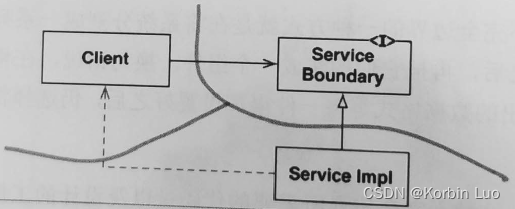
本文介绍: 每种存储架构都有其适用的场景和独特优势,实际选型时应根据具体AI工作负载特征和业务目标来权衡。随着AI大模型时代的到来,存储架构的设计趋势更倾向于高带宽、低延迟、高可靠性和经济高效的解决方案。在AI场景下,存储架构的选择需要考虑数据的规模、访问模式(读取密集型或写入密集型)、I/O性能要求、数据持久性、扩展性和成本等因素。
在AI场景下,存储架构的选择需要考虑数据的规模、访问模式(读取密集型或写入密集型)、I/O性能要求、数据持久性、扩展性和成本等因素。以下是一些常见的存储架构及其优势:
每种存储架构都有其适用的场景和独特优势,实际选型时应根据具体AI工作负载特征和业务目标来权衡。随着AI大模型时代的到来,存储架构的设计趋势更倾向于高带宽、低延迟、高可靠性和经济高效的解决方案。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。