本文介绍: 在过去的几个月里,生成式人工智能领域出现了许多令人兴奋的新进展。ChatGPT 于 2022 年底发布,席卷了人工智能世界。作为回应,各行业开始研究大型语言模型以及如何将其纳入其业务中。然而,在医疗保健、金融和法律行业等敏感应用中,ChatGPT 等公共 API 的隐私一直是一个问题。然而,最近 Falcon 和 LLaMA 等开源模型的创新使得从开源模型中获得类似 ChatGPT 的质量成为可能。这些模型的好处是,与 ChatGPT 或 GPT-4 不同,模型权重适用于大多数商业用例。
在过去的几个月里,生成式人工智能领域出现了许多令人兴奋的新进展。 ChatGPT 于 2022 年底发布,席卷了人工智能世界。 作为回应,各行业开始研究大型语言模型以及如何将其纳入其业务中。 然而,在医疗保健、金融和法律行业等敏感应用中,ChatGPT 等公共 API 的隐私一直是一个问题。
然而,最近 Falcon 和 LLaMA 等开源模型的创新使得从开源模型中获得类似 ChatGPT 的质量成为可能。 这些模型的好处是,与 ChatGPT 或 GPT-4 不同,模型权重适用于大多数商业用例。 通过在定制云提供商或本地基础设施上部署这些模型,隐私问题得到缓解——这意味着大型行业现在可以开始认真考虑将生成式人工智能的奇迹融入到他们的产品中!
那么让我们深入了解各种大型语言模型 (LLM) 的经济学!

1、GPT-3.5/4 API 成本
ChatGPT API 按使用情况定价,1K 代币的费用为 0.002 美元。 每个令牌大约是一个单词的四分之三,单个请求中的令牌数量是提示 + 生成的输出令牌的总和。 假设您每天处理 1000 个小块文本,每个块都是一页文本,即 500 个单词或 667 个标记,并且输出的长度也是相同的长度(作为上限)。 这相当于每天 0.002 美元/1000×66721000= ~2.6 美元。 一点也不差!
但是,如果您每天处理一百万个此类文档,会发生什么情况? 那么每天就是 2,600 美元,或者每年大约 100 万美元! ChatGPT 从一个很酷的玩具变成了一项价值数百万美元的业务的一项主要开支(因此人们希望它是一项主要收入来源)!

2、开源模型托管成本




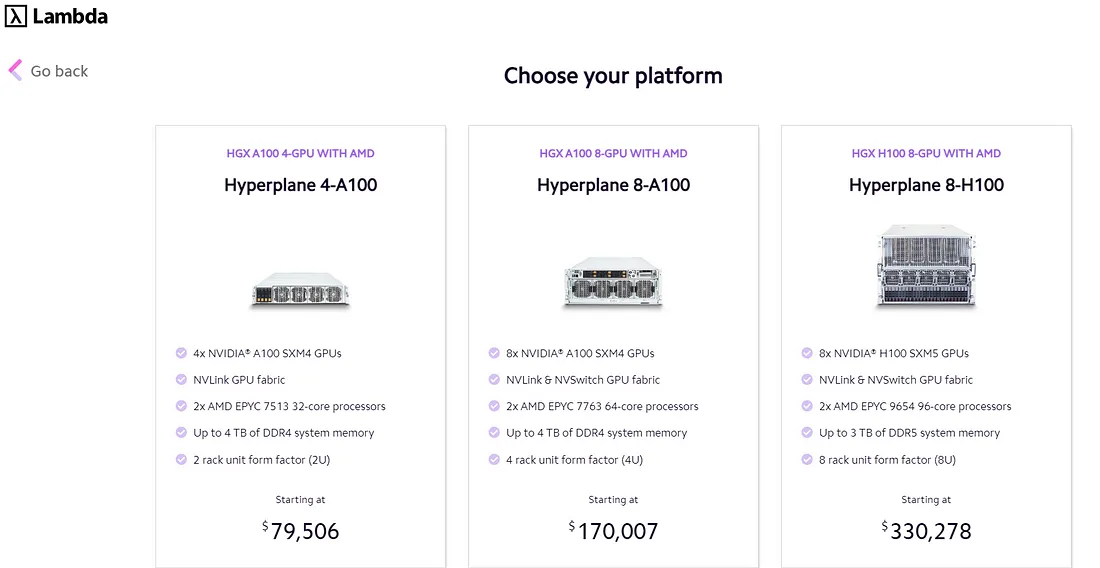
3、本地托管成本
4、结束语
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





