mariadb是mysql的另外一个选择了,具体就不再介绍,这里主要介绍主主集群的配置方式,大家要注意,尽管为主主集群,在数据写入时,尤其是在连接rabbitmq时,写入操作建议还是从指定单点写入,多点同时写入会出现错误,所以做高可用时将第一台服务器专门作为写入,其他的作为备份服务器,读取的时候不用管。
1、Mariadb安装(所有节点)
###mariadb在centos9上面安装
###先查看yum源的安装包
yum list | grep mariadb
mariadb.x86_64 3:10.5.16-2.el9 @appstream
mariadb-backup.x86_64 3:10.5.16-2.el9 @appstream
mariadb-common.x86_64 3:10.5.16-2.el9 @appstream
mariadb-connector-c.x86_64 3.2.6-1.el9 @appstream
mariadb-connector-c-config.noarch 3.2.6-1.el9 @appstream
mariadb-errmsg.x86_64 3:10.5.16-2.el9 @appstream
mariadb-gssapi-server.x86_64 3:10.5.16-2.el9 @appstream
mariadb-server.x86_64 3:10.5.16-2.el9 @appstream
mariadb-server-galera.x86_64 3:10.5.16-2.el9 @appstream
mariadb-server-utils.x86_64 3:10.5.16-2.el9 @appstream
mariadb-connector-c.i686 3.2.6-1.el9 appstream
mariadb-connector-c-devel.i686 3.2.6-1.el9 appstream
mariadb-connector-c-devel.x86_64 3.2.6-1.el9 appstream
mariadb-connector-c-doc.noarch 3.2.6-1.el9 crb
mariadb-connector-c-test.x86_64 3.2.6-1.el9 crb
mariadb-connector-odbc.x86_64 3.1.12-3.el9 appstream
mariadb-devel.x86_64 3:10.5.16-2.el9 crb
mariadb-embedded.x86_64 3:10.5.16-2.el9 appstream
mariadb-embedded-devel.x86_64 3:10.5.16-2.el9 crb
mariadb-java-client.noarch 3.0.3-1.el9 appstream
mariadb-oqgraph-engine.x86_64 3:10.5.16-2.el9 appstream
mariadb-pam.x86_64 3:10.5.16-2.el9 appstream
mariadb-test.x86_64 3:10.5.16-2.el9 crb ###安装相关软件,有些依赖建议同时安装上
yum install mariadb-server mariadb mariadb-devel -y
2、配置集群
配置文件 /etc/my.cnf.d/mariadb-server.cnf:
###以下是一个节点的配置文件
[mysqld]
bind-address=0.0.0.0
#server-id各个服务器的id顺序1、2、3就行,各不相同
server-id=1
log-bin=mysql-bin
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
# replication settings
#这里
binlog-format=ROW
log-slave-updates=1
auto-increment-increment=2
auto-increment-offset=1
replicate-wild-ignore-table=mysql.%
#####下面是建议配置
#修改数据存储目录
datadir=/data/mariadb/data
#修改日志存储路径
log-error=/data/mariadb/logs/mariadb.log
pid-file=/run/mariadb/mariadb.pid
innodb_file_per_table=ON
character-set-server = utf8
collation-server = utf8_general_ci
max_connections = 4096
skip_name_resolve=ON
skip-external-locking=ON
max_allowed_packet = 1G
innodb_buffer_pool_size = 8G
innodb_lock_wait_timeout = 900
###这里是主主集群的关键地方,可以在这个文件中配置,也可以单独去修改galera.cnf文件中的配置
# cluster settings
wsrep_on=ON
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
#集群名称,自己定义吧
wsrep_cluster_name=my_cluster
#按顺序写主机ip
wsrep_cluster_address=gcomm://node1_ip,node2_ip,node3_ip
#当前主机的ip
wsrep_node_address=node1_ip
#当前主机的hostname
wsrep_node_name=node1
#同步方式
wsrep_sst_method=rsync
####################
#其他两个或多个节点需要修改的地方
server_id
wsrep_node_address
wsrep_node_name
#如果其他服务器硬件配置不一样,可能还需要数据存储目录,最大连接数等优化参数
#大家根据实际需求调整
配置文件中的参数说明
在这个示例中,我们使用了Galera Cluster来实现多主复制。配置文件中的参数说明如下:
– `bind–address`:指定绑定的ip地址,0.0.0.0表示所有地址。
– `server-id`:指定该节点的唯一标识。
– `log–bin`:开启二进制日志。
– `datadir`:指定数据文件的存放位置。
– `socket`:指定mysql连接的套接字文件位置。
– `binlog–format`:指定二进制日志的格式,这里选择ROW模式。
– `log–slave–updates`:让从库写入它的二进制日志。
– `auto-increment-increment`和`auto-increment-offset`:这些设置可以控制插入到不同节点中的自增id的值不相同,以避免重复。
– `replicate-wild-ignore-table=mysql.%`:将mysql系统表的更新排除在复制之外。
– `wsrep_on`:开启Galera Cluster插件。
– `wsrep_provider`:指定Galera Cluster插件的路径。
– `wsrep_cluster_name`:指定集群名称。
– `wsrep_cluster_address`:指定集群中的节点地址。
– `wsrep_node_address`:指定当前节点的地址。
– `wsrep_node_name`:指定当前节点的名称。
– `wsrep_sst_method`:指定Galera Cluster的同步方式,这里选择rsync。
3、集群启动
集群全新第一次启动
#进入第一个节点
galera_new_cluster
#进入第二个节点
systemctl enable mariadb --now
#其他节点与第二个节点相同启动就行了。
#第一个节点使用galera_new_cluster后可能会挂住,在其他节点启动成功后
#可以使用ctrl + c 取消,然后重启mariadb
systemctl restart mariadb已有数据的集群迁移后重新启动集群,同时这个也是(集群全部down后重启或出现脑裂后重启的方式)
###所有节点的数据都备份一次
###首先大家要确认哪个节点的数据是最新最全的,然后进入该节点
###配置各个节点的conf配置,依照前面文件配置即可
#进入数据最新的这个节点,进入mariadb的数据目录
#查看目录中的grastate.dat 这个文件
cat grastate.dat
# GALERA saved state
version: 2.1
uuid: 0ca27522-40f6-11ee-8a09-d613df2283ac
seqno: -1
safe_to_bootstrap: 0
#这里面如果uuid为空或者全为0的需要自己使用uuid-gen方式新生成一个,然后所有节点设置成一样
先看看grastate.dat文件各参数的说明:
seqno: 这个只有在正常关闭后会将最新的处理号记录在这里,这个值越大,表示数据越全,重启之后用于判断是否进行IST还是SST用的,判断完之后,就会置成-1
-1的情况:
1、服务异常关闭(或者kill -9的方式杀掉)
2、服务在运行状态
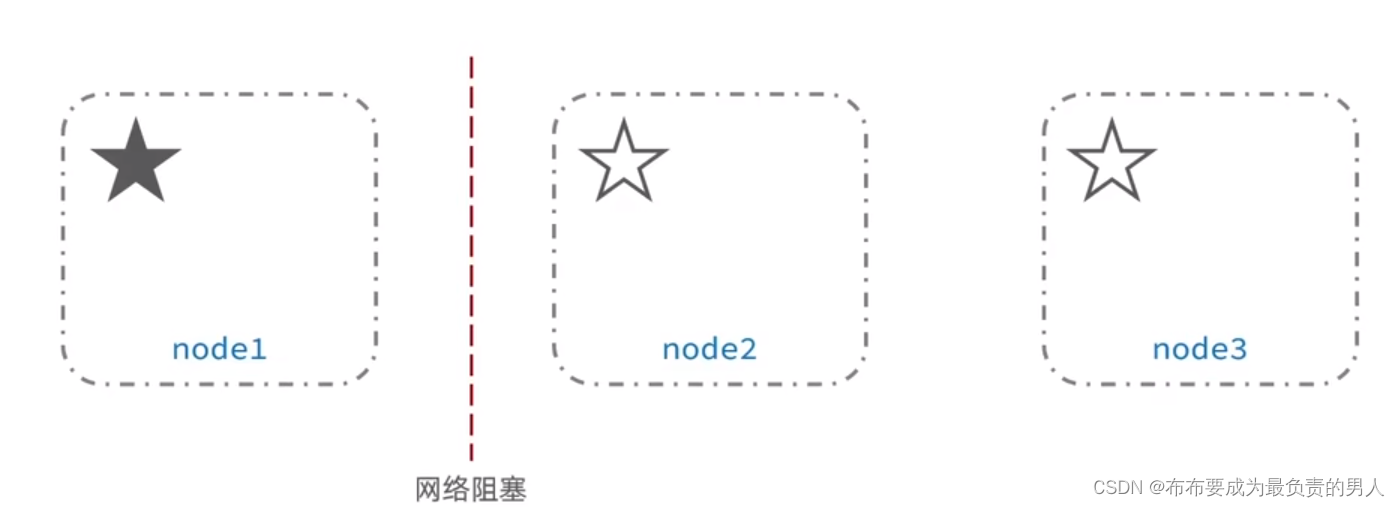
safe_to_bootstrap: 这个值是用来判断是否是主节点,0-表示非引导节点,1-表示引导节点(引导节点-最后关闭的节点)
###所以我们在确认的引导节点修改grastate.dat 这个文件
# GALERA saved state
version: 2.1
uuid: 0ca27522-40f6-11ee-8a09-d613df2283ac
seqno: 34342
safe_to_bootstrap: 1
#seqno大于0就行
#safe_to_bootstrap设为1
#####################
#在其他两个非引导节点则可删除data目录后重新启动,
#或修改seqno为-1,safe_to_bootstrap为0
#然后再重启mariadb4、高可用配置建议
########haproxy文件中
#---------------------------------------------------------------------
# listen maridb galera cluster for write
#---------------------------------------------------------------------
listen mariadb_galera4openstack
bind 110.110.110.151:42306
mode tcp
option tcplog
option tcpka
server host1 110.110.110.11:3306 check
server host2 110.110.110.12:3306 check backup
server host3 110.110.110.13:3306 check backup
###可以看出,这里直接将host2和host3都设置为backup,这样保证数据写入都从单个节点写入
#########当然在读数据时不需要这么限制了,可以使用平衡方式随机读取或轮询
balance roundrobin5、验证安装
#查看集群节点数
mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size';"
#其他命令:
SHOW STATUS LIKE 'wsrep_%';
galera_wsrep_status -u root -p
数据写入操作验证,这里就不操作了,大家随意进入其中一个数据库节点新建数据库后进入其他两个节点查看第一个节点新建的数据库是否都有出现即可。
6、多主galera集群脑裂恢复
-
手动修复脑裂:如果发生了脑裂,可能需要手动干预以恢复集群的一致性。这可能涉及将脑裂的节点隔离、重新加入集群或将其从集群中移除。下面是一些可能用到的命令:
-
Galera Cluster Management 工具:Galera 提供了一些管理工具来处理集群的恢复。例如,
galera_recovery工具可以用于处理脑裂的情况,修复节点状态,并尝试将集群恢复到一致状态。#这个命令在数据库重启失败时可能也有效,但请先做好数据备份再操作 galera_recovery -u root -p
原文地址:https://blog.csdn.net/zrc_xiaoguo/article/details/134697892
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_8427.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!