前面介绍了1、可视化方法;2、机器学习预测应用;3、图像识别;4、文本分析相关的案例研究(具体见之前的文章)。
本期将继续做关于数据分析类实战系列文章,列举一些在平时数据处理中经常遇到的一些小问题,提供一个解决方案,让读者慢慢理解python数据分析的原理和方法,每一篇文章从实现功能、实现代码、实现效果三个方面进行展示。
实现功能:
字典、列表(数组)、序列创建DataFrame并保存为excel文件
实现代码:
#Python中创建DataFrame的方法
import pandas as pd
import numpy as np
#1、字典生成
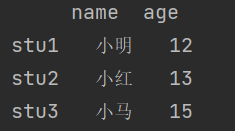
students = {'name':['小明','小红','小马'],'age':[13,14,15],'grade':['七年级','八年级','九年级']}
df1 = pd.DataFrame(students,index=['stu1','stu2','stu3'])
print(df1)
#2、列表生成
#2.1字典组成的列表转化为dataframe
df2 =pd.DataFrame([{'one': 1, 'two': 2}, {'one': 5, 'two': 10, 'three': 20}],index=[1,2])
print(df2)
#2.2两个一维列表转化为dataframe
Name=['小明','小红','小马']
Marks=[12,13,15]
list_tuples=list(zip(Name,Marks))
df3=pd.DataFrame(data=list_tuples,columns=['name','age'],index=['stu1','stu2','stu3'])
print(df3)
#2.3一个二维列表/数组转化为dataframe
list1 = [['小明',13,'七年级'],['小红',14,'八年级'],['小马',15,'九年级']]
df4 = pd.DataFrame(data=list1,columns=['name','age','grade'],index=['stu1','stu2','stu3'])
print(df4)
arr = np.arange(9).reshape(3,3)
df5 = pd.DataFrame(data=arr, index = ['a', 'b', 'c'], columns = ['one','two','three'])
print(df5)
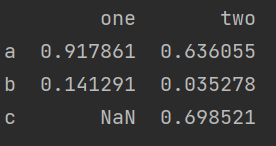
#3、Series生成
s1=pd.Series(np.random.rand(2), index = ['a','b'])
s2=pd.Series(np.random.rand(3),index = ['a','b','c'])
df6 =pd.DataFrame({'one':s1,'two':s2})
print(df6)上面介绍了创建DataFrame的几种方式,接着使用DataFrame.to_excel()方法即可将DataFrame内容保持到指定路径的Excel文件。
实现效果:




本人读研期间发表5篇SCI数据挖掘相关论文,现在某研究院从事数据挖掘相关科研工作,对数据挖掘有一定认知和理解,会结合自身科研实践经历不定期分享关于python机器学习、深度学习、数据挖掘基础知识与案例。
致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。
关注V订阅号:数据杂坛可在后台联系我获取相关数据集和源码,送有关数据分析、数据挖掘、机器学习、深度学习相关的电子书籍。
原文地址:https://blog.csdn.net/sinat_41858359/article/details/128853379
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6905.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





