MongoDB索引
官方文档
https://docs.mongodb.com/manual/indexes/#create–an-index
默认索引 _id index
Mongodb 在 collection 创建时会默认建立一个基于_id 的唯一性索引作为 document 的 primarykey,这个 index 无法被删除
单个字段索引
单字段索引是 Mongodb 最简单的索引类型,不同于 MySQL,MongoDB 的索引是有顺序的,支持升序或者降序。
B树组织
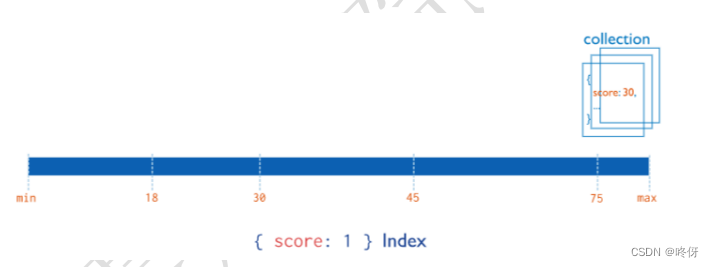
但是对于单字段索引来说,索引的顺序无关紧要,因为 MongoDB 支持任意顺序遍历单字段索引。
在此创建一个 records collection:
{
"_id": ObjectId("570c04a4ad233577f97dc459"),
"score": 1034,
"location": { state: "NY", city: "New York" }
}
然后创建一个 单字段索引:
db.records.createIndex({ score: 1 } )
上面的语句在 collection 的 score field 上创建了一个 升序索引,这个索引支持以下查询:
db.records.find( { score: 2 } )
db.records.find( { score: { $gt: 10 } } )
可以使用 MongoDB 的 explain 来对以上两个查询进行分析:
db.records.find({score:2}).explain('executionStats')
db.records.find({"location.state":"NY"}).explain('executionStats')
嵌套字段的单索引
db.records.createIndex( { "location.state": 1 } )
上面的 embedded index 支持以下查询:
db.records.find( { "location.state": "CA" } )
db.records.find( { "location.city": "Albany", "location.state": "NY" } )
单索引排序
因为索引是排序的,所以可以支持对索引字段的排序(快速)
对于单索引来说,由于 MongoDB index 本身支持顺序查找,所以对于单索引来说以下都是可以使用到索引的
db.records.find().sort( { score: 1 } )
db.records.find().sort( { score: -1 } )
db.records.find({score:{$lte:100}}).sort( { score: -1 } )
复合索引
Mongodb 支持对多个字段建立索引,称之为复合索引。复合索引 中 field 的顺序对索引的性能有至关重要的影响,比如索引 {userid:1, score:-1}首先根据 userid 排序,然后再在每个userid 中根据 score降序排序。
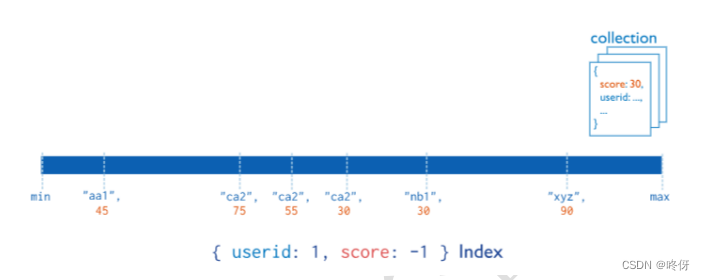
创建复合索引
在此创建一个 products collection:
db.products.insert({
"item": "Banana",
"category": ["food", "produce", "grocery"],
"location": "4th Street Store",
"stock": 4,
"type": "cases"
})
然后创建一个 复合索引:
db.products.createIndex( { "item": 1, "stock": 1 } )
这个 index 引用的 document 首先会根据 item 排序,然后在 每个 item 中,又会根据 stock
排序,以下语句都满足该索引:
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana", stock: { $gt: 5 } } )
条件 {item: “Banana”} 满足是因为这个 query 满足 prefix 原则
最左匹配原则
和MySQL索引最左匹配类似,都是由于底层数据结构组织的原因,MongoDB是B树组织索引,MySQL是B+树组织索引。对于复合索引来说,就需要满足最左匹配的原则Index prefix 是指 index fields 的左前缀子集,考虑以下索引:
{ "item": 1, "location": 1, "stock": 1 }
这个索引包含以下 index prefix:
{ item: 1 }
{ item: 1, location: 1 }
{ "item": 1, "location": 1, "stock": 1 }
所以只要语句满足 index prefix 原则都是可以支持使用 复合索引 的:
db.products.find( { item: "Banana" } )
db.products.find( { item: "Banana",location:"4th Street Store"} )
db.products.find( { item: "Banana",location:"4th Street Store",stock:4})
db.products.find( { location:"4th Street Store",stock:4} )
排序使用复合索引
sort 的顺序必须要和创建索引的顺序是一致的,一致的意思是不一定非要一样
即排序的顺序必须要和索引一致,逆序之后一致也可以,下表清晰的列出了 复合索引 满足的
query 语句:

考虑索引 { a: 1, b: 1, c: 1, d: 1 },即使排序的 field 不满足 index prefix 也是可以的,
但前提条件是排序 field 之前的 index field 必须是等值条件。在前面的field是等值条件情况下,B树索引构建时,在前置filed相同时,会根据后面的field排序构建,所以这种情况的排序是可以使用索引查找到对应数据的。
r1 db.data.find( { a: 5 } ).sort( { b: 1, c: 1 } ) { a: 1 , b: 1, c: 1 }
r2 db.data.find( { b: 3, a: 4 } ).sort( { c: 1 } ) { a: 1, b: 1, c: 1 }
r3 db.data.find( { a: 5, b: { $lt: 3} } ).sort( { b: 1 } ) { a: 1, b: 1 }
field顺序对索引的影响
对索引构建是没太大影响,但是对于需要扫描的文档,顺序的不同可能差别就很大了。个人理解是对基数大(数据重复度低)的字段排在前面。优先考虑能够最大化限制数据范围的索引顺序。
慢查询监控
对于查询的优化,我们可以开启慢查询监控:
MongoDB 支持对 DB 的请求进行 profiling,目前支持 3 种级别的 profiling。
- 0: 不开启 profiling
- 1: 将处理时间超过某个阈值(默认 100ms)的请求都记录到 DB 下的 system.profile 集合 (类似于 mysql、redis 的 slowlog)
- 2: 将所有的请求都记录到 DB 下的 system.profile 集合(生产环境慎用)
通常,生产环境建议使用 1 级别的 profiling,并根据自身需求配置合理的阈值,用于监测慢请求的情况,并及时的做索引优化。
如果能在集合创建的时候就能『根据业务查询需求决定应该创建哪些索引』,当然是最佳的选择;但由于业务需求多变,要根据实际情况不断的进行优化。索引并不是越多越好,集合的索引太多,会影响写入、更新的性能,每次写入都需要更新所有索引的数据;所以你 system.profile 里的慢请求可能是索引建立的不够导致,也可能是索引过多导致。
创建删除索引
原文地址:https://blog.csdn.net/qq_43058348/article/details/134548677
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6849.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!