> <1><0>
[root@hb-sre-001 hb]# echo {1..10} |sed -r 's#([0-9]+)#<1>#g'
<1> <2> <3> <4> <5> <6> <7> <8> <9> <10>
反向引用:取出某一行的某部分内容
先把你要的内容保护起来(通过()小括号,括起来,然后在sed命令中通过1取出)
#1
[root@hb-sre-001 hb]# ip a s ens33|sed -n '3p'|sed -r 's#^.*et (.*)/.*$#1#g'
10.0.0.100
3)案例3:调换/etc/passwd第1列和最后一列
[root@hb-sre-001 hb]# sed -r 's#(^.*)(:x.*:)(.*)#321#g' passwd
/bin/bash:x:0:0:root:/root:root
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
/sbin/nologin:x:3:4:adm:/var/adm:adm
/sbin/nologin:x:4:7:lp:/var/spool/lpd:lp
/bin/sync:x:5:0:sync:/sbin:sync
/sbin/shutdown:x:6:0:shutdown:/sbin:shutdown
/sbin/halt:x:7:0:halt:/sbin:halt
/sbin/nologin:x:8:12:mail:/var/spool/mail:mail
/sbin/nologin:x:11:0:operator:/root:operator
/sbin/nologin:x:12:100:games:/usr/games:games
/sbin/nologin:x:14:50:FTP User:/var/ftp:ftp
/sbin/nologin:x:99:99:Nobody:/:nobody
/sbin/nologin:x:192:192:systemd Network Management:/:systemd-network
/sbin/nologin:x:81:81:System message bus:/:dbus
/sbin/nologin:x:999:998:User for polkitd:/:polkitd
/sbin/nologin:x:74:74:Privilege-separated SSH:/var/empty/sshd:sshd
/sbin/nologin:x:89:89::/var/spool/postfix:postfix
/sbin/nologin:x:998:996::/var/lib/chrony:chrony
4)sed反向引用功能小结
- 用于取出某行你想要内容
- 案例ip
- 案例调换位置
sed删除功能
- d–>delete 删除,以行为单位删除
1)案例:删除文件的第3行
[root@oldboy81-golden-lnb /oldboy]# sed '3d' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@oldboy81-golden-lnb /oldboy]# sed '1,3d' sed.txt
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
2)删除oldboy或lidao的行
root@oldboy81-golden-lnb /oldboy]# sed -r '/oldboy|lidao/d' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
104,yy,CFO
105,feixue,CIO
3)企业生产案例 去掉/etc/ssh/sshd_config文件中的空行或注释行.
cp /etc/ssh/sshd_config .
#方法01 egrep
egrep -v '^$|^#' sshd_config
#方法02 sed
sed -r '/^$|^#/d' sshd_config
#方法03 awk 了解
awk '! /^$|^#/' sshd_config
#方法04 grep/sed/awk 这个文件以字母开头的行(非空行或注释行)
grep '^[a-Z]' sshd_config
sed的增加功能
- a append 类似>>追加重定向
- cai(菜)
sed总结
- sed命令执行过程
- sed查询功能
- sed替换功能
- sed替换功能反向引用
- sed删除功能
- sed增加功能
复盘
#三剑客
grep 过滤,过滤速度快
sed 过滤,替换,查找行(行号,范围),增删查改查
awk 过滤,取列,计算(小数)
awk内容
awk 格式
awk 执行流程
awk 取行
awk 取列
awk 过滤(条件)
awk 特殊条件(用于计算)
- 目标:
- 近期:使用awk继续过滤,取行,取列
- 长远:使用awk进行过滤,取行,取列,统计计算
- 第3个阶段:shell,python,awk判断,循环,数组
2)awk格式:
#取出/etc/passwd 第1行的第1列和第3列
awk -F: 'NR==1{print $1,$3}' /etc/passwd
awk 选项 '条件{动作}' /etc/passwd
条件: 哪一行,过滤什么内容
动作: print输出与显示 ,计算....
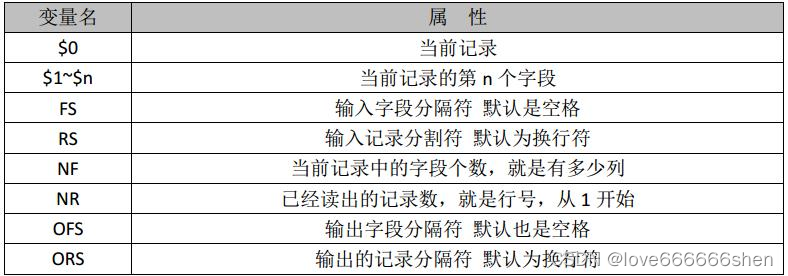
NR==1---->第一行
{输出第1列,第3列}
awk执行流程

awk取行
- 与sed类似
1)案例01 取出sed.txt的第2行
awk 'NR==2' sed.txt
102,zhangya,CTO
# NR awk内置变量
# NR Number of record
2)案例02 取出sed.txt中包含oldboy或lidao的行
[root@hb-sre-001 hb]# sed -rn '/oldboy|lidao/p' sed.txt
103,lidao996,COO
110,lidao,COCO
[root@hb-sre-001 hb]# awk '/oldboy|lidao/' sed.txt
103,lidao996,COO
110,lidao,COCO
3)案例03 取出文件第2行到第5行内容
awk '行号大于2 并且行号 小于等于5' sed.txt
[root@hb-sre-001 hb]# awk 'NR>=2 && NR<=5' sed.txt
102,zhangya,CTO
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
&& 表示并且
4)案例04 取出文件第3行到最后一行内容
[root@hb-sre-001 hb]# awk 'NR>=3' sed.txt
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
[root@hb-sre-001 hb]# sed -n '3,$p' sed.txt
103,lidao996,COO
104,yy,CFO
105,feixue,CIO
110,lidao,COCO
4)案例05 取出从包含old的行到lidao的行
[root@hb-sre-001 hb]# sed -n '/old/,/lidao/p' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
[root@hb-sre-001 hb]# awk '/old/,/lidao/' sed.txt
101,oldgirl,CEO
102,zhangya,CTO
103,lidao996,COO
6)取行小结
- awk中条件,如何找出想要的行
- 条件:
- 指定行号: NR==1
- 指定行号范围 NR>=3 或 NR>=3 && NR<=5
- 过滤:/oldboy|lidao/
- 范围过滤:/oldboy/,/lidao/
awk取列
- 目标:熟练取出指定的内容或部分(取列)
1)案例01:取出ls -lh命令中的第1列和第3列
[root@hb-sre-001 hb]# ll -lh|awk '{print $1,$3}'
总用量 20K
-rw-r--r--. 1 root root 0 8月 2 16
drwxr-xr-x. 2 root root 166 8月 3 12
-rw-r--r--. 1 root root 254 8月 2 10
-rw-r--r--. 1 root root 846 8月 14 17
-rw-r--r--. 1 root root 249 8月 8 01
-rw-r--r--. 1 root root 90 8月 14 15
-rw-r--r--. 1 root root 19 8月 10 14
- 注意:awk中$数字只有一个意思,取列。
2)案例02:取出/etc/passwd每一行内容,加上行号
## 方法01
cat -n passwd
[root@hb-sre-001 hb]# cat -n passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
## 方法02
[root@hb-sre-001 hb]# awk '{print NR,$0}' passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 games:x:12:100:games:/usr/games:/sbin/nologin
12 ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
13 nobody:x:99:99:Nobody:/:/sbin/nologin
14 systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
15 dbus:x:81:81:System message bus:/:/sbin/nologin
16 polkitd:x:999:998:User for polkitd:/:/sbin/nologin
17 sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
18 postfix:x:89:89::/var/spool/postfix:/sbin/nologin
19 chrony:x:998:996::/var/lib/chrony:/sbin/nologin
NR 表示行号。
$0 表示一整行内容。
3)取出passwd 第1列和第3列
- awk取列的,默认以空格,连续空格或tab键分割,只需要使用$1,$3,$6…即可取出
- 如果想更改或者指定新的分隔符,需要使用
-F选项指定分隔符 - -F 指定分隔符,-F指定正则
[root@hb-sre-001 hb]# awk '{print $1,$3}' passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP
nobody:x:99:99:Nobody:/:/sbin/nologin
systemd-network:x:192:192:systemd Management:/:/sbin/nologin
dbus:x:81:81:System bus:/:/sbin/nologin
polkitd:x:999:998:User polkitd:/:/sbin/nologin
sshd:x:74:74:Privilege-separated
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
:为分隔符
[root@hb-sre-001 hb]# awk -F ':' '{print $1,$3}' passwd
root 0
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 99
systemd-network 192
dbus 81
polkitd 999
sshd 74
postfix 89
chrony 998
4)案例04 取出ip.txt文件中ip(10.0.0.200)地址
- awk中指定多个分隔符,需要使用正则匹配多个分隔符即可。
echo 'inet 10.0.0.200/24 brd 10.0.0.255 scope global ens33' >/hb/ip.txt
# 方法01 多个管道
(1)awk取第2列
(2)awk指定分隔符取第1列
awk '{print $2}' ip.txt |awk -F '/' '{print $1}'
# 方法02 awk直接取出 指定多个分隔符
awk -F 'inet |/24' '{print $2}' ip.txt
10.0.0.200
[root@hb-sre-001 hb]# awk -F '[ /]+' '{print $2}' ip.txt
10.0.0.200
先用正则匹配出连续出现的空格或/ 然后交给awk -F作为分隔符
# 方法03
5)案例05 取出passwd第1列,第3列和最后一列
- $NF 最后一列
- NF Number of field 每行有多少个字段
[root@hb-sre-001 hb]# awk -F ':' '{print $1,$3,$NF}' passwd
root 0 /bin/bash
bin 1 /sbin/nologin
daemon 2 /sbin/nologin
adm 3 /sbin/nologin
lp 4 /sbin/nologin
sync 5 /bin/sync
shutdown 6 /sbin/shutdown
halt 7 /sbin/halt
mail 8 /sbin/nologin
operator 11 /sbin/nologin
games 12 /sbin/nologin
ftp 14 /sbin/nologin
nobody 99 /sbin/nologin
systemd-network 192 /sbin/nologin
dbus 81 /sbin/nologin
polkitd 999 /sbin/nologin
sshd 74 /sbin/nologin
postfix 89 /sbin/nologin
chrony 998 /sbin/nologin
6)awk取列小结
- 一般配合
'{print NR,$1,$3,$NF}' - NR行号,$内容,某一列
- $NF最后一列
- $0 表示一整行
- 案例:
- 取默认的列
- 取指定分隔符,指定分隔符使用正则
- 取列核心:使用-F指定分隔符
- 建议:以你目标两边的内容作为分隔符即可,可以是单个字符,也可以是单词。
awk行与列综合(awk过滤进阶)
1)精确过滤必备
- awk可以完成,某一列中包含/不包含内容…
- $3 ~ //匹配或包含
- $3 !~ //不匹配或不包含
格式:
awk -F: '第3列 包含 以1或2开头的内容' passwd
[root@hb-sre-001 hb]# awk -F ':' '$3 ~ /^[12]/' passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
2)案例01 过滤出passwd中第3列以0到3结尾的,显示第1列和第3列内容
条件:第3列以0到3结尾(取行)
动作:显示第1列和第3列内容(取列)
# 方法01
[root@hb-sre-001 hb]# awk -F ':' '$3 ~ /[0-3]$/' passwd |awk -F ':' '{print $1,$3}'
root 0
bin 1
daemon 2
adm 3
operator 11
games 12
systemd-network 192
dbus 81
# 方法02 awk同时取行和取列
awk -F: 'NR==1 {print $1,$3}' passwd
awk 选项 '条件{动作}' passwd
awk -F ':' '$3 ~ /[0-3]$/ {print $1,$3}' passwd
root 0
bin 1
daemon 2
adm 3
operator 11
games 12
systemd-network 192
dbus 81
2)案例02:过滤passwd中第3列大于0小于1000内容,显示第1列和第3列
awk -F ':' '$3>0 && $3<1000 {print $1,$3}' passwd |column -t
bin 1
daemon 2
adm 3
lp 4
sync 5
shutdown 6
halt 7
mail 8
operator 11
games 12
ftp 14
nobody 99
systemd-network 192
dbus 81
polkitd 999
sshd 74
postfix 89
chrony 998
4)案例03:过滤出网卡配置文件中的ip地址
# 如果要求中没有明确写出条件(eg,行号,过滤包含...)
# 需要查看文件内容分析,(使用固定行号,过滤XXX内容)
# 条件: 方法01:取出第16行
方法02:过滤包含IPADDR=的行
动作:
显示第2列(以=分割)
# 方法01:
[root@hb-sre-001 hb]# cat -n /etc/sysconfig/network-scripts/ifcfg-ens33
1 TYPE=Ethernet
2 PROXY_METHOD=none
3 BROWSER_ONLY=no
4 BOOTPROTO=static
5 DEFROUTE=yes
6 IPV4_FAILURE_FATAL=no
7 NAME=ens33
8 UUID=3f9d7f21-034c-4849-9f1d-c12ad1e642cb
9 DEVICE=ens33
10 ONBOOT=yes
11 IPADDR=10.0.0.100
12 GATEWAY=10.0.0.2
13 DNS=114.114.114.114
14 NETMASK=255.255.255.0
[root@hb-sre-001 hb]# awk -F= 'NR==11 {print $2}' /etc/sysconfig/network-scripts/ifcfg-ens33
10.0.0.100
# 方法02
awk -F '=' '/IPADDR=/ {print $2}' /etc/sysconfig/network-scripts/ifcfg-ens33
10.0.0.100
sed
# 方法1:
[root@hb-sre-001 hb]# sed -n '11p' /etc/sysconfig/network-scripts/ifcfg-ens33|sed 's#^.*=##g'
10.0.0.100
[root@hb-sre-001 hb]# sed -n '11 s#^.*=##g p' /etc/sysconfig/network-scripts/ifcfg-ens33
10.0.0.100
5)awk过滤进阶小结
- awk可以精确到某一行的某一列进行过滤
- 格式:
awk -F指定分隔符 '某一列包含xxx内容' awk -F ':' '$3 ~ /[0-3]$/' passwd- $NF表示最后一列
awk常见环境变量
| 环境变量 | |
|---|---|
| NR | 行号 |
| NF | 每行有多少列 |
| $NF | 表示最后一列 |
| $数字 | $1,$2 取出某一列或某几列,一般配合-F一起使用 |
| $0 | 每行的所有列(一整行内容) |
| FS | field separator 字段分隔符,-F背后修改的内容 |
awk统计计算功能
1)BEGIN{}和END{}
- awk中的特殊的条件
- 这两个特殊的条件,都与计算相关,最常用的是END{}
| 特殊条件 | 含义 | 应用场景 |
|---|---|---|
| BEGIN{} | BEGIN{}内容会在awk读取文件之前执行 | 1.里面进行实验 2.记性计算不需要读取文件内容 3.创建或修改awk变量 |
| END{} | END{}内容会在awk读取文件之后执行 | 1.awk在读取文件的时候进行统计和计算,最后统计完成在END{}输出最终结果 |
2)BEGIN{}了解
# 计算1/3
awk 'BEGIN{print 1/3}'
0.333333
修改awk的变量
3)END{}熟练掌握
a)案例01 统计passwd的行数
#条件:无
#动作:i++ #统计次数,类似于wc -l
#输出最后i内容
[root@hb-sre-001 hb]# awk '{i++} END{print i}' passwd
19
[root@hb-sre-001 hb]# wc -l /etc/passwd
19 /etc/passwd
i=i+1 === i++ #功能用于计数,统计有多少次,一共出现的次数...类似于wc -l
b)案例02 统计passwd中可登录用户数量
#条件:命令解释器是bash
#动作:i++
#最后输出数量
END{print i}
awk '/bash$/ {i++} END{print i}' passwd
1
c)案例03 统计services文件中空行的数量
#条件:过滤 空行 ^$
#动作:i++ #统计次数
#输出最后数量
[root@hb-sre-001 hb]# awk '/^$/ {i++} END{print i}' /etc/services
17
d)案例04 生产工作案例,统计access.log中一共用了多少流量
[root@hb-sre-001 hb]# awk '{sum=sum+$1} END{print sum}' liu.log
616.5
[root@hb-sre-001 hb]# awk '{sum=sum+$10} END{print sum/1024/1024/1024"GB"}' access.log
2.30828GB
4)awk统计计算小结
- BEGIN{}了解含义即可,未来主要用于计算,不需要加上文件
- END{}用于awk先进行计算,最后END{}输出最后结果
awk总结
- awk格式
- awk执行流程
- awk取行
- awk取列
- awk过滤进阶(取行与取列)
- awk统计功能,END,统计次数,统计总和(累加)
- 未来:
- awk统计计算进阶,awk数组
- awk判断,循环
原文地址:https://blog.csdn.net/Binbinhb/article/details/135964756
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_63991.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!