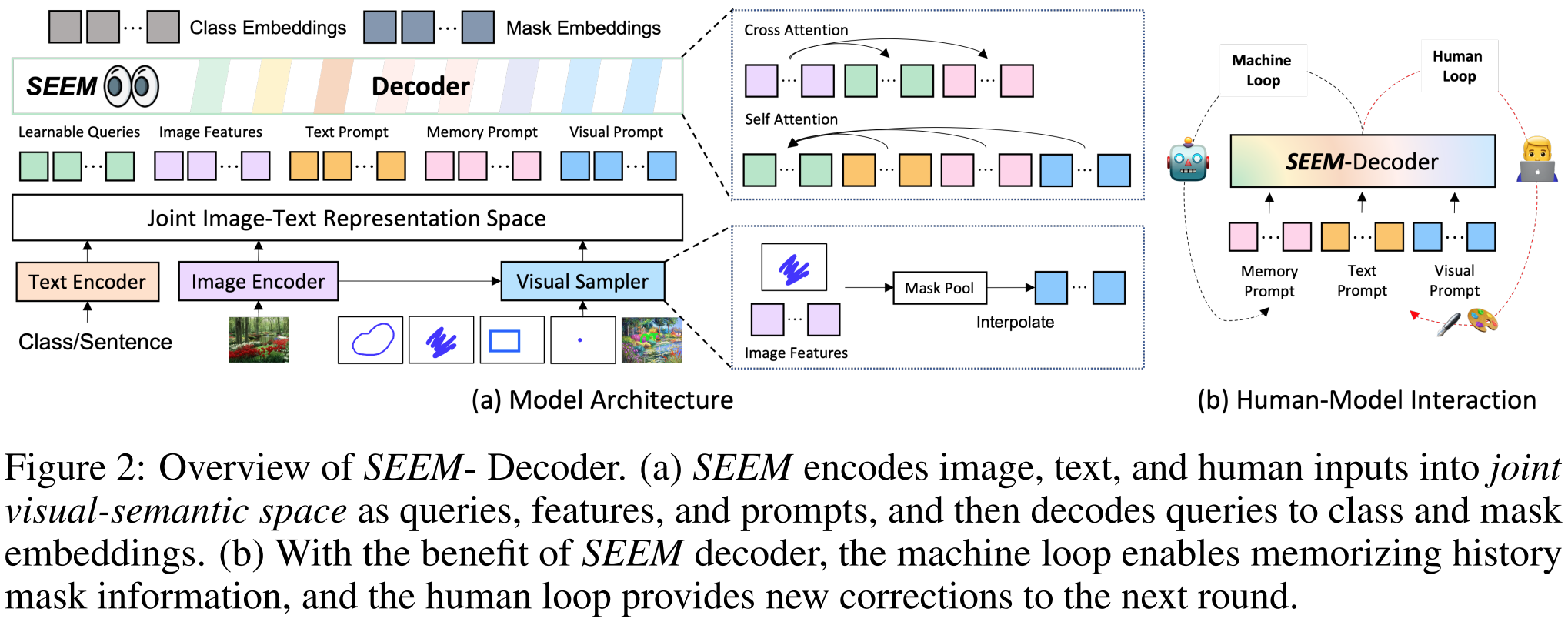
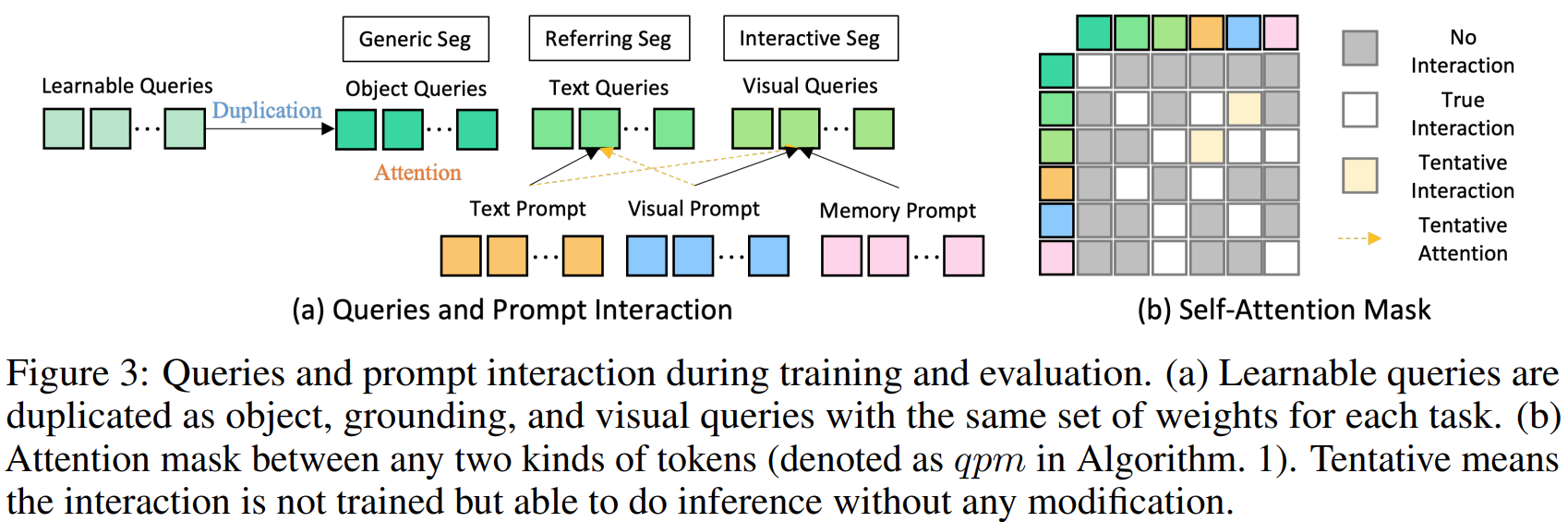
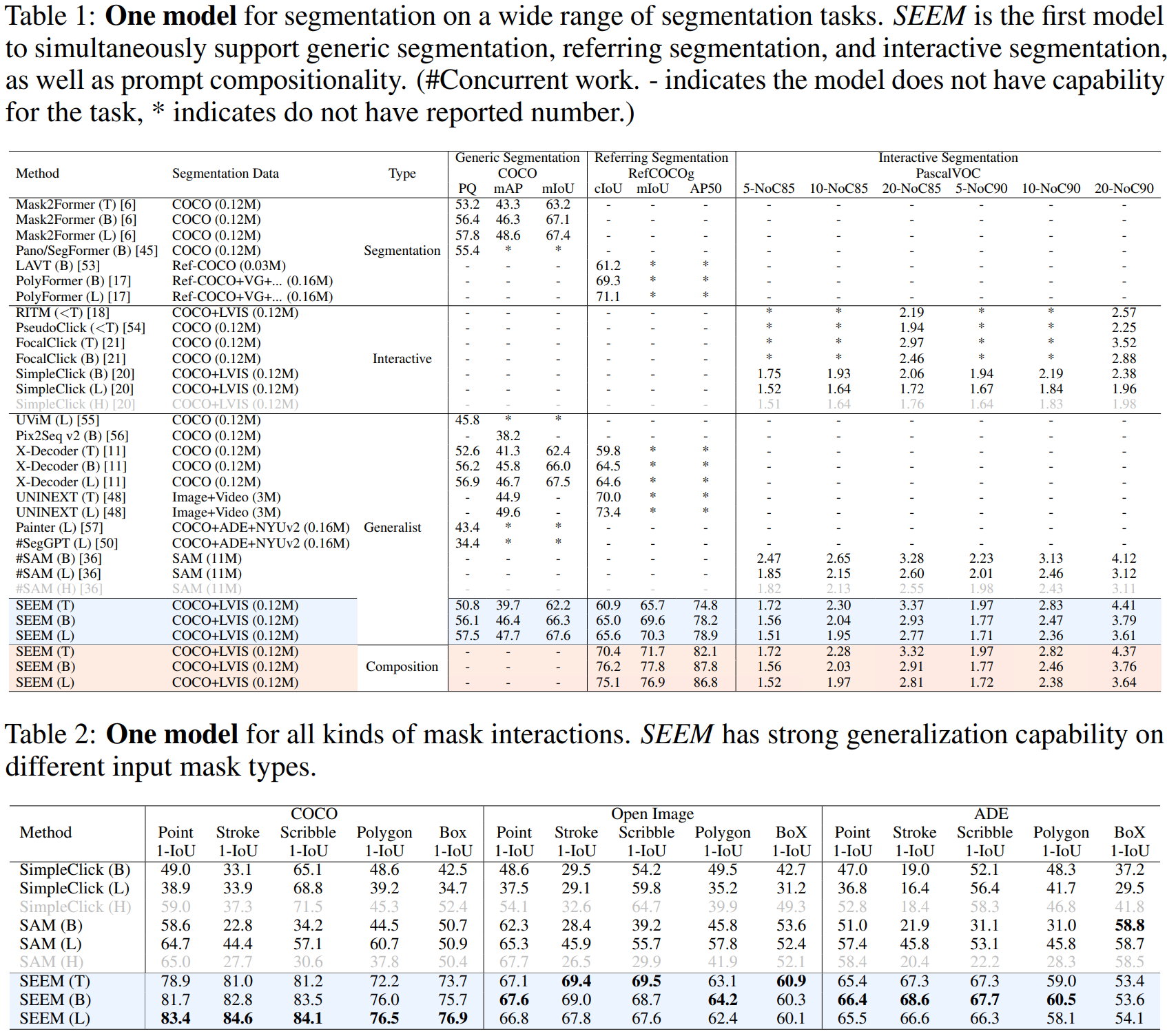
本文介绍: 其次,尽管我们使用视觉提示来统一所有非文本提示,并将它们与文本提示对齐,但它们的嵌入空间本质上仍然不同。分割模型向比较灵活的分割的趋势的转变:封闭到开放,通用到特定、one–shot到交互式。其中,VisualSampler应该是根据s,即prompt,通过点采样从图像特征中提取相应的区域,然后在这个区域均匀地插值最多512点特征向量。之前的分割模型,比如SAM的分割是类别不可知的,即class-agnostic,SEEM以零样本的方式为各种提示组合的掩码产生语义标签.相应的提示通过自我注意力与查询交互。
分割模型向比较灵活的分割的趋势的转变:封闭到开放,通用到特定、one–shot到交互式。From closed–set to open–vocabulary segmentation,From generic to referring segmentation,From one-shot to interactive segmentation。
图片:![]()

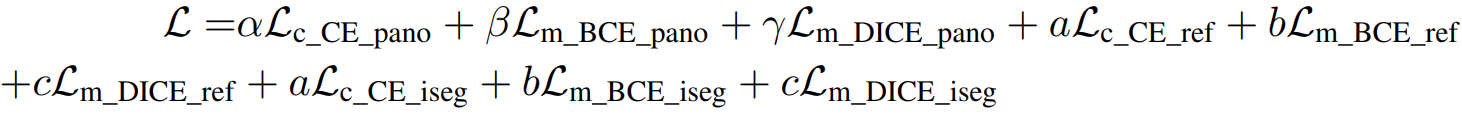

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。