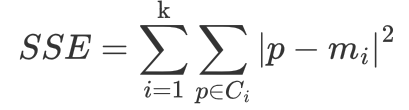使用 Pygame 模块演示了 K-Means 聚类算法的基本原理。让我逐步解释它的实现:
初始化和基本设置
Pygame 初始化: 通过 pygame.init() 初始化 Pygame。
定义颜色和屏幕大小: 定义了一些颜色常量(WHITE, BLACK, RED, GREEN, BLUE)和屏幕的宽度和高度。
创建 Pygame 窗口: 使用 pygame.display.set_mode 创建窗口,设置窗口标题。
生成随机数据点和初始聚类中心
生成随机数据点: 使用 random.randint 在屏幕范围内生成随机数据点,存储在 points 列表中。
生成初始聚类中心: 使用 random.randint 生成初始的聚类中心,存储在 clusters 列表中。
主循环
事件处理: 在主循环中,检测是否有退出事件,如果有,则退出主循环。
绘制数据点和聚类中心: 使用 pygame.draw.circle 绘制数据点和聚类中心。
计算每个数据点的分配: 计算每个数据点到各个聚类中心的距离,将其分配到距离最近的聚类中心。
更新聚类中心: 根据每个簇的数据点,更新聚类中心为该簇内数据点的平均位置。
显示数据点与聚类中心之间的连线: 使用 pygame.draw.line 显示每个数据点与其所属簇的聚类中心之间的连线。
刷新显示: 使用 pygame.display.flip() 刷新显示。
退出 Pygame
退出 Pygame: 在退出时调用 pygame.quit() 关闭 Pygame。
演示效果
这段代码在每一次主循环中执行 K-Means 算法的一次迭代,同
原文地址:https://blog.csdn.net/weixin_41194129/article/details/134724074
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_15495.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!