目录
2.2 近邻条件(Contiguity Conditions)
Flink CEP
在Flink的学习过程中,我们已经掌握了从基本原理和核心层的DataStream API到底层的处理函数,再到应用层的Table API和SQL的各种手段,可以应对实际应用开发的各种需求。然而,在实际应用中,还有一类更为复杂的需求,即需要检测以特定顺序先后发生的一组事件,进行统计或做报警提示。这类需求很难直接用SQL或者DataStream API来完成,需要使用更底层的处理函数来解决。
处理函数虽然可以解决这类问题,但对于非常复杂的组合事件,可能需要设置很多状态、定时器,并在代码中定义各种条件分支(if-else)逻辑来处理,复杂度会非常高,很可能会使代码失去可读性。为了解决这类问题,Flink提供了专门用于处理复杂事件的库——CEP(Complex Event Processing),可以更加轻松地解决这类棘手的问题。CEP提供了各种模式匹配和过滤功能,使得我们能够更加高效地处理复杂事件。
在企业的实时风险控制中,CEP具有非常重要的作用。通过使用CEP,我们可以实时监测各种复杂事件的发生,并进行相应的处理。例如,我们可以监测用户的交易行为,当发现异常行为时及时进行报警或阻止交易,以保障企业的安全。
总之,Flink CEP是一个强大的工具,可以帮助我们更加轻松地处理复杂事件。通过学习和掌握CEP的用法,我们可以更好地应对各种实际应用中的需求,提高数据处理和分析的效率。
模式 API(Pattern API)
Flink CEP 的核心是复杂事件的模式匹配,而模式匹配主要依赖于 Pattern 类。Pattern 类是 Flink CEP 库中提供的核心类,用于定义和匹配复杂事件的模式。通过 Pattern 类,我们可以调用一系列方法来定义匹配模式,这就是所谓的模式 API(Pattern API)。
模式 API 提供了丰富的功能,让我们能够定义各种复杂的事件组合规则,从而从事件流中提取出复杂事件。下面将展开讲解模式 API 中的一些概念和用法:
-
定义事件类型:在模式匹配之前,我们需要为事件流中的每个事件定义一个类型。这可以通过使用
TypeDescriptor类来完成,它描述了事件的类型和属性。 -
创建 Pattern 对象:使用
PatternFactory类可以创建一个 Pattern 对象,它是进行模式匹配的基础。PatternFactory类提供了一些静态方法,用于创建不同类型的模式。 -
定义模式:使用 Pattern API,我们可以定义各种模式来匹配复杂事件。常见的模式包括顺序模式、选择模式、时间模式等。这些模式可以组合在一起,形成更复杂的模式。
- 顺序模式:顺序模式是指一组事件按照特定的顺序发生。我们可以通过调用
Pattern.begin和Pattern.next方法来定义顺序模式的开始和下一个事件。 - 选择模式:选择模式是指多个事件中的任何一个可以发生。我们可以通过调用
Pattern.or方法来定义选择模式的多个可能路径。 - 时间模式:时间模式是指事件发生的时间符合特定的时间限制。我们可以通过调用
Pattern.within方法来指定时间模式的超时时间。
- 顺序模式:顺序模式是指一组事件按照特定的顺序发生。我们可以通过调用
-
匹配事件流:一旦定义了模式,我们就可以将其应用到事件流上,进行实时匹配。Flink CEP 会自动检测出满足模式的事件组合,并输出结果。
-
处理复杂事件:当检测到满足模式的复杂事件时,我们可以对其进行进一步的处理。处理方式可以是输出到外部系统、触发报警、更新数据库等。Flink CEP 提供了一些内置的方法来处理匹配的事件,也可以自定义处理逻辑
1.个体模式
模式(Pattern)在复杂事件处理(CEP)中,实际上是一个规则,用于将一组简单事件组合成复杂事件。这个规则的构建是有一定条件的,并且它能够按照一定的顺序串联组合多个简单事件。每个简单事件都有其匹配规则,这些规则被称作“个体模式”(Individual Pattern)。
1.1基本形式
个体模式是复杂事件处理中的基本单元,用于定义事件之间的匹配规则。它们可以看作是简单的模式,用于筛选和匹配特定的事件。在个体模式中,我们使用“连接词”来定义事件的顺序和关联,例如“begin”、“next”等。这些连接词用于指定事件之间的逻辑顺序,帮助我们构建更复杂的模式。
个体模式需要一个“过滤条件”,用于指定具体的匹配规则。这些条件是通过调用where()方法来定义的,具体的过滤逻辑则通过传入的SimpleCondition类的filter()方法来定义。SimpleCondition类提供了丰富的条件判断方法,可以根据事件的属性、状态、时间戳等特征进行筛选和匹配。
除了基本的匹配规则外,个体模式还可以进行循环匹配,接收多个事件。这是通过给个体模式增加“量词”来实现的。量词用于指定个体模式可以匹配的事件数量,例如“一次或多次”、“零次或多次”等。通过使用量词,我们可以构建更灵活的模式,处理更复杂的事件序列。
在实际应用中,个体模式的组合和嵌套构成了更复杂的模式。通过组合多个个体模式,我们可以构建出更复杂的匹配规则,用于从事件流中提取有意义的信息。个体模式的使用,使得我们能够灵活地定义事件的匹配规则,满足不同场景下的需求。
1.2 量词(Quantifiers )
在复杂事件处理中,量词用于指定个体模式可以匹配的事件数量。通过使用量词,我们可以构建出更灵活的模式,处理更复杂的事件序列。量词的使用使得个体模式可以匹配多个事件,这在处理连续事件或重复事件时非常有用。
在Flink CEP中,提供了多种指定循环模式的方法,主要有以下几种:
oneOrMore:匹配事件出现一次或多次。times(times):匹配事件发生特定次数,例如a.times(3)表示aaa。times(fromTimes, toTimes):指定匹配事件出现的次数范围,最小次数为fromTimes,最大次数为toTimes。例如a.times(2, 4)可以匹配aa、aaa和aaaa。greedy:只能用在循环模式后,使当前循环模式变得“贪心”,也就是总是尽可能多地去匹配。例如a.times(2, 4).greedy,如果出现了连续4个a,那么会直接把aaaa检测出来进行处理,其他任意2个a是不算匹配事件的。optional:使当前模式成为可选的,也就是说可以满足这个匹配条件,也可以不满足。
1.3 条件(Conditions)
通过组合使用这些量词和个体模式,我们可以构建出更复杂的模式来处理实际场景中的事件流。在实际应用中,个体模式的组合和嵌套为我们提供了丰富的工具和功能,帮助我们更好地处理和分析复杂事件。
对于个体模式的匹配条件,Flink CEP 提供了多种方式来定义事件的筛选规则。通过调用 Pattern 对象的 where() 方法,我们可以定义简单条件、迭代条件、复合条件和终止条件等不同类型的匹配规则。这些条件可以根据事件的属性、状态、时间戳等特征进行筛选和匹配。
- 简单条件:通过调用
where()方法,我们可以指定事件的一些简单属性或状态作为匹配条件。例如,我们可以根据事件类型、属性值等进行筛选。 - 迭代条件:对于需要匹配多个连续事件的场景,我们可以使用迭代条件。通过调用
oneOrMore()或times(fromTimes, toTimes)方法,我们可以指定事件的出现次数范围。 - 复合条件:复合条件允许我们将多个简单条件组合在一起,通过逻辑运算符(如 AND、OR)来构建更复杂的匹配规则。
- 终止条件:在某些场景中,我们可能需要匹配到特定的事件作为结束条件。通过调用
until()方法,我们可以指定一个终止条件,只有当该条件满足时,匹配才会结束。
除了 where() 方法外,Flink CEP 还提供了 subtype() 方法来限定匹配事件的子类型。通过调用 subtype() 方法,我们可以指定匹配事件必须属于特定的子类型。这对于处理具有层次结构的事件非常有用,例如消息协议中的不同消息类型。
通过灵活使用这些匹配规则和条件,我们可以构建出满足实际需求的复杂事件处理模式。Flink CEP 提供了丰富的功能和工具,帮助我们更好地处理和分析复杂事件流。在实际应用中,个体模式的组合和嵌套为我们提供了更灵活的事件处理能力,能够应对各种复杂的场景和需求。
2.组合模式
有了定义好的个体模式,我们可以进一步将这些模式按照一定的顺序连接起来,以定义一个完整的复杂事件匹配规则。这种将多个个体模式组合起来的完整模式被称为“组合模式”(Combining Pattern),有时也被称为“模式序列”(Pattern Sequence)以示区别。
组合模式的作用是将多个个体模式组合成一个有机的整体,以便更全面地描述和匹配复杂事件。通过组合模式,我们可以实现更高级的事件匹配功能,例如顺序匹配、选择匹配、聚合匹配等。
顺序匹配是一种常见的事件匹配方式,它要求事件按照特定的顺序出现。通过将个体模式按照顺序连接起来,我们可以定义事件的顺序关系,并检测符合该顺序的事件序列。
选择匹配允许我们根据多个可能的模式进行匹配。通过组合多个个体模式,我们可以构建一个复杂的匹配规则,该规则可以匹配符合任意一个个体模式的事件序列。
聚合匹配关注的是事件之间的聚合关系,而不是事件的顺序或选择关系。通过聚合匹配,我们可以找到满足特定聚合条件的事件集合,例如统计事件的个数、求和等。
2.1 初始模式(Initial Pattern)
在组合模式中,必须以一个“初始模式”作为开头,而这个初始模式必须通过调用 Pattern 的 begin() 方法来创建。这样做的目的是为后续的模式匹配提供一个起始点。
val start = Pattern.begin[Event]("start") 上述代码调用了 Pattern.begin() 方法来创建一个初始模式。这里的 "start" 是模式的名称,而 [Event] 指定了要检测的事件类型为 Event。这意味着这个模式将用于匹配流中 Event 类型的起始事件。
值得注意的是,Pattern 类型有两个泛型参数。第一个泛型参数是检测事件的基本类型,与 begin() 方法中指定的类型一致。第二个泛型参数是当前模式中事件的子类型,这由子类型限制条件指定。
通过使用初始模式作为起点,您可以继续添加其他个体模式和条件,以构建更复杂的组合模式。组合模式能够涵盖更广泛的事件匹配场景,并帮助您更好地处理和分析复杂事件流。
2.2 近邻条件(Contiguity Conditions)
在构建组合模式时,我们需要注意事件之间的顺序和关系,这被称为“近邻条件”或“连续性条件”。Flink CEP 中提供了三种近邻关系:
- 严格近邻(Strict Contiguity):这是最严格的一种关系,要求匹配的事件严格按顺序一个接一个出现,中间不能有任何其他事件。在代码中,我们可以使用
next()方法来实现这种关系。 - 宽松近邻(Relaxed Contiguity):这种关系放宽了对事件之间的距离要求,只关心事件发生的顺序。这意味着两个匹配的事件之间可以有其他不匹配的事件出现。在代码中,我们可以使用
followedBy()方法来实现这种关系。 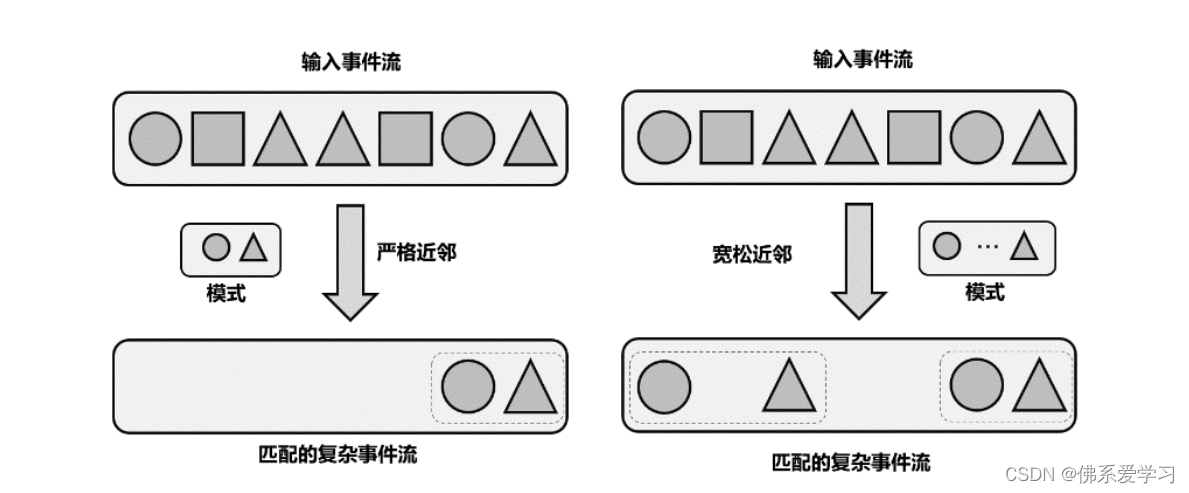
- 非确定性宽松近邻(Non-Deterministic Relaxed Contiguity):这种关系更加宽松,因为它允许重复使用之前已经匹配过的事件。这意味着同一个事件可以作为不同复杂事件的开始,因此匹配的结果可能会比宽松近邻更多。在代码中,我们可以使用
followedByAny()方法来实现这种关系。 
通过合理使用这些近邻条件,我们可以构建出满足特定需求的复杂事件匹配规则。
3 模式组
在处理复杂事件匹配时,有时业务逻辑可能需要将整个模式序列划分为多个阶段,每个阶段都有一系列的匹配规则。为了满足这种需求,Flink CEP 允许我们以“嵌套”的方式定义模式。
在模式序列中,我们使用诸如 begin(), next(), followedBy(), followedByAny() 等“连接词”来组合个体模式。这些方法的参数通常是个体模式的名称。而现在,我们可以直接将这些连接词的参数替换为一个模式序列,从而实现模式的再次组合。这样构建出的模式结构被称为“模式组”(Groups of Patterns)。
在模式组中,每一个模式序列被视为某一阶段的匹配条件,返回的类型是 GroupPattern。值得注意的是,GroupPattern 是 Pattern 的子类,这意味着个体模式和组合模式能调用的方法,如 times(), oneOrMore(), optional() 等量词,在模式组中同样适用。
通过嵌套和组合模式,我们可以构建出更加灵活和复杂的匹配规则,以满足各种实际业务场景的需求。这种分阶段处理的方式有助于提高事件匹配的准确性和效率,从而更好地处理和分析复杂事件流。
4.匹配后跳过策略
在Flink CEP中,由于存在循环模式和非确定性宽松近邻的条件,同一个事件可能会被重复利用,并分配到不同的匹配结果中。这会导致匹配结果规模增大,有时显得非常冗余。为了精简匹配结果,我们主要关注循环模式的处理。
首先,我们了解到,如果对循环模式增加greedy的限制,那么会尽可能多地匹配事件,从而砍掉那些子集上的匹配。但这种方式较为简单粗暴,如果想要精确控制事件的匹配并跳过某些情况,需要制定其他策略。
在Flink CEP中,提供了“匹配后跳过策略”(AfterMatchSkipStrategy),专门用于精准控制循环模式的匹配结果。这个策略可以在Pattern的初始模式定义中,作为begin()的第二个参数传入。
匹配后跳过策略AfterMatchSkipStrategy是一个抽象类,有多个具体的实现,可以通过调用对应的静态方法来返回对应的策略实例。这里我们配置的是不做跳过处理,这也是默认策略。
接下来,我们通过举例说明不同的跳过策略对匹配结果的影响:
- 不跳过(NO_SKIP):默认策略,所有可能的匹配都会输出。例如,对于输入事件序列“a a a b”,会有6个匹配结果:(a1 a2 a3 b),(a1 a2 b),(a1 b),(a2 a3 b),(a2 b),(a3 b)。
- 跳至下一个(SKIP_TO_NEXT):找到一个a1开始的匹配后,跳过a1开始的所有其他匹配,直接从下一个a2开始匹配。最终得到(a1 a2 a3 b),(a2 a3 b),(a3 b)。这种跳过策略与使用greedy效果相同。
- 跳过所有子匹配(SKIP_PAST_LAST_EVENT):找到a1开始的匹配后,直接跳过所有a1直到a3开头的匹配。最终得到(a1 a2 a3 b),这是最为精简的跳过策略。
- 跳至第一个(SKIP_TO_FIRST[a]):找到a1开始的匹配后,跳到以最开始一个a(即a1)为开始的匹配。最终得到(a1 a2 a3 b),(a1 a2 b),(a1 b)。
- 跳至最后一个(SKIP_TO_LAST[a]):找到a1开始的匹配后,跳过所有a1、a2开始的匹配,跳到以最后一个a(即a3)为开始的匹配。最终得到(a1 a2 a3 b),(a3 b)。
-

原文地址:https://blog.csdn.net/2301_77578187/article/details/135972836
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65091.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!