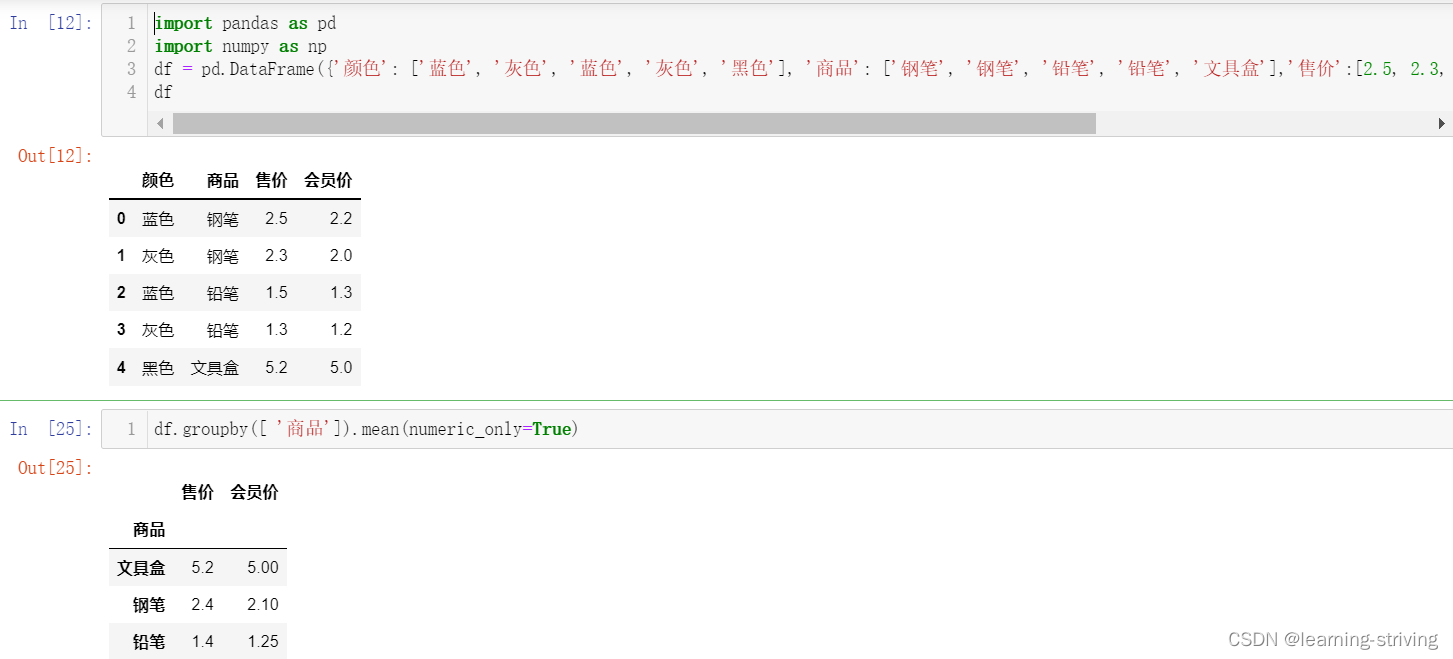
BaseGroupBy类中有一个grouper属性,是ops.BaseGrouper类型,但BaseGroupBy类没有__init__方法,因此进入GroupBy类,该类重写了父类的grouper属性,在__init__方法中调用了grouper.py的get_grouper,下面是抽取出来的伪代码
class GroupBy(BaseGroupBy[NDFrameT]):
grouper: ops.BaseGrouper
def __init__(self, ...):
# ...
if grouper is None:
from pandas.core.groupby.grouper import get_grouper
grouper, exclusions, obj = get_grouper(...)
def get_grouper(...) -> tuple[ops.BaseGrouper, frozenset[Hashable], NDFrameT]:
# ...
# create the internals grouper
grouper = ops.BaseGrouper(
group_axis, groupings, sort=sort, mutated=mutated, dropna=dropna
)
return grouper, frozenset(exclusions), obj
class Grouping:
"""
obj : DataFrame or Series
"""
def __init__(
self,
index: Index,
grouper=None,
obj: NDFrame | None = None,
level=None,
sort: bool = True,
observed: bool = False,
in_axis: bool = False,
dropna: bool = True,
):
pass
class BaseGrouper:
"""
This is an internal Grouper class, which actually holds
the generated groups
......
"""
def __init__(self, axis: Index, groupings: Sequence[grouper.Grouping], ...):
# ...
self._groupings: list[grouper.Grouping] = list(groupings)
@property
def groupings(self) -> list[grouper.Grouping]:
return self._groupings
BaseGrouper中包含了最终生成的分组信息,是一个list,其中的元素类型为grouper.Grouping,每个分组对应一个Grouping,而Grouping中的obj对象为分组后的DataFrame或者Series
在第一部分写了一个函数来展示groupby返回的对象,这里再来探究一下原理,对于可迭代对象,会实现__iter__()方法,先定位到BaseGroupBy的对应方法
class BaseGroupBy:
grouper: ops.BaseGrouper
@final
def __iter__(self) -> Iterator[tuple[Hashable, NDFrameT]]:
return self.grouper.get_iterator(self._selected_obj, axis=self.axis)
class BaseGrouper:
def get_iterator(
self, data: NDFrameT, axis: int = 0
) -> Iterator[tuple[Hashable, NDFrameT]]:
splitter = self._get_splitter(data, axis=axis)
keys = self.group_keys_seq
for key, group in zip(keys, splitter):
yield key, group.__finalize__(data, method="groupby")
Debug模式进入group.finalize()方法,发现返回的确实是DataFrame对象

三、4大函数
有了上面的基础,接下来再看groupby之后的处理函数,就简单多了
agg
聚合操作是groupby后最常见的操作,常用来做数据分析
比如,要查看不同category分组的最大值,以下三种写法都可以实现,并且grouped.aggregate和grouped.agg完全等价,因为在SelectionMixin类中有这样的定义:agg = aggregate

但是要聚合多个字短时,就只能用aggregate或者agg了,比如要获取不同category分组下price最大,count最小的记录

还可以结合numpy里的聚合函数
import numpy as np
grouped.agg({'price': np.max, 'count': np.min})
| 聚合函数 | 功能 |
|---|---|
| max | 最大值 |
| mean | 平均值 |
| median | 中位数 |
| min | 最小值 |
| sum | 求和 |
| std | 标准差 |
| var | 方差 |
| count | 计数 |
其中,count在numpy中对应的调用方式为np.size
transform
现在需要新增一列price_mean,展示每个分组的平均价格
transform函数刚好可以实现这个功能,在指定分组上产生一个与原df相同索引的DataFrame,返回与原对象有相同索引且已填充了转换后的值的DataFrame,然后可以把转换结果新增到原来的DataFrame上
示例代码如下
grouped = df.groupby('category', sort=False)
df['price_mean'] = grouped['price'].transform('mean')
print(df)

apply
现在需要获取各个分组下价格最高的数据,调用apply可以实现这个功能,apply可以传入任意自定义的函数,实现复杂的数据操作
from pandas import DataFrame
grouped = df.groupby('category', as_index=False, sort=False)
def get_max_one(the_df: DataFrame):
sort_df = the_df.sort_values(by='price', ascending=True)
return sort_df.iloc[-1, :]
max_price_df = grouped.apply(get_max_one)
max_price_df

filter
filter函数可以对分组后数据做进一步筛选,该函数在每一个分组内,根据筛选函数排除不满足条件的数据并返回一个新的DataFrame
假设现在要把平均价格低于4的分组排除掉,根据transform小节的数据,会把蔬菜分类过滤掉
grouped = df.groupby('category', as_index=False, sort=False)
filtered = grouped.filter(lambda sub_df: sub_df['price'].mean() > 4)
print(filtered)

四、总结
groupby的过程就是将原有的DataFrame/Series按照groupby的字段,划分为若干个分组DataFrame/Series,分成多少个组就有多少个分组DataFrame/Series。因此,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame/Series的操作。理解了这点,就理解了Pandas中groupby操作的主要原理
五、参考文档
Pandas官网关于pandas.DateFrame.groupby的介绍
Pandas官网关于pandas.Series.groupby的介绍
原文地址:https://blog.csdn.net/u013481793/article/details/127158683
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6931.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!