RocksDB是Flink中用于持久化状态的默认后端,它提供了高性能和可靠的状态存储。然而,当处理大型状态并频繁读写时,可能会导致背压问题,因为RocksDB需要从磁盘读取和写入数据,而这可能成为瓶颈。
遇到的问题
Flink开发中遇到读写state大对象的问题,Flink webUI 火焰图表现如下:
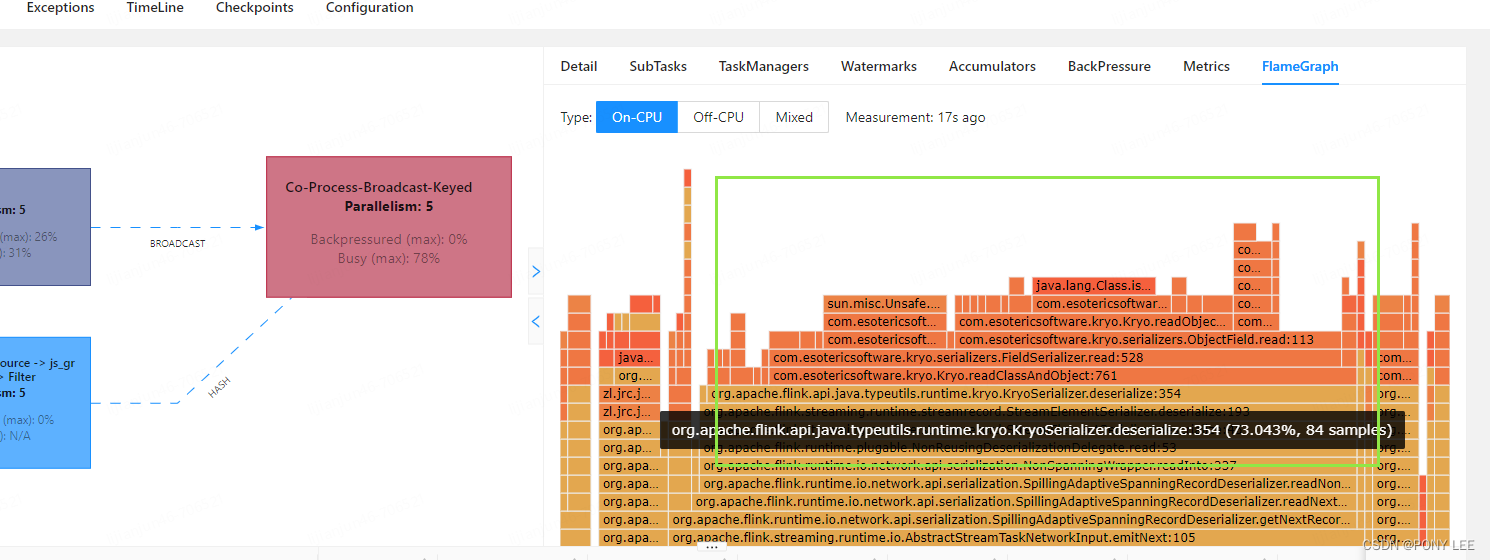 从图上看,瓶颈卡在序列化与反序列化,结合业务逻辑代码,业务涉及state大对象的读写,并且是ValueState。
从图上看,瓶颈卡在序列化与反序列化,结合业务逻辑代码,业务涉及state大对象的读写,并且是ValueState。
问题分析
如上,作为初学者来说,如果要在键值状态中存储Map<K, V>数据结构的状态,可能会认为使用ValueState<HashMap<K, V>>或者使用MapState<K, V>都是可行的。
如果我们选择使用HashMap状态后端,那么两种方式的性能上不会有很大差异,但是如果我们选择使用RocksDB状态后端,则推荐使用MapState<K, V>,避免使用ValueState<HashMap<K, V>>。
- 因为ValueState<HashMap<K, V>>在将数据写入RocksDB时,是将一整个HashMap<K, V>序列化为字节数组之后写入的。
- 同样,在读取时,也是先读取到字节数组,然后反序列化为一整个HashMap<K, V>后,再给用户使用。
所以每次访问和更新ValueState时,实际上都是对HashMap<K, V>这个集合类的大对象做序列化以及反序列化(如上图所示),而这是一个及其耗费资源的过程,很容易就会导致Flink作业产生性能瓶颈,所以极不推荐在ValueState中存储大对象。
问题调优
使用MapState代替ValueState,精简state数据量,问题解决。
除此之外还有一些其他调优策略:
-
增加算子并行度:通过增加算子的并行度,可以将负载分布到多个任务实例上,从而提高整体处理能力。这样可以减少单个任务实例的读写压力。
-
增加RocksDB的内存限制:RocksDB使用内存来缓存热数据,可以通过增加RocksDB的内存限制来提高缓存效果。可以通过Flink的配置选项state.backend.rocksdb.memory.managed来设置内存限制。
-
调整RocksDB的配置参数:RocksDB有许多配置参数可以调整,以优化读写性能。可以根据具体情况调整参数,例如write_buffer_size、max_write_buffer_number、max_background_compactions等。
-
使用异步快照:Flink提供了异步快照机制,可以将状态异步地持久化到RocksDB。这可以减少同步写入RocksDB的开销,并提高整体吞吐量。
-
定期进行状态清理和压缩:定期清理过期的状态数据和进行状态压缩可以减少磁盘占用和提高读写性能。可以使用Flink的状态后端接口进行定期的清理和压缩操作等等。
拿当前实例来说,虽然调优有很多种方式,例如:可以通过增量subtask并行度来提高处理能力(数据量大了还是会出现处理上的瓶颈,不可持续),但并没有找出问题的根本原因,或者说调优最大化。通过使用MapState代替ValueState,精简state数据量,可以达到调优最大化,以最小的代价解决最大的问题。
原文地址:https://blog.csdn.net/weixin_38251332/article/details/135917958
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_65115.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!