目录
引言
正则表达式(Regular Expression,简写为regex或regexp)是一种用于文本搜索、匹配和替换的强大工具。它定义了一种字符串模式,使得我们可以通过这种模式来查找、验证或提取符合特定规则的文本片段。
在计算机科学和文本处理领域,正则表达式(Regular Expression)无疑是一种强大的工具。它为我们提供了一种简洁而富有表现力的方式来搜索、替换或提取符合特定模式的文本片段。无论是在编程开发、数据清洗、网络爬虫还是日志分析中,正则表达式的应用都无处不在。
一、正则表达式基础
(一)字符匹配
1.基本字符
直接写出即可匹配该字符本身,例如 a 匹配字符 “a”。
grep是一个全局搜索并打印匹配模式的行的命令。等下会讲到
2.特殊字符
| . | 匹配任意单个字符,可以是一个汉字 |
| [] | 匹配指定范围内的任意单个字符 |
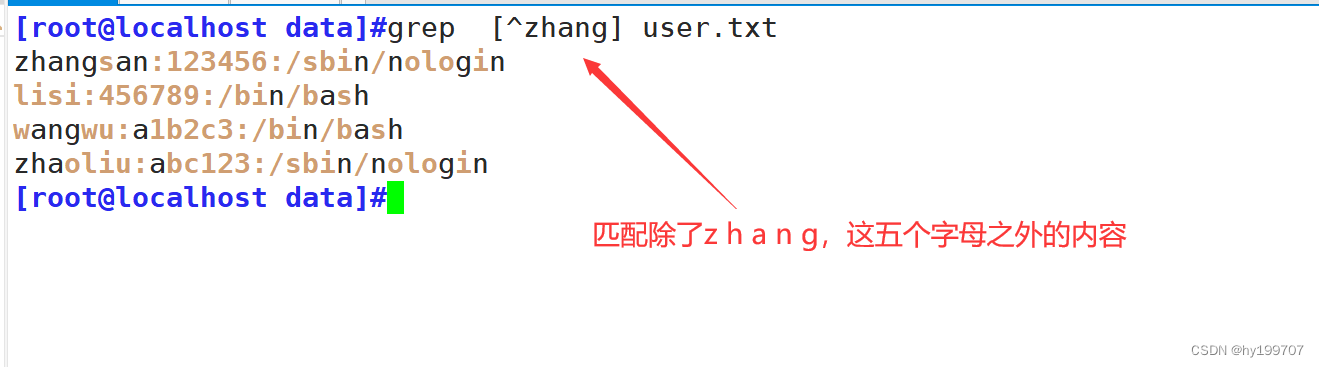
| [^] | 匹配指定范围外的任意单个字符,示例:[^zhou][^a.z][a.z] |
| [:alnum:] | 字母和数字 |
| [:alpha:] | 代表任何英文大小写字符,亦即A-Z,a-z |
| [:lower:] | 小写字母,示例:[[:lower:]],相当于[a-z] |
| [:upper:] | 大写字母 |
| [:blank:] | 空白字符(空格和制表符) |
| [:space:] | 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广 |
| [:cntrl:] | 不可打印的控制字符(退格、删除、警铃…) |
| [:digit:] | 十进制数字 |
| [:xdigit:] | 十六进制数字 |
| [:graph:] | 可打印的非空白字符 |
| [:print:] | 可打印字符 |
| [:punct:] | 标点符号 |
| w | #匹配单词构成部分,等价于[_[:alnum:]] |
| W | #匹配非单词构成部分,等价于[^_[:alnum:]] |
| S | #匹配任何非空白字符。等价于[^fnrtv]。 |
| s | #匹配任何空白字符,包括空格、制表符、换页符等等。等价于[fnrtv] |
| d | 数字字符集,等同于 [0-9],如d+可以匹配一个或多个连续的数字。 |
以前四个为例
. :表示匹配单个字符

[ ]:匹配指定范围内的任意单个字符

[^]:匹配指定范围外的任意单个字符
[:alnum:]:字母和数字

3.量词
| ? | 前一个元素出现0次或1次 | 如 colou?r 可以匹配 “color” 或 “colour” |
| * | 前一个元素出现0次或多次 | 如 a*b 可以匹配 “b”、”ab”、”aab” 等 |
| + | 前一个元素至少出现1次 | 如 a+b 可以匹配 “ab”、”aab”,但不匹配 “b” |
| {n} | 前一个元素精确出现n次 | 如 a{3} 只能匹配 “aaa” |
| {n,} | 前一个元素至少出现n次 | 如 a{2,} 可以匹配 “aa”、”aaa” 等 |
| {n,m} | 前一个元素最少出现n次 | 最多出现m次,如 a{2,4} 匹配 “aa”、”aaa” 和 “aaaa” |
?的用法

*的用法

+的用法

{n,m}的用法

4.边界匹配
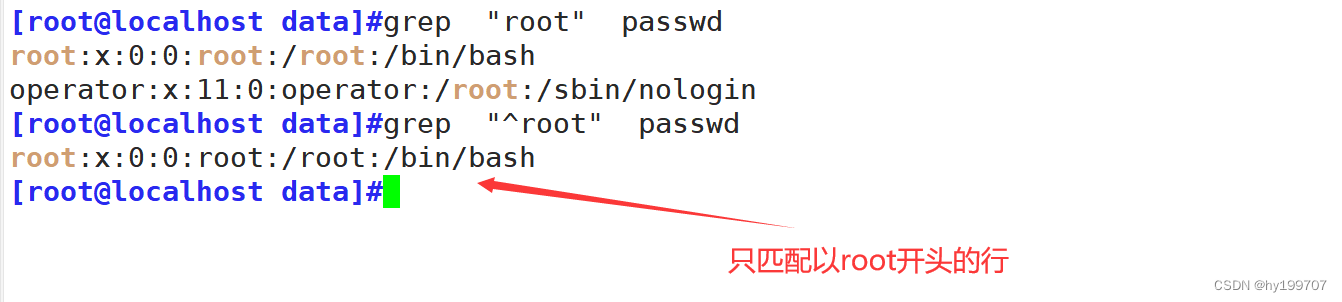
| ^ | 匹配字符串的开始位置 | 如 ^Hello 只匹配以 “Hello” 开头的字符串 |
| $ | 匹配字符串的结束位置 | 如 World$ 只匹配以 “World” 结尾的字符串 |
| b | 匹配单词边界 | 确保前后为非单词字符和单词字符的交界处 |
^的用法
$的用法

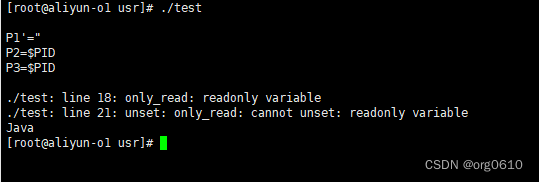
b的用法

b主要用于位置锚定,即精确地界定匹配的模式必须是独立的单词,而不是作为其他单词的一部分。
(二)进阶用法
1.组与引用
| () | 捕获分组 | 允许对内部模式进行分组,并可以引用捕获的内容 |

2.选择
| | | 表示或操作 | 匹配左右两边的任何一个表达式 |
符号“|”的使用

正则表达式是每个程序员都应该掌握的重要技能之一,熟练运用它可以极大地提高工作效率和代码质量。然而,需要注意的是,不同编程语言和工具对正则表达式的实现可能存在细微差异,请根据具体环境查阅相关文档并进行适配。同时,编写复杂正则时应尽量保持清晰和简洁,避免过度复杂的正则导致可读性和维护性降低。通过不断的实践与学习,你会发现正则表达式的世界充满了无限可能!
上面是一些正则表达式的基础用法。想要熟练掌握,还需要结合命令多加练习,下面介绍一些在工作中必备的三个文本处理命令
grep、sed 和 awk 是Linux/Unix环境下的三个非常强大的文本处理工具,它们在命令行中广泛用于搜索、替换和分析文本数据。
二、命令之—–grep
grep命令是Linux和类Unix系统中用于搜索文本文件中匹配特定模式的行的强大工具。它的全称是Global Regular Expression Print,即全局正则表达式打印
语法为
grep [选项] 表达式 文件名
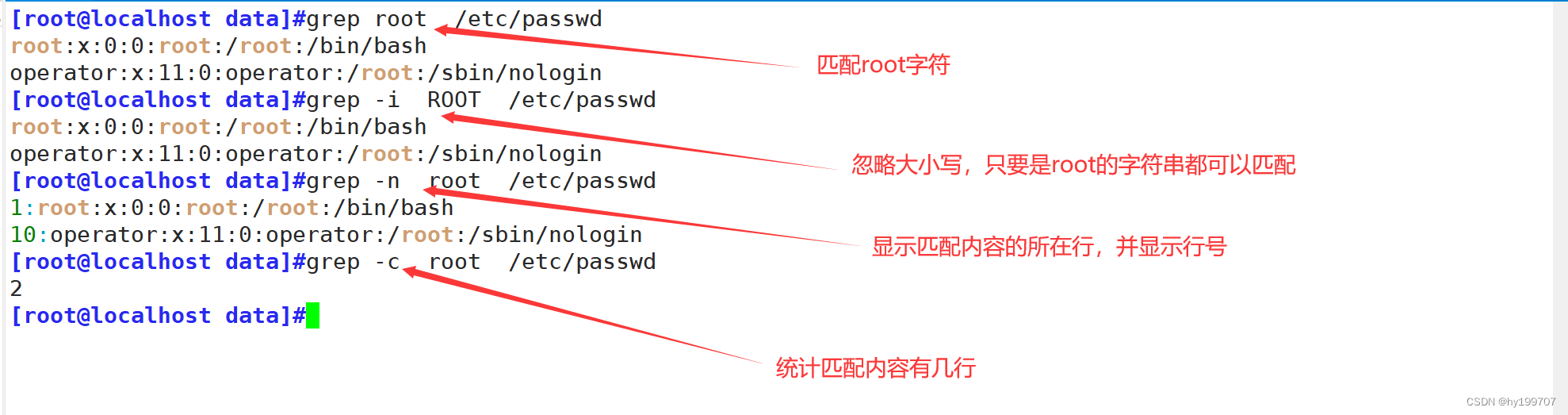
| -i | 忽略大小写进行匹配。 |
| -v | 反向选择,打印不包含匹配项的行。 |
| -n | 在输出行前加上行号。 |
| -c | 只显示包含匹配项的行数,而不是具体行内容。 |
| -w | 精确匹配整个单词。 |
| -e | 实现多个选项间的逻辑or关系 |
| -f | 从文件中读取多个搜索模式。 |
| -r ;-R | 递归地搜索目录下的所有文件。r不处理软链接R处理软链接 |
| -l | 仅列出包含匹配行的文件名。 |
| -m | 最多显示count个匹配行。 |
| -o | 只显示匹配内容 |
| -q | 静默输出,不显示任何内容。一般在写脚本的时候使用 |
| -E | 指定一个正则表达式模式。 |
(一)基础用法
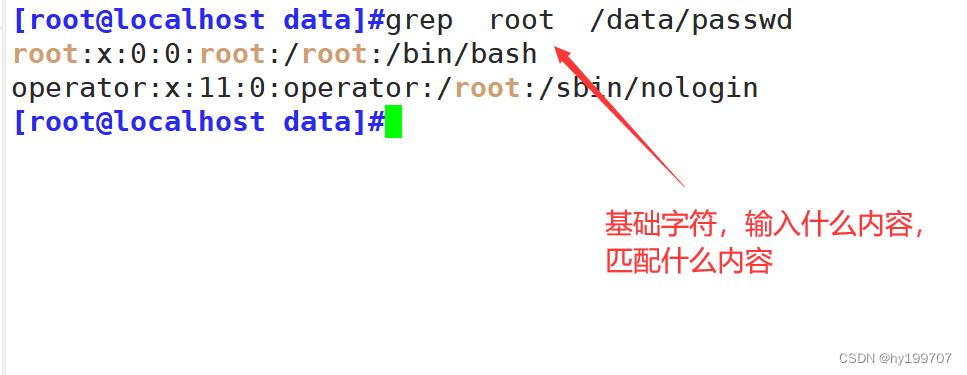
grep的基础用法就是匹配已知字符
例如下图所示
还可以进行组合,比如查看一个目录下,有哪些文件包含匹配的字符串
使用grep -lr 需要匹配的内容 目录

-o:表示只显示匹配的内容

-e:匹配多个内容,用-e连接起来

-m:最多显示指定的匹配行数

-v:反选,显示匹配内容之外的内容

-f:处理两个文件相同内容 把第一个文件作为匹配条件

-w:精准匹配单词

(二)高级用法
与正则表达式相结合使用,一般使用正则表达式时,大多数字符都具有特殊含义,所以在命令行中需要进行转译,或者加 -E 使用扩展正则,支持更丰富的正则表达式特性
例如匹配ip地址,子网掩码和广播地址

这个时候,我们只需要加上-E开启扩展正则就无需进行转译,可以直接匹配

结合| 就无需使用-e进行字符串关联

使用grep统计当前主机有多少普通用户可以登录

总之,grep -E 提供了比基本正则表达式更多的灵活性和功能,使得能够编写更复杂、更精确的搜索模式。
三、命令之—–sed
相对于grep命令来说,sed的命令就更加强大了一些。
sed(Stream Editor)是一种流编辑器,它逐行处理文本文件或输入流,并能够进行搜索、替换、删除、插入等操作。
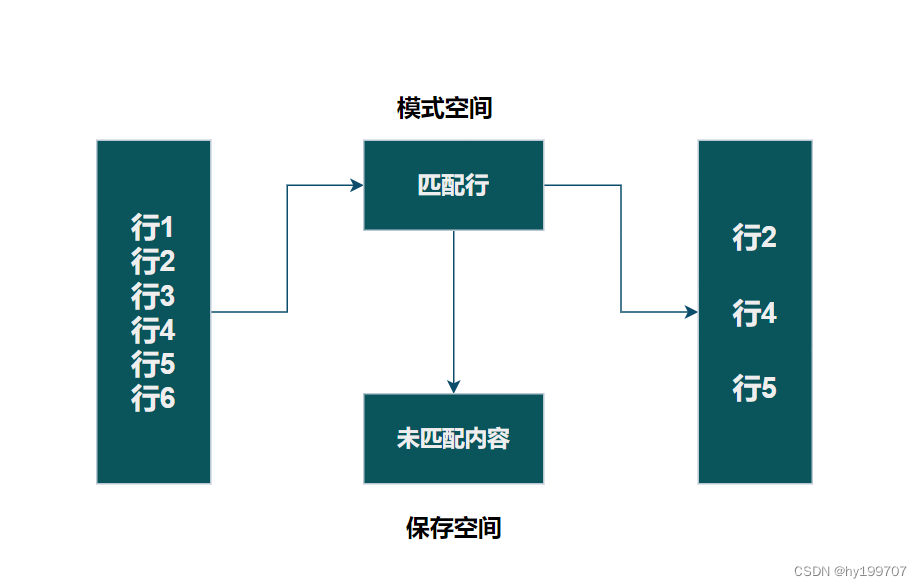
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。
sed命令,一般用于脚本当中
(一)基本用法
sed的基本语法为
sed [选项] ‘语法选项’ 文件名
| -e |
用指定命令或者脚本来处理输入的文本文件只有一个操作命令时省略, 一般在执行多个操作命令使用 |
| -f | 用指定的脚本文件来处理输入的文本文件 |
| -n |
不输出模式空间内容到屏幕,取消默认的打印行为, 只有在命令中显式使用 p 命令时才会打印行。 |
|
-r 或 -E |
使用扩展正则表达式 |
| -h | 显示帮助 |
| -i | 直接修改目标文件 |
| -i.xxx | 备份文件并原处编辑。xxx为自定义后缀名,可以随意设置 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
语法选项(模式空间操作):
| s/old/new/flags |
替换命令,用 new 替换每一行首次出现的 old,可选的标志包括 g:全局替换,在一行中所有匹配的地方都进行替换。 i:忽略大小写。 p:打印出已替换的行。 |
| d | 删除命令,删除匹配当前模式空间内容的行。 |
| a text | 在当前行后添加文本 text,新行以反斜杠 结束。 |
| i text | 在当前行前插入文本 text。 |
| p | 打印当前行(默认行为,如果没有 -n 参数的话)。 |
| q | 退出 sed,如果后面跟着一个数字,则在处理到第 n 行之后退出。 |
| c | 替换,将选定行替换为指定内容 |
| w | 保存模式匹配的行至指定文件 |
地址范围:
| number | 指定要操作的行号。 |
| /regex/ | 根据正则表达式匹配的行。 |
| address1, address2 | 处理从 address1 到 address2 的行。 |
1.打印功能

虽然sed本身具有打印功能,但是直接使用sed命令却无法打印,因为sed的打印原理是将匹配的每一行内容,逐行放入模式空间,并打印到屏幕上。这里没有匹配项,所以无法打印
而加上语法选项p之后会将每一行的内容打印两边,这是因为,sed本身具有打印功能,而p选项,是打印文件内容,就等于将所有内容匹配了一遍,所有sed又打印了一遍。
加上-n选项后,取消了自动打印功能,所以只执行了p功能的打印属性
打印指定行数

2.插入内容
a:下方插入 i:上方插入 c:指定行替换

将其它文本的内容插入到当前文本中

这些都只是打印出来的内容,真实文件是没有改变的,想要真实修改文件,需要加-i选项

(二)查找替换
语法格式为 sed [选项] s/old/new/flags 文件路径
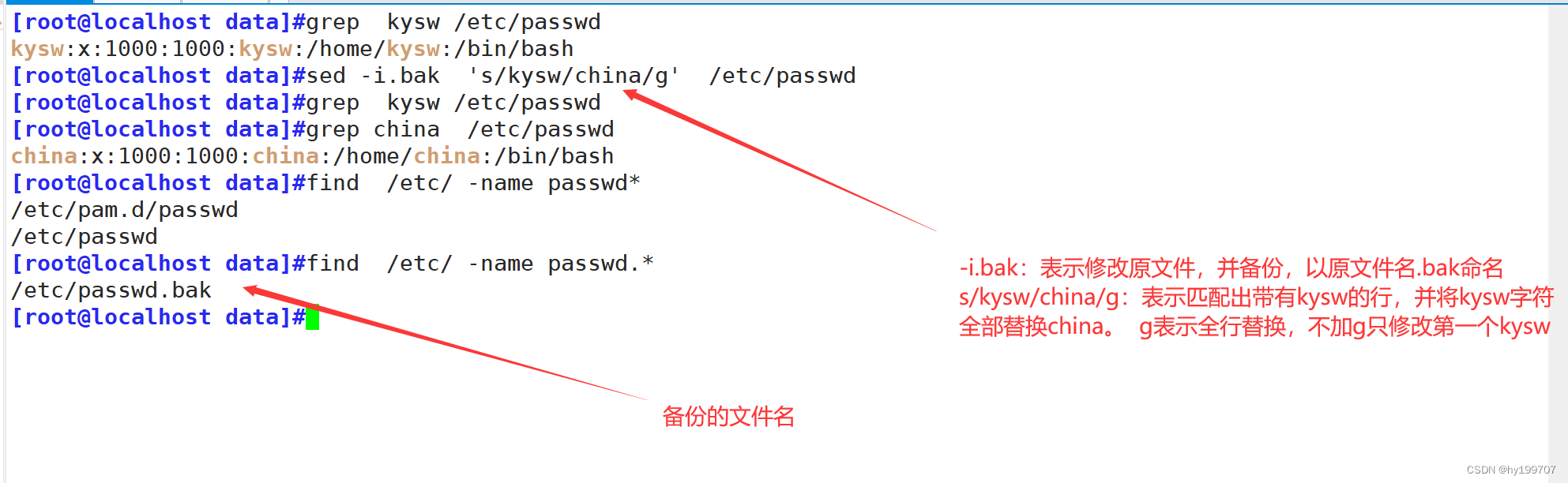
匹配旧内容时支持通配符,比如将selinux永久关闭,修改配置文件
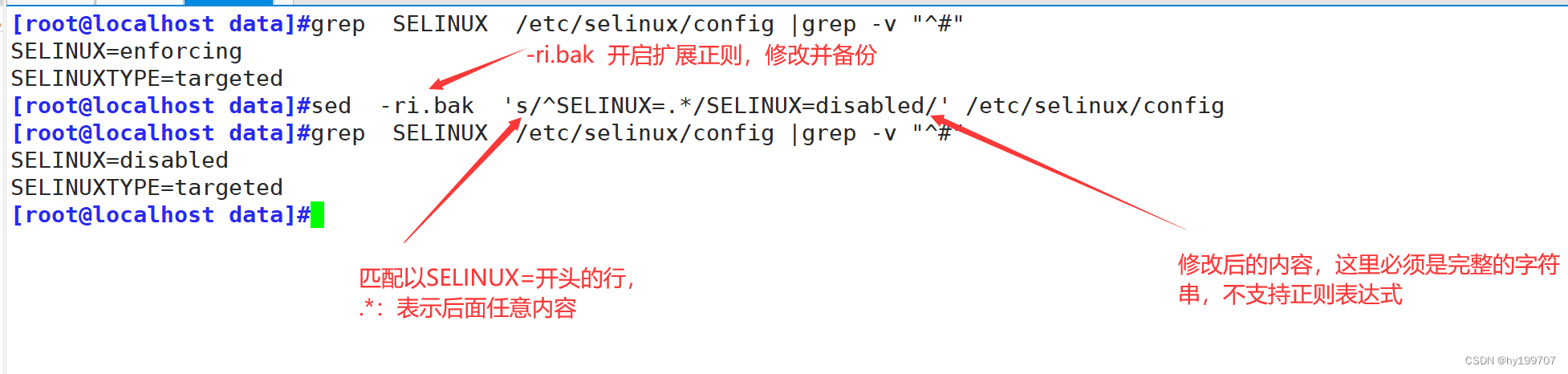
查找替换中,还有一种比较实用的用法叫后向引用
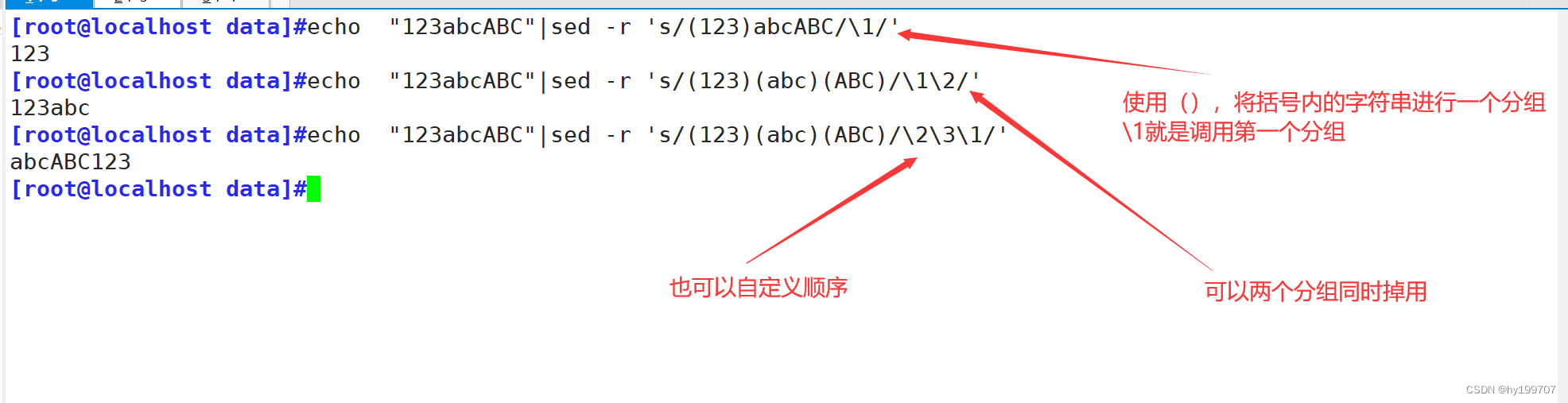
就是使用捕获分组() 将括号中的字符串定义为一个分组,第一个括号中的内容就是1.第二个括号中的内容就是2,以此类推
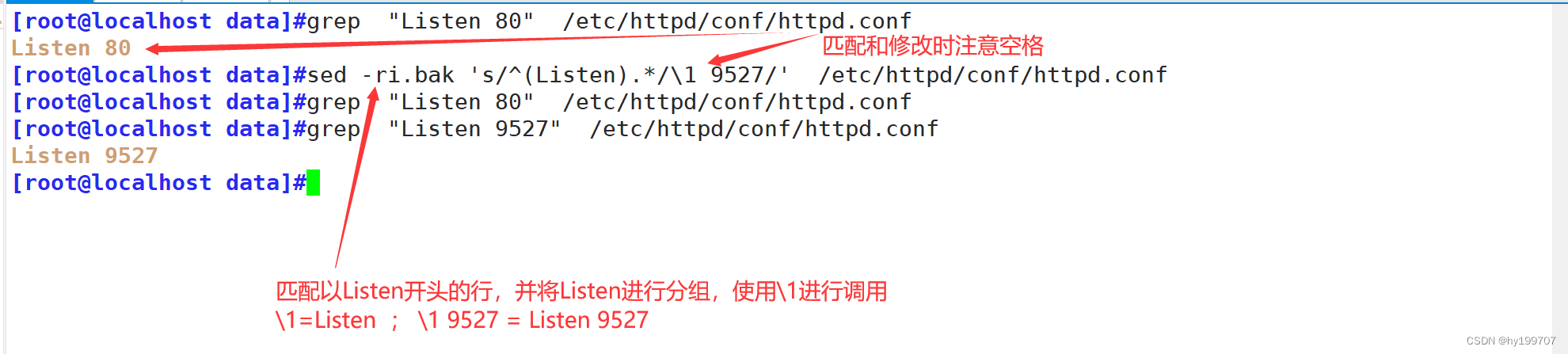
修改httpd的配置文件中的监听端口
指定行数
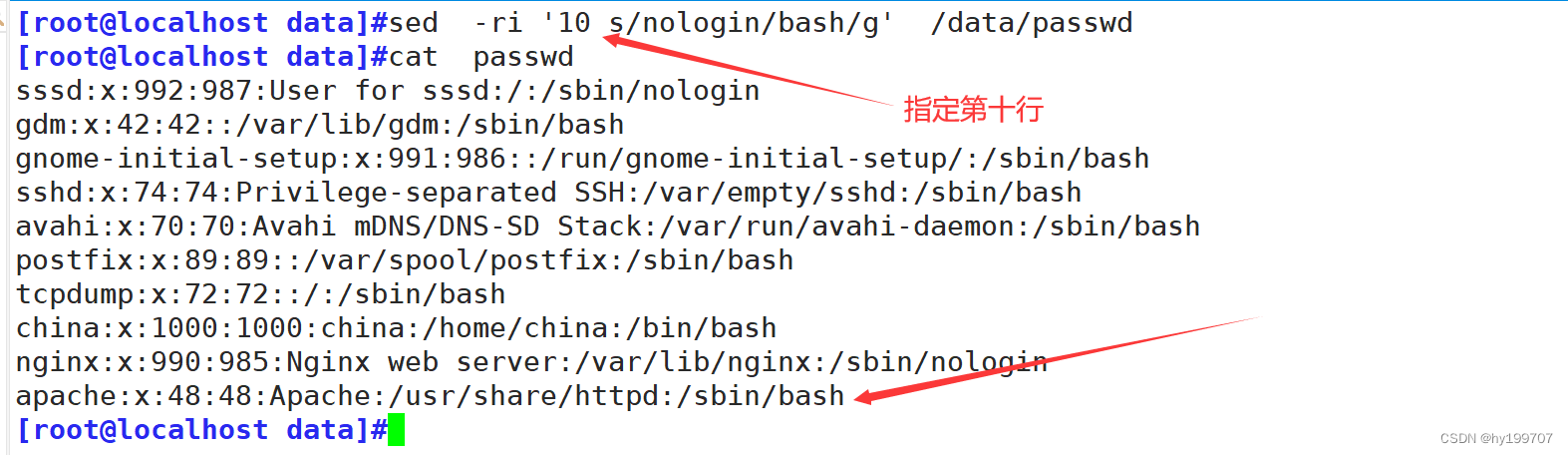
指定需要修改的行的范围

(三)变量
sed支持变量查找与替换
首先定义变量
语法格式为
sed -ri “s/${变量名}/${变量名}/g” /etc/passwd
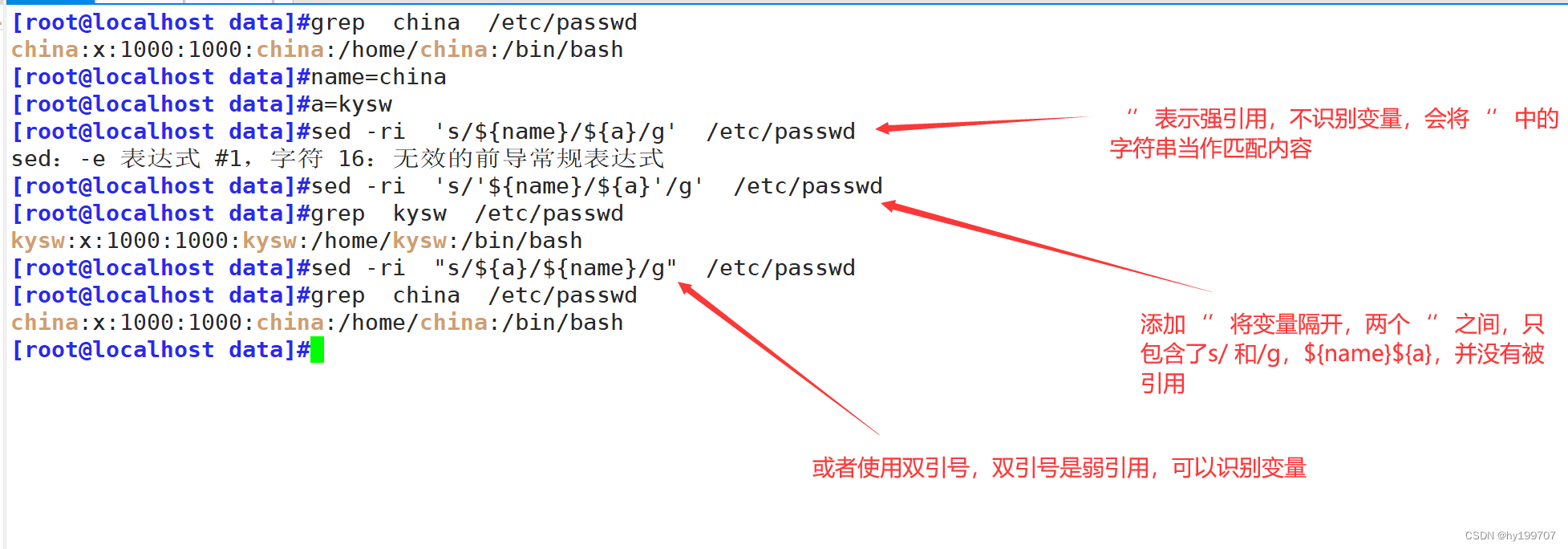
(四)高级用法
sed语法用有一些比较高级的使用方法
下面是一个语法选项
| 选项 | 含义 |
| P | 打印模式空间开端至n内容,并追加到默认输出之前 |
| N | 读取匹配到的行的下一行追加至模式空间 |
| n | 读取匹配到的行的下一行覆盖至模式空间 |
| G | 从保持空间取出的内容追加至模式空间 |
| g | 从保持空间取出的数据覆盖至模式空间 |
| H | 把模式空间中的内容追加至保持空间 |
| h | 把模式空间中的内容覆盖至保持空间 |
| x | 把模式空间中的内容与保持空间中的内容进行互换 |
| d | 删除模式空间中的行 |
| D | 如果模式空间包含换行符,则删除直到第一个换行符的模式空间中的文本,并不会读取新的输入行,而使用合成的模式空间重新启动循环,如果模式空间不包含换行符,则会像发出d命令那样启动正常的新循环 |
n,表示读取匹配到的行的下一行覆盖至模式空间

打印奇数行与偶数行的方式
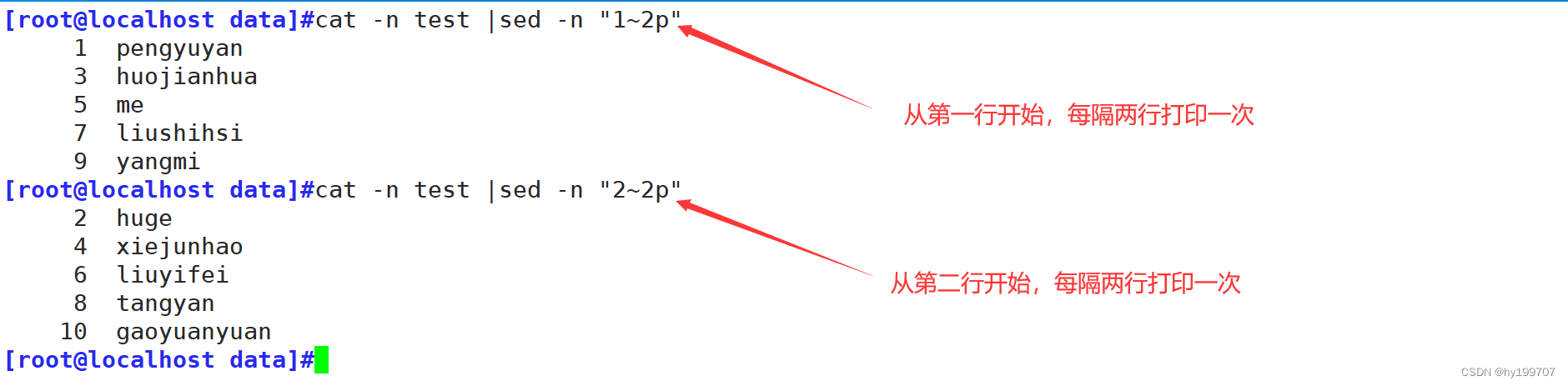

烧脑挑战
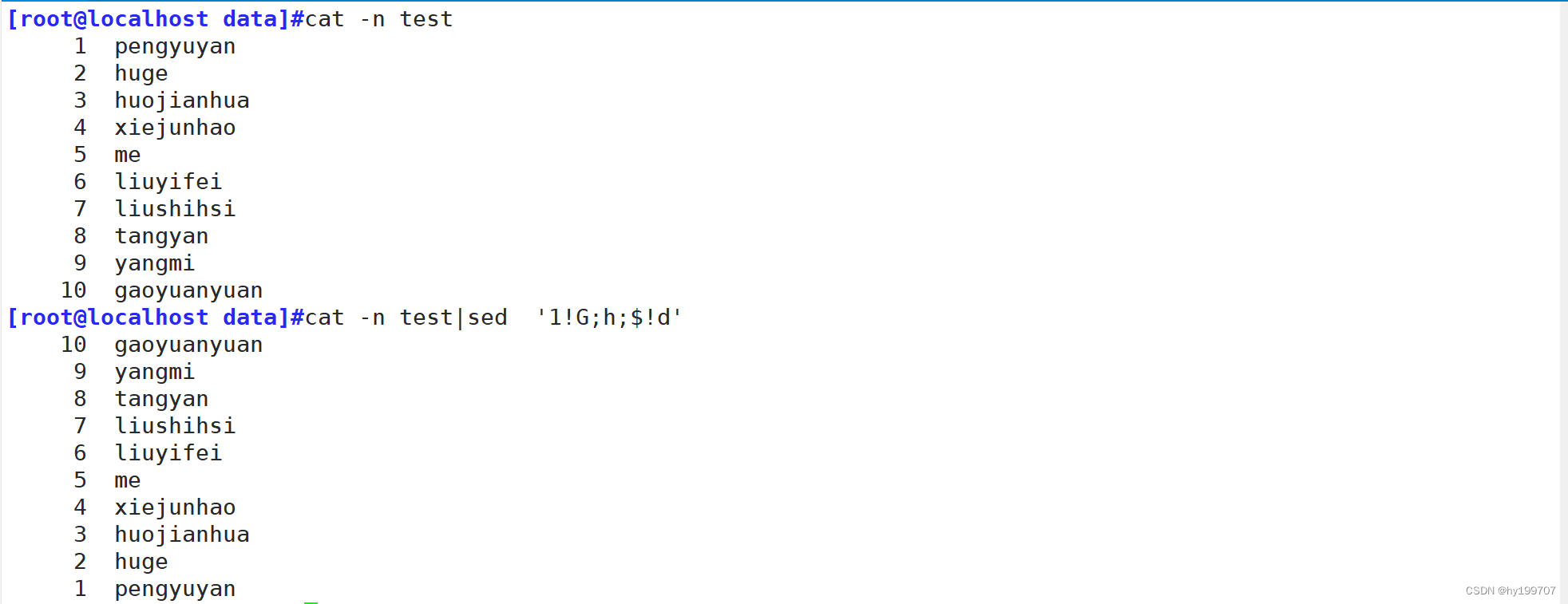
首先需要直到语法选项的含义
-n:取消默认打印
1:表示第一行
!:取反
G:从保持空间取出的内容追加至模式空间
h:把模式空间中的内容覆盖至保持空间
$!:表示最后一行
d:删除
现在,结合图片解释一下
从第一行开始匹配:1!取反,不是第一行才执行G(从保持空间取出的内容追加至模式空间),第一行不执行执行G,直接执行h(把模式空间中的内容覆盖至保持空间)保持空间为行1,不符合$(最后一行)条件,删除模式空间内容
第二行:1!取反,不是第一行就执行G,将保持空间取出的内容追加至模式空间,而后执行h,将行2与行1覆盖至保持空间,不是最后一行,删除模式空间内容
第三行:1!取反,不是第一行就执行G,将保持空间取出的内容追加至模式空间,而后执行h,将行3、行2、行1覆盖至保持空间,不是最后一行,删除模式空间内容
以此类推,一直到最后一行,不删除模式空间内容,输出到屏幕
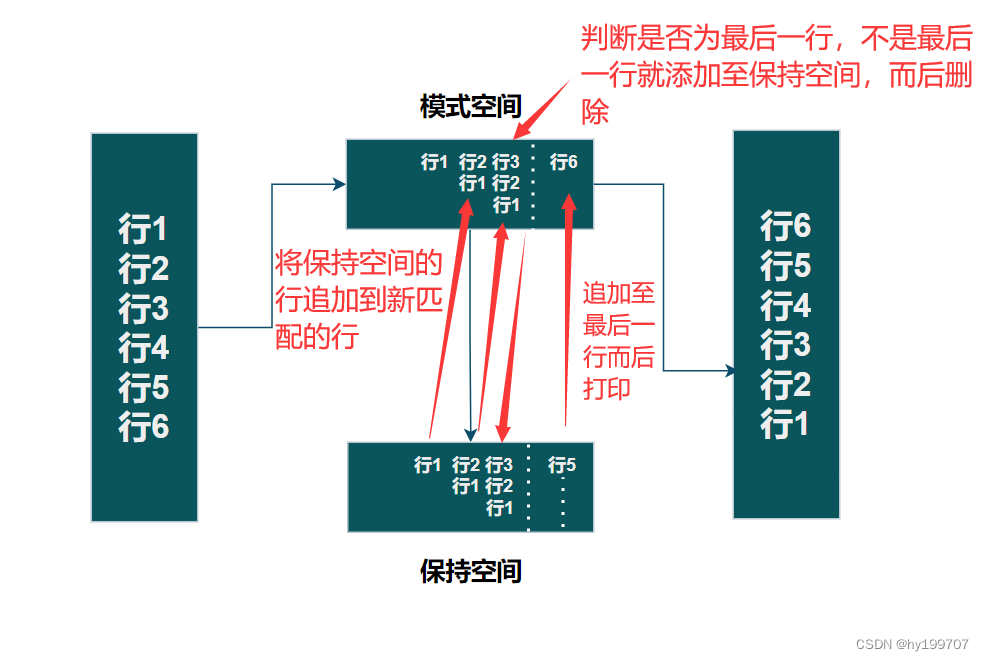
小结:sed语法一般用在脚本当中,不需要打开文件,进行文件修改,如果在bash环境中一般直接使用vim进行修改,但是,处理大文件时使用sed命令会更好,因为vim需要打开文件,会占用缓存资源,sed不需要打开文件可以直修改
四、命令之—–awk
(一)基本介绍
awk 是一款强大的文本处理工具,它基于模式匹配和行处理的概念进行设计。在Unix/Linux环境中,awk 通常用于对结构化文本数据(如日志文件、表格数据等)执行一系列操作,包括搜索、过滤、格式化输出以及各种计算和转换。
起源与名称: awk 的名字来源于其三位创始人 Alfred Aho、Peter Weinberger 和 Brian Kernighan 的首字母组合
现在使用的awk命令来自gawk软件
基本语法: awk [options] ‘pattern { action }’ file(s)
options:可选的命令行选项,例如 -F 用于设置输入字段分隔符。
pattern:一个或多个条件表达式,当指定的模式匹配到当前行时,执行相应的动作。用{}指明
action:在模式匹配成功后要执行的操作,可以包含任意合法的Awk语句,如变量赋值、打印、循环、函数调用等。
file(s):待处理的一个或多个输入文件名。
工作原理:
awk 将每一行输入数据视为一条记录,并将记录按照指定的分隔符划分为多个字段。对于每条记录,它都会尝试匹配给定的模式,如果模式匹配,则执行相应的动作。默认情况下,字段之间由空白字符(空格或制表符)分隔,但可以通过 -F 参数自定义分隔符。
内置功能
变量:awk 提供了一系列预定义变量,如 $0 表示整个记录,$1 到 $n 分别表示各字段,NF 表示字段数,NR 表示当前处理的记录行号等。
BEGIN/END 块
BEGIN 块在读取任何输入之前执行一次,常用于初始化变量或打印头部信息。
END 块在所有输入处理完毕后执行一次,适合于统计汇总结果或打印尾部信息。
运算符和表达式:支持算术、比较、逻辑及正则表达式等,可以用来构造复杂的匹配和控制流程。 流程控制:if…else 条件判断,for 和 while 循环,以及其他控制结构。
函数:内置有多种函数,如数学函数、字符串函数,同时也允许用户自定义函数。
选项:
| -v | 定义变量 |
| -F | 指定分隔符 |
常见内置变量
(二)基本用法
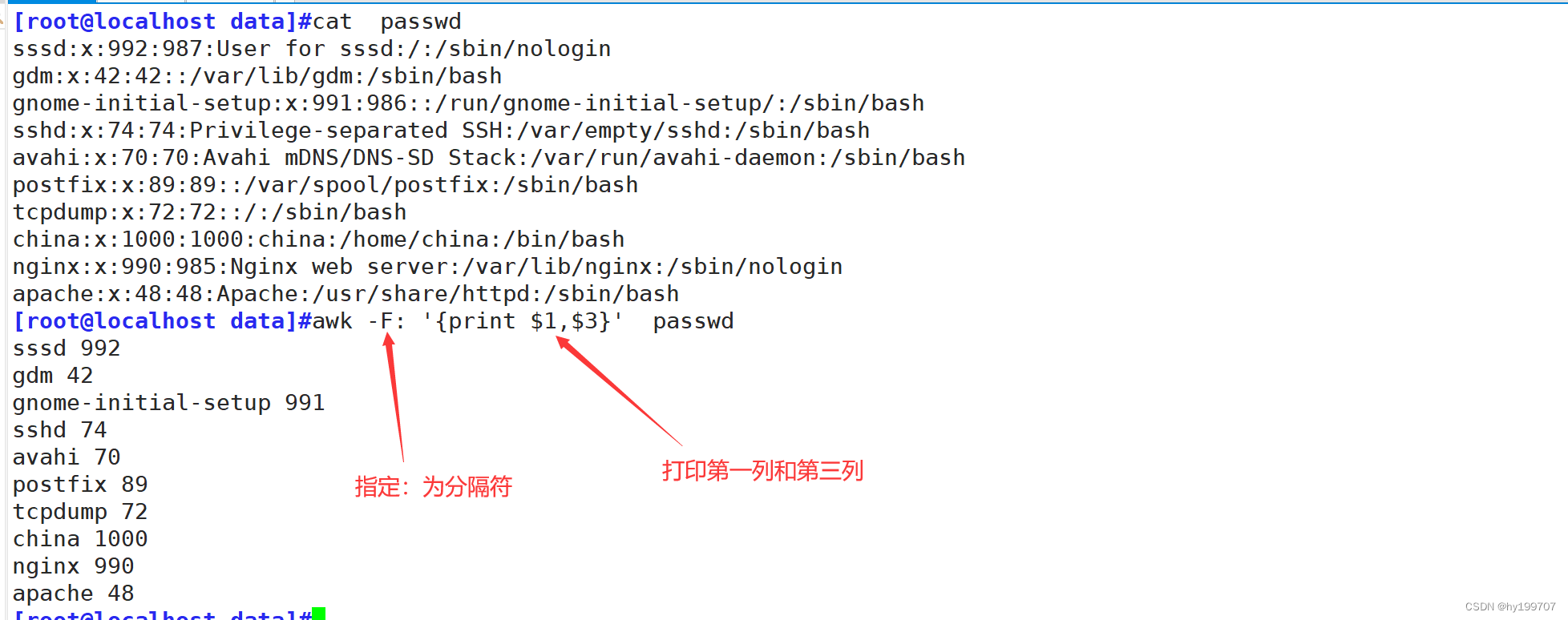
awk默认以一个以上的空格为分隔符
比如以前想过滤出IP地址,需要好几个命令堆加在一起,现在只需要awk一个命令就可以了

-F:指定分隔符
BEGIN/END 块
BEGIN 块在读取任何输入之前执行一次,常用于初始化变量或打印头部信息。

END 块在所有输入处理完毕后执行一次,适合于统计汇总结果或打印尾部信息。

BEGIN/END必须要大写
awk还支持标准输入

(三)变量
awk中常见的内置变量有以下几种
| 内置变量 | 作用 |
| NR | 当前处理的行的行号(序数) |
| NF | 当前处理的行的字段个数 |
| FS | 列分隔符,指定每行文本的字段分隔符,默认为空格或制表位。与 “ -F ” 作用相同 |
| OFS | 输出内容的列分隔符 |
| RS |
行分隔符,awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是”n” |
| $0 | 当前处理的行的整行内容 |
| $n | 当前处理行的第n个字段(第n列) |
| FILENAME |
被处理的文件名 |
NR:表示当前处理的行的行号(序数)
语法为awk ‘NR==n{处理动作}’ 文件名
例:
awk ‘{print $1,NR}’ passwd:打印出行号
awk ‘NR==2{print $1}’ /etc/passwd:只取第二行的第一个字段
awk ‘NR==1,NR==3{print}’ passwd :打印出1到3 行

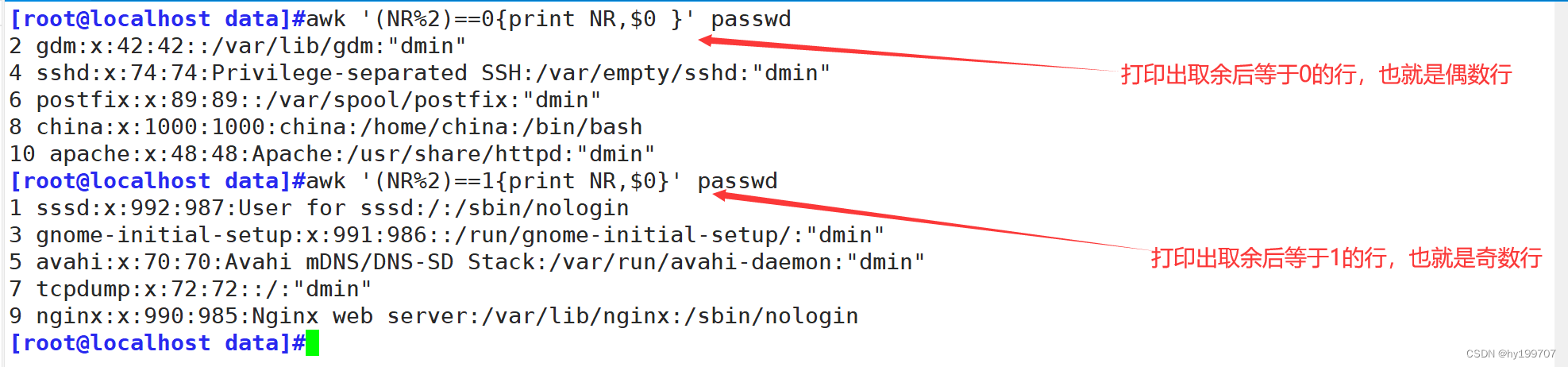
awk ‘(NR%2)==1{print NR,$0}’ passwd:打印出函数取余数为1的行
awk ‘(NR%2)==0{print NR,$0}’ passwd:打印出函数取余数为0行
$0:当前处理的行的整行内容
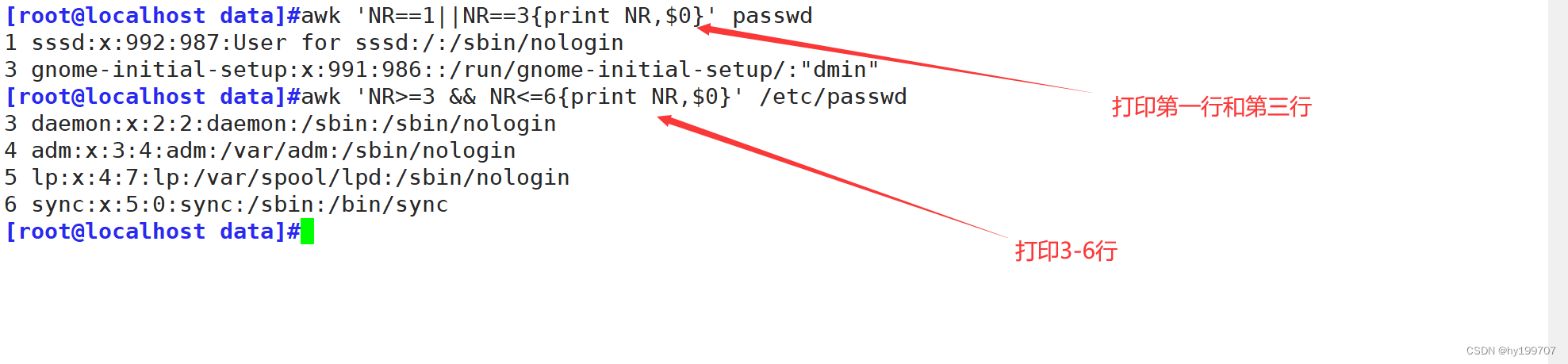
awk ‘NR==1||NR==3{print}’ passwd:打印出1和3行
awk ‘NR>=3 && NR<=6{print NR,$0}’ /etc/passwd :打印出大于等于第三行,小于等于第六行,也就是3-6行
FNR:将多个文件分开显示

NF:当前处理的行的字段个数
例:
awk -F: ‘{print NF}’ passwd

awk -F: ‘{print $NF}’ passwd :$NF表示最后一个字段

df|awk ‘{print $(NF-1)}’:倒数第二行
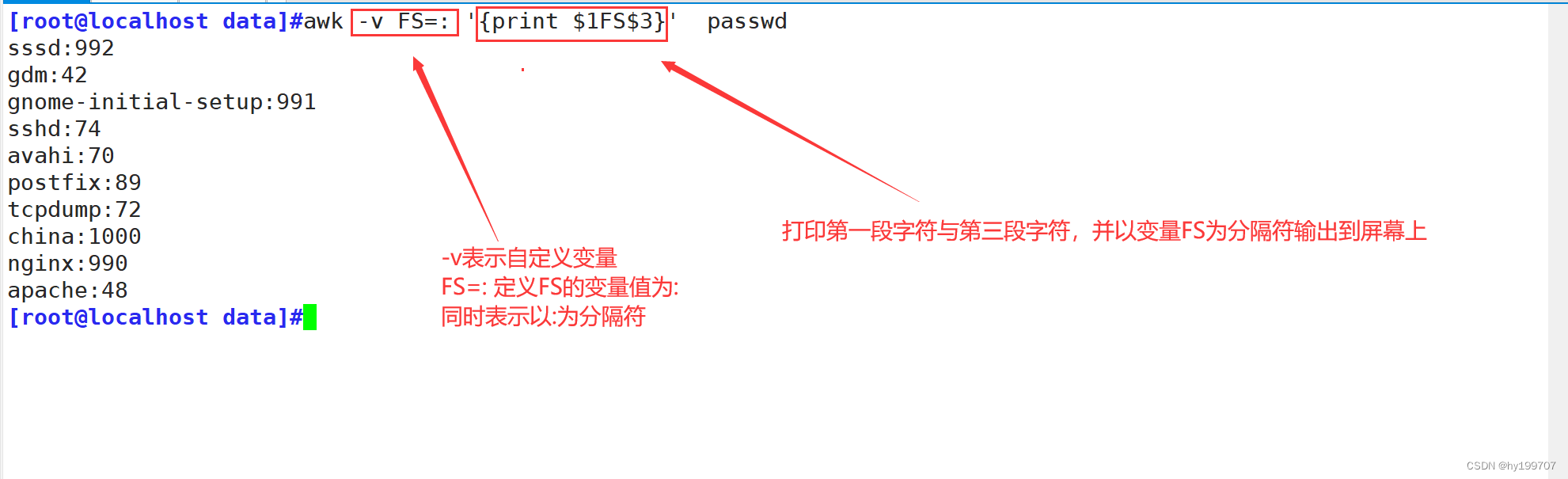
FS:列分隔符,指定每行文本的字段分隔符
RS:行分隔符,awk从文件中读取资料时,根据RS的定义把资分段, 而awk一次仅读入一条记录进行处理。预设值是”n”

OFS 输出内容的列分隔符($n=$n 用于激活,否则不生效,n且必须存在)

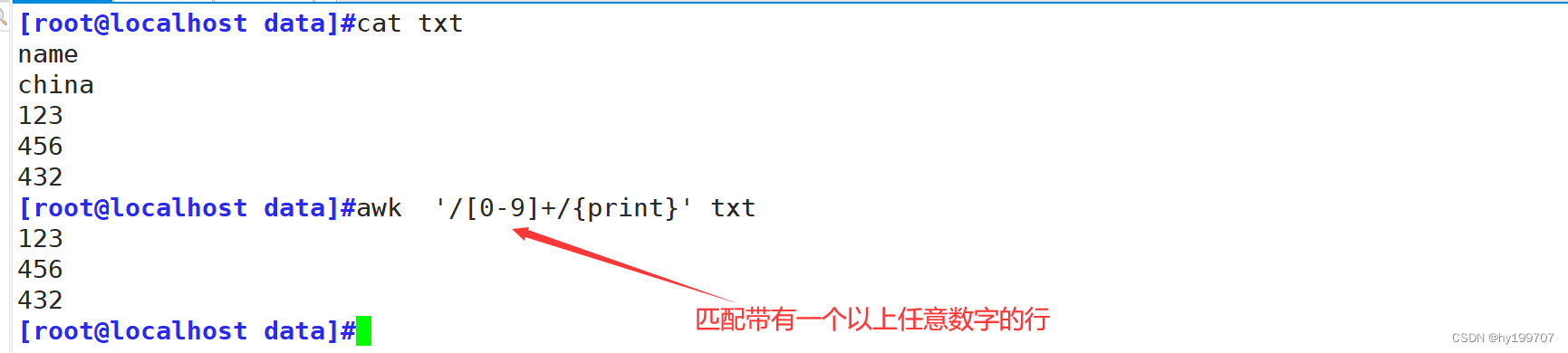
(四)正则匹配
awk同样支持正则表达式进行匹配

(五)line ranges:行范围
算术操作符
x+y, x-y, x*y, x/y, x^y, x%y

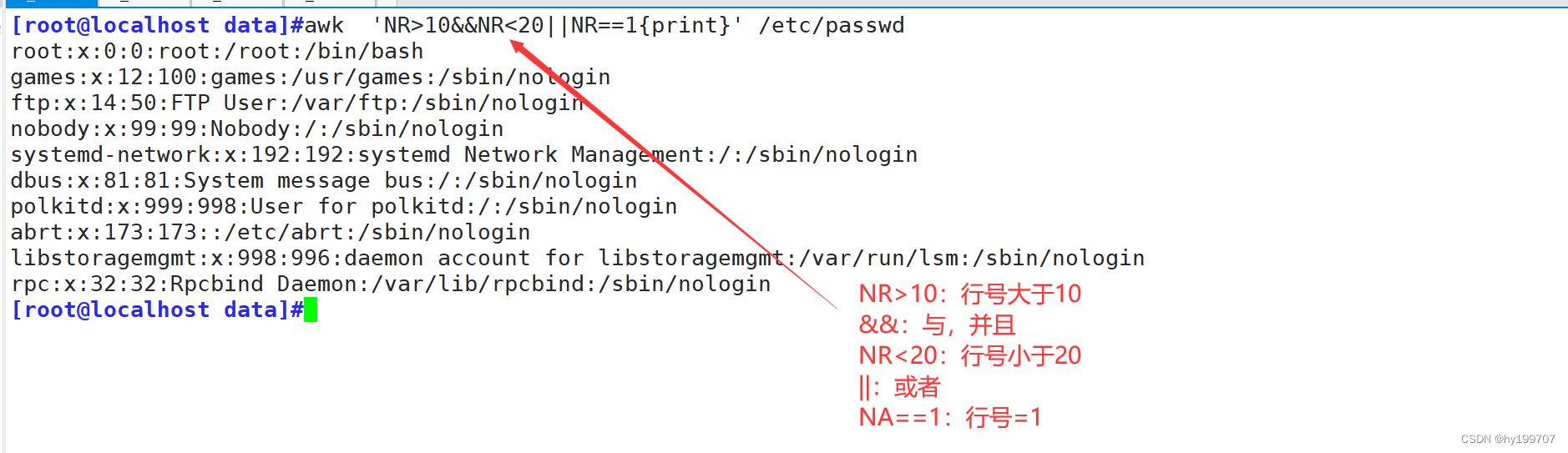
比较操作符:
==, !=, >, >=, <, <=
逻辑
与:&&,并且关系
或:||,或者关系
非:!,取反
(六)条件判断
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(判断条件){执行语句}

双分支为if(判断条件){执行语句}else{执行语句}
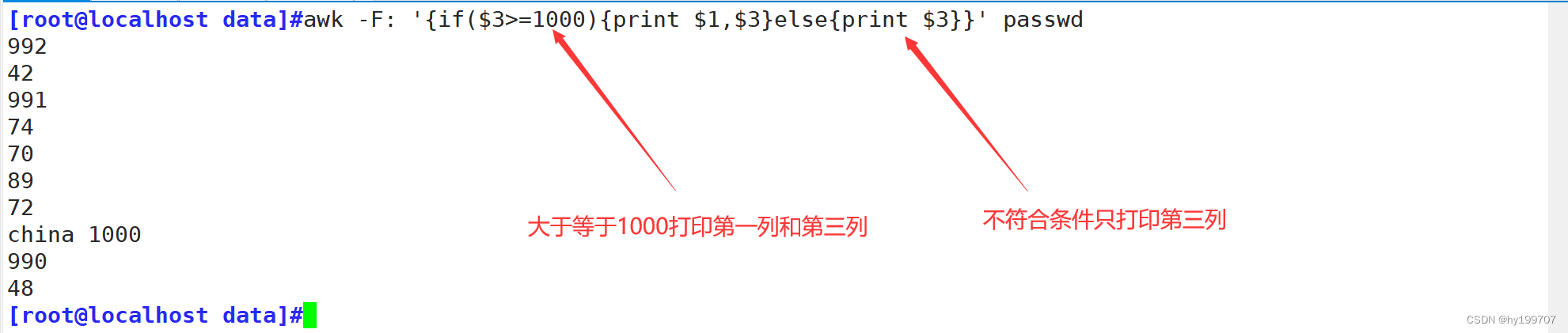
多分支为if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句

(六)数组
awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串
1. 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串
2. awk的数组元素的顺序和元素插入时的顺序很可能是不相同的


文本实战
1.过滤IP地址

[root@localhost ~]#ifconfig ens33|grep netmask|tr -s " "|cut -d " " -f3
192.168.83.30
#ifconfig ens33:只看ens33网卡信息
#grep netmask:过滤包含netmask的行
#tr -s " " : 压缩空格
#cut -d " " -f3:以空格为分隔符,取第三列
[root@localhost ~]#ifconfig ens33|sed -nr 's/ .* inet (.*) netmask.*/1/p'
192.168.83.30
#ifconfig ens33:只看ens33网卡信息
#sed...........:
#-nr:关闭自动打印并开启扩展正则
#.*表示任意字符,第一个.*表示前面的空格
#inet (.*)表示inet后面的任意字符
#netmask.*表示netmask后面的任意字符;
#1表示调用第一个括号中的内容;
#p打印
#打印出第一个括号中的内容,inet 后面的括号,里面的内容就是Ip地址
#需要注意空格符号,inte后面有一个空格 (.*)后面有两个空格 netmask
[root@localhost ~]#ifconfig ens33|awk /netmask/'{print $2}'
192.168.83.30
#ifconfig ens33:只看ens33网卡信息
#awk........
/netmask/ :找到包含netmask的行
{print $2} :打印第二列2.统计网络连接状态
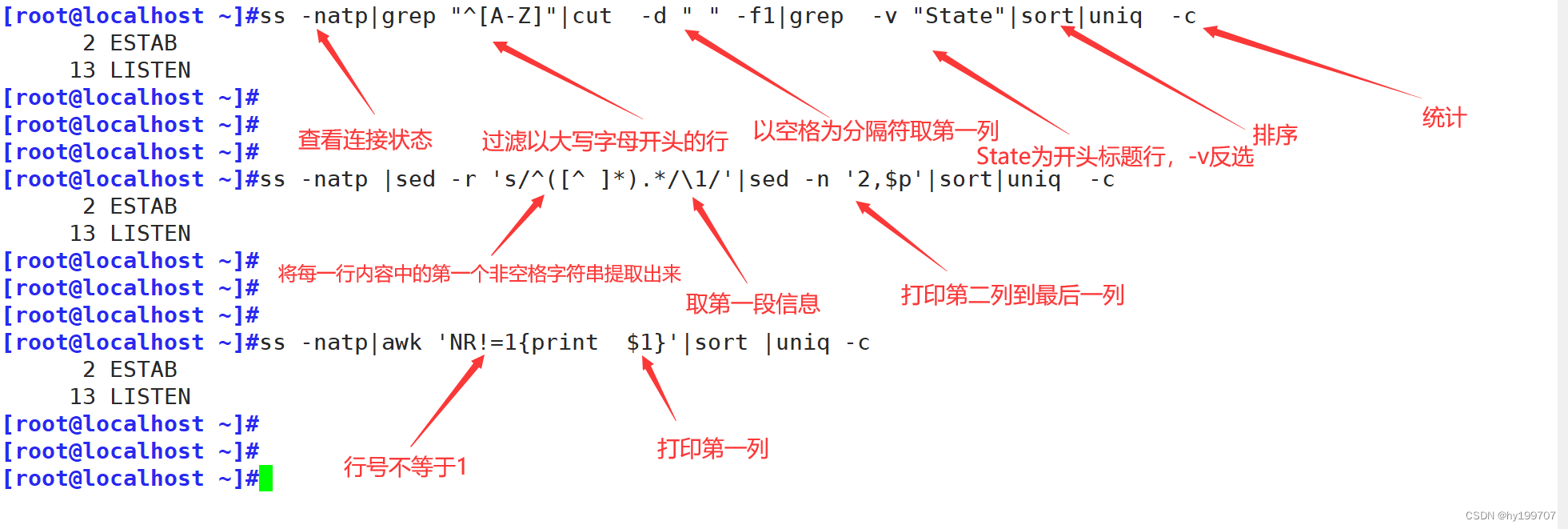
总结:
grep、sed 和 awk是在日常工作中必不可少的操作命令,需要重点去掌握,而正则表达式,是实现文本高效处理的重要组成部分
| 命令名称 | 主要功能 |
| grep | 根据正则表达式搜索文件内容,并打印匹配行。 |
| sed |
对输入流(如文件或管道的输出)进行逐行编辑,可以实现查找、替换、删除、插入 等多种操作。 |
| awk |
基于模式匹配对每一行数据进行处理,支持更复杂的条件判断和字段处理能力,通常 用于结构化数据的处理。 |
原文地址:https://blog.csdn.net/hy199707/article/details/135917857
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_67299.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!