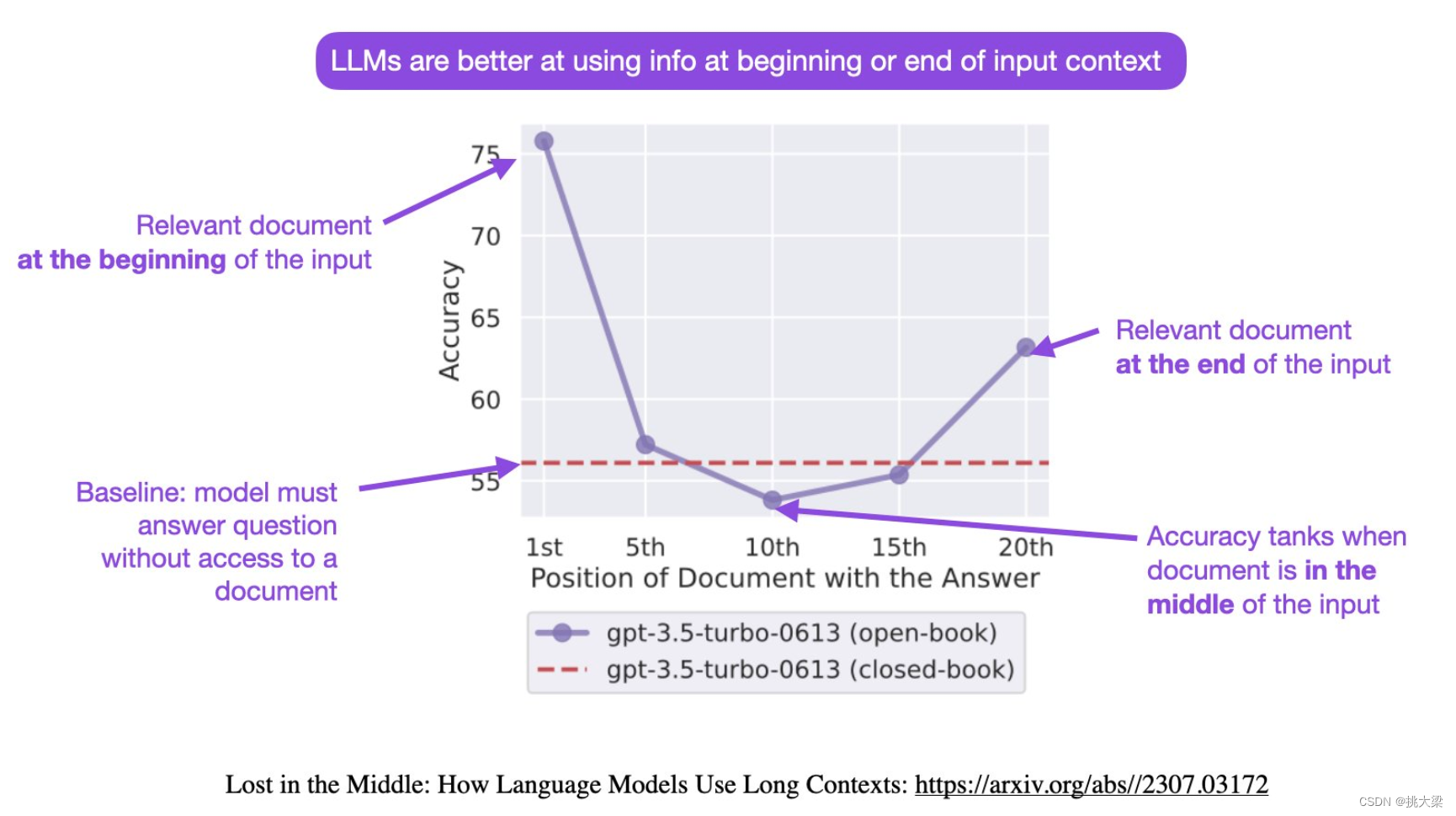
分割模型向比较灵活的分割的趋势的转变:封闭到开放,通用到特定、one–shot到交互式。From closed–set to open–vocabulary segmentation,From generic to referring segmentation,From one-shot to interactive segmentation。
图片:![]()
通过Text_Encoder得到文本提示Pt:Text_Encoder(prompt_text)
Pm初始化None,后面结合特征和之前的mask通过MaskedCrossAtt得到:![]()
这样就得到了![]()
相应的提示通过自我注意力与查询交互。可学习查询可以在推理时与所有提示自由交互。
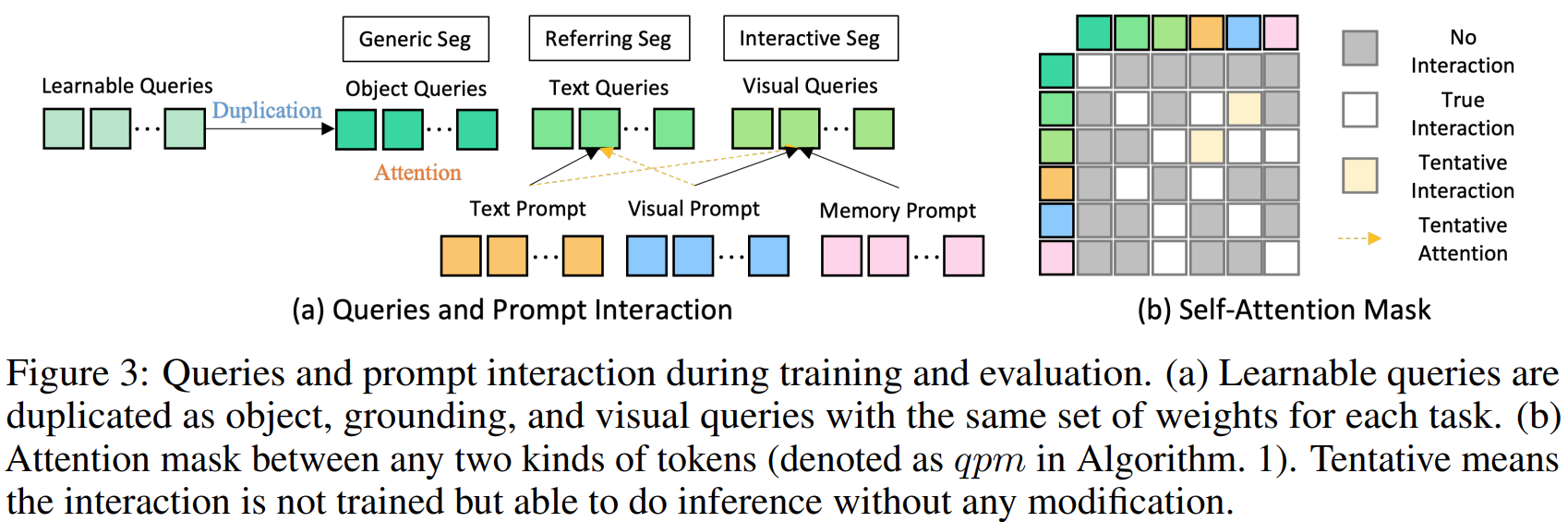
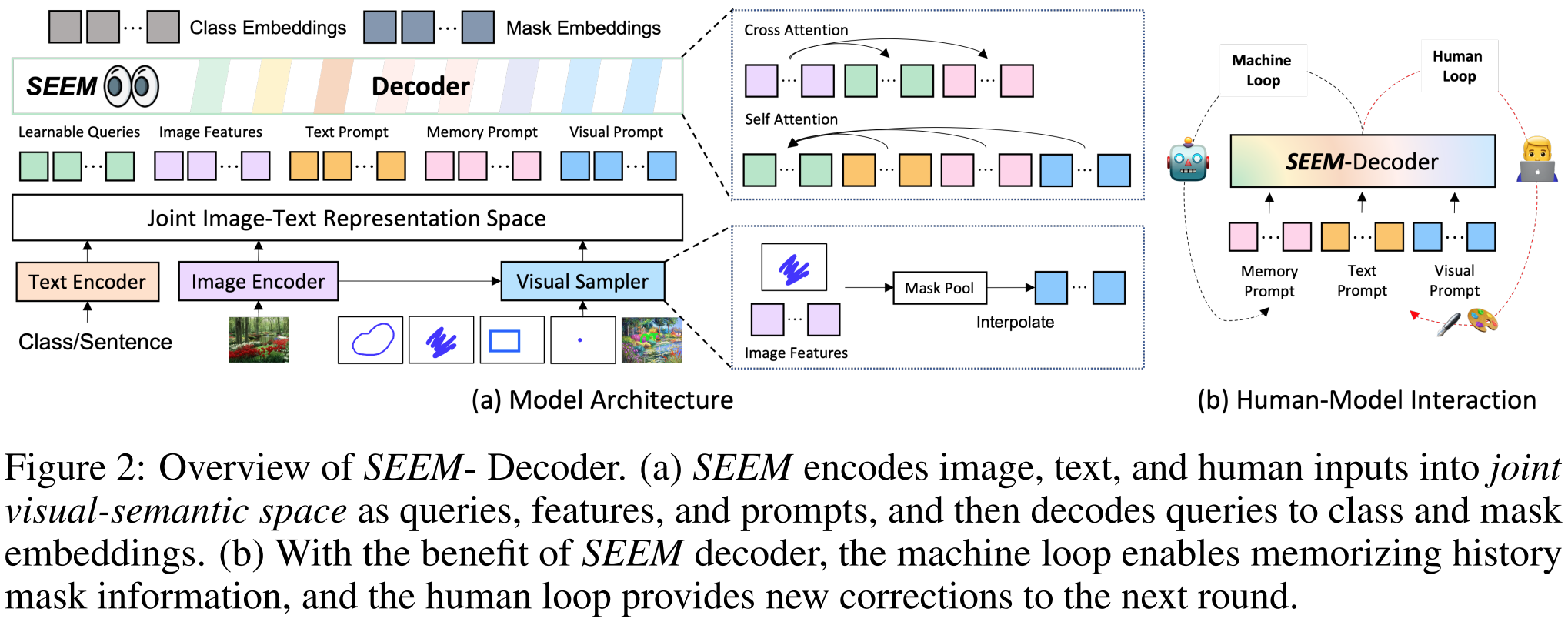
也就是说,一张图片经过一个Img_Encoder得到特征Z;初始化一个可学习的查询Qh,并把它复制三份得到![]() (即object, text and visual queries)三种查询的初始化。然后文本提示用Text_Encoder得到文本提示Pt,Pv通过VisualSampler得到。Pm初始化None,后面结合特征和之前的mask通过MaskedCrossAtt得到。
(即object, text and visual queries)三种查询的初始化。然后文本提示用Text_Encoder得到文本提示Pt,Pv通过VisualSampler得到。Pm初始化None,后面结合特征和之前的mask通过MaskedCrossAtt得到。
其中,VisualSampler应该是根据s,即prompt,通过点采样从图像特征中提取相应的区域,然后在这个区域均匀地插值最多512点特征向量。MaskedCrossAtt中,Mp是先前的mask, 而Z是图像特征图。通过这种方式,交叉关注仅在上一个掩码指定的区域内生效。更新后的记忆提示![]() 然后通过自我注意与其他提示交互,以传达本轮的历史信息。
然后通过自我注意与其他提示交互,以传达本轮的历史信息。
得到这些查询、提示和图片特征后,他们自己可以通过注意力机制进行交互,得到![]() ,然后再预测mask M和类别 C。
,然后再预测mask M和类别 C。

在实践中,用户可以使用不同的或组合的提示类型来表达他们的意图。因此,提示的组合方法对于现实世界的应用是必不可少的。然而,在模型训练过程中,我们面临两个问题。首先,训练数据通常只涵盖单一类型的交互(例如,无、文本、视觉)。其次,尽管我们使用视觉提示来统一所有非文本提示,并将它们与文本提示对齐,但它们的嵌入空间本质上仍然不同。为了缓解这个问题,我们建议将不同类型的提示与不同的输出进行匹配。考虑到视觉提示Pv来自图像特征,而文本提示Pt来自文本编码器,我们通过将视觉提示和文本提示分别与掩码嵌入Omh或类嵌入Och匹配来选择匹配的输出索引:
![]()
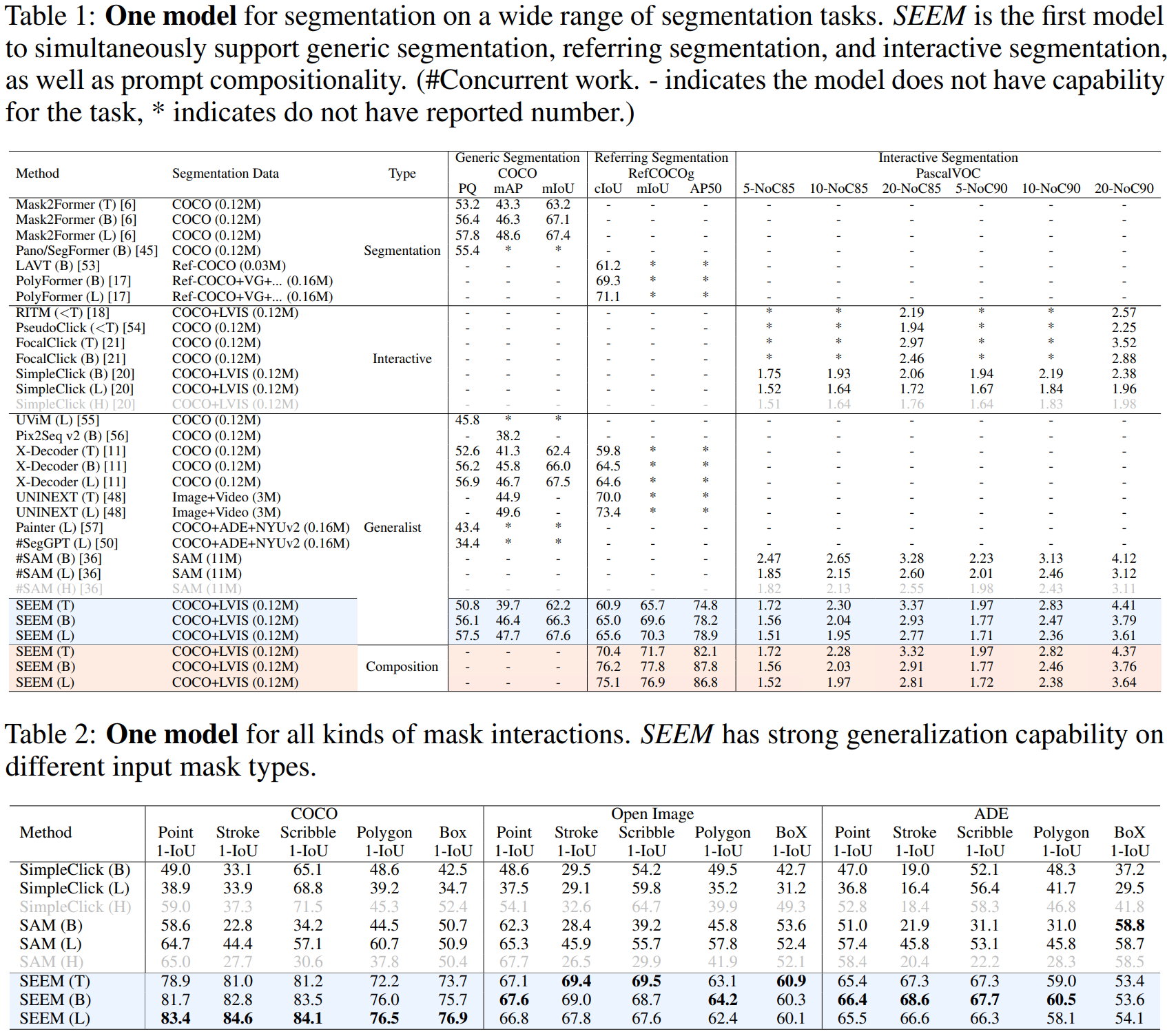
之前的分割模型,比如SAM的分割是类别不可知的,即class-agnostic,SEEM以零样本的方式为各种提示组合的掩码产生语义标签.
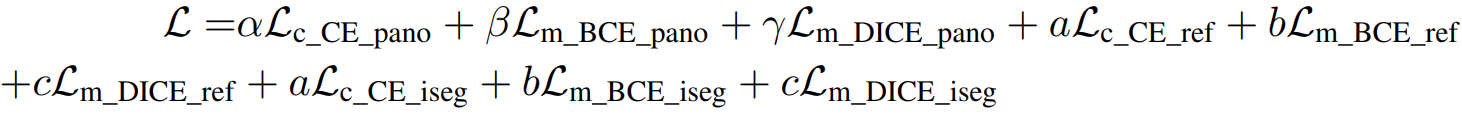
![]()
SEEM的伪代码如下:

实验部分:
原文地址:https://blog.csdn.net/weixin_43575791/article/details/134681812
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_11661.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!