这个模型分为两阶段:一是答案启发生成阶段(answer heuristics generation stage),即在一个基于知识的VQA数据集上训练一个普通的VQA模型,产生两种类型的答案启发,答案候选列表和答案例子;二是启发增强提示阶段(heuristics-enhanced prompting stage),即将答案启发、问题、描述融合为一个格式化的提示prompt,引导GPT-3预测答案。
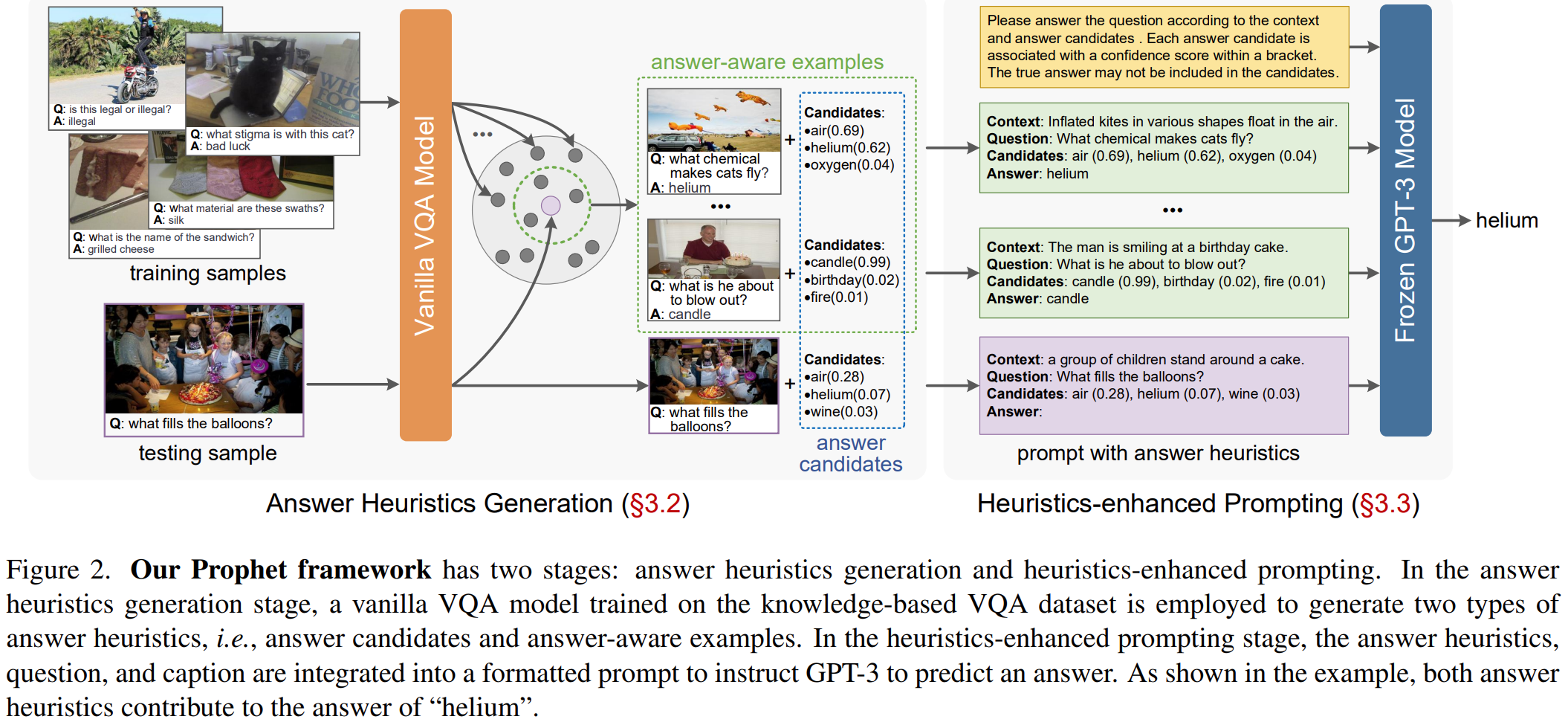
本文的方法采用了PICa这个方法的pipline。PICa方法大致如下:
![]()
具体在利用GPT-3的in-context few-shot learning能力时,输入下面这个,C是caption,对一张图片的描述,Q、A分别的问题、答案。
![]()
本文的方法使用上面这个框架,但是增加了答案启发,也就是:Context、Question、Candidates、Answer。

where j1, j2, · · · , jK correspond to the actual indices of the elements in Ci
区别:
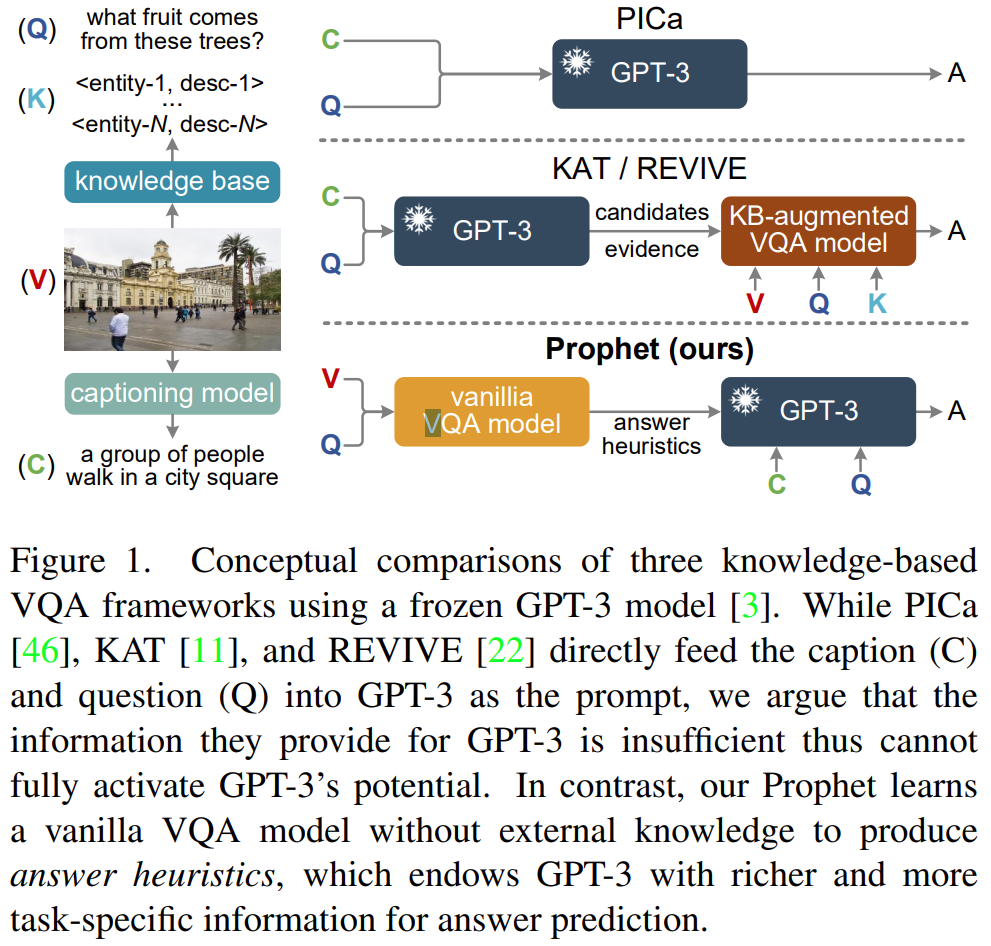
二、Stage-1. Answer Heuristics Generation
首先介绍VQA模型,有一个数据集D,一个答案词库W,一个VQA模型可以分为两部分,一部分是backbone Mb,一部分是分类头Mh,骨干网络用来将输入的图片和问题融合为一个特征z,分类器一般是简单的线性分类器,得到yi,表示得到得到答案wi的分数。
VQA model M is learned from D to perform an S-way classification over the answers.
![]()
![]()
![]()
![]()
![]()
where y[i] denotes the i-th element of y, representing the confidence score for answer wi .
从VQA得到的答案y里面选出前K个答案
![]()
![]()
wj and y[j] are an answer candidate and its confidence score。
test输入(v,q)->z,train输入(vi,qi)->zi,所以作者推测这些融合特征位于一个潜在的答案空间中,该空间包含给定图像-问题对的答案的丰富语义。如果z和zi在潜在空间中接近,他们更有可能共享相似的答案和图像问题输入。意思是,离得近,那么图像和答案应该也相近。所以只要找到和测试的这个图片相近的那些图片,从这里面寻找答案,会比较准确。所以用余弦相似度计算距离:
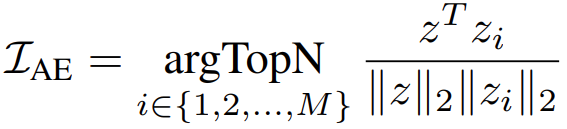
上面求出的是离得近的那些样本的index,然后从样本里面根据这些index拿出来,就得到Answer-aware examples :
![]()
三、Stage-2. Heuristics-enhanced Prompting
生成的prompt是这样的:
同时使用了多查询集成策略,即每个prompt包含N个例子,有T个这样平行的prompts。也就是得到T个答案预测。然后投票决定最终的答案。
四、实验
使用的基础VQA模型是MCAN-large,改了一下:
(i) 用从具有RN50×64骨干的CLIP视觉编码器中提取的基于网格的特征替换原始的自下而上的基于关注区域的特征;(ii)用预训练的BERT大模型代替原始LSTM网络。
在VQAv2、Visual Genome预训练,并去掉和OK-VQA重合的数据,在OK-VQA上微调。合并词汇表。

captioning 模型是OSCAR+
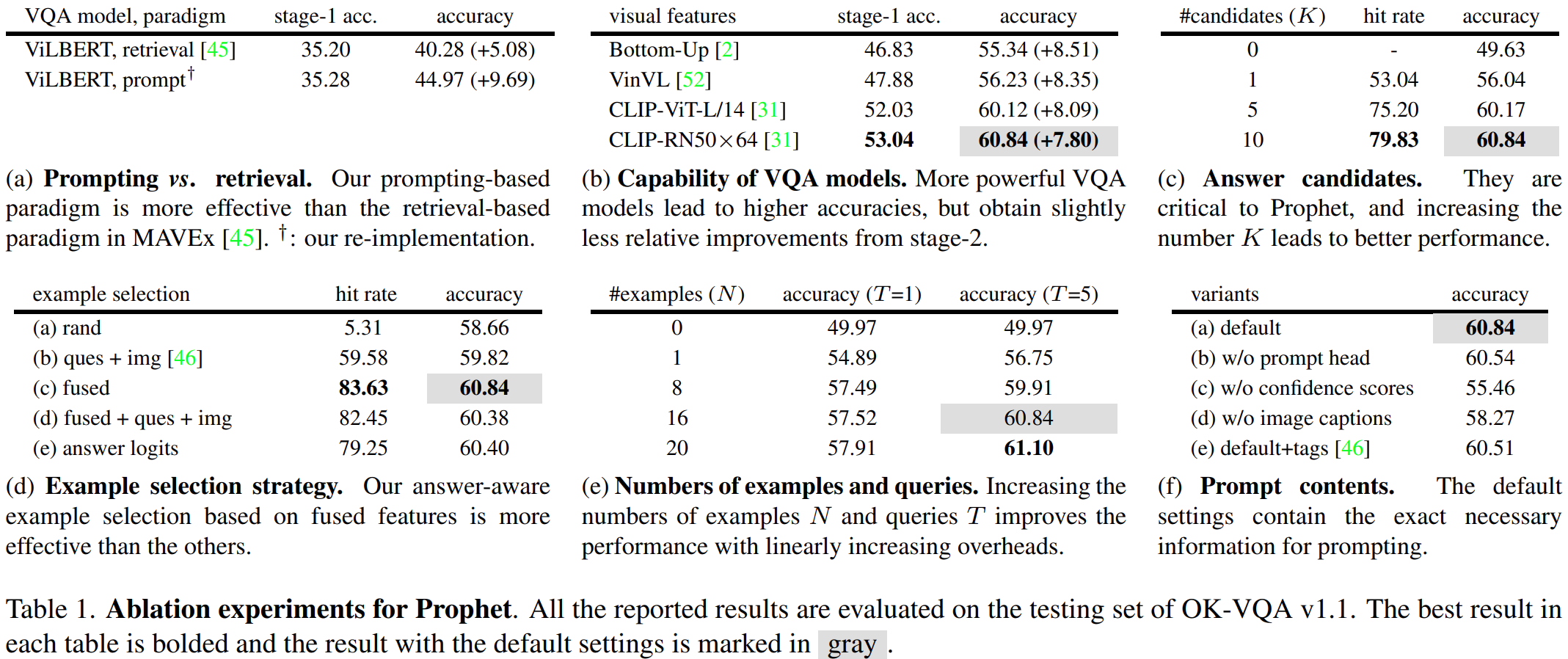
实验结果:
补充一下MCAN:论文阅读——MCAN(cvpr2019)-CSDN博客
原文地址:https://blog.csdn.net/weixin_43575791/article/details/134616461
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_1983.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






