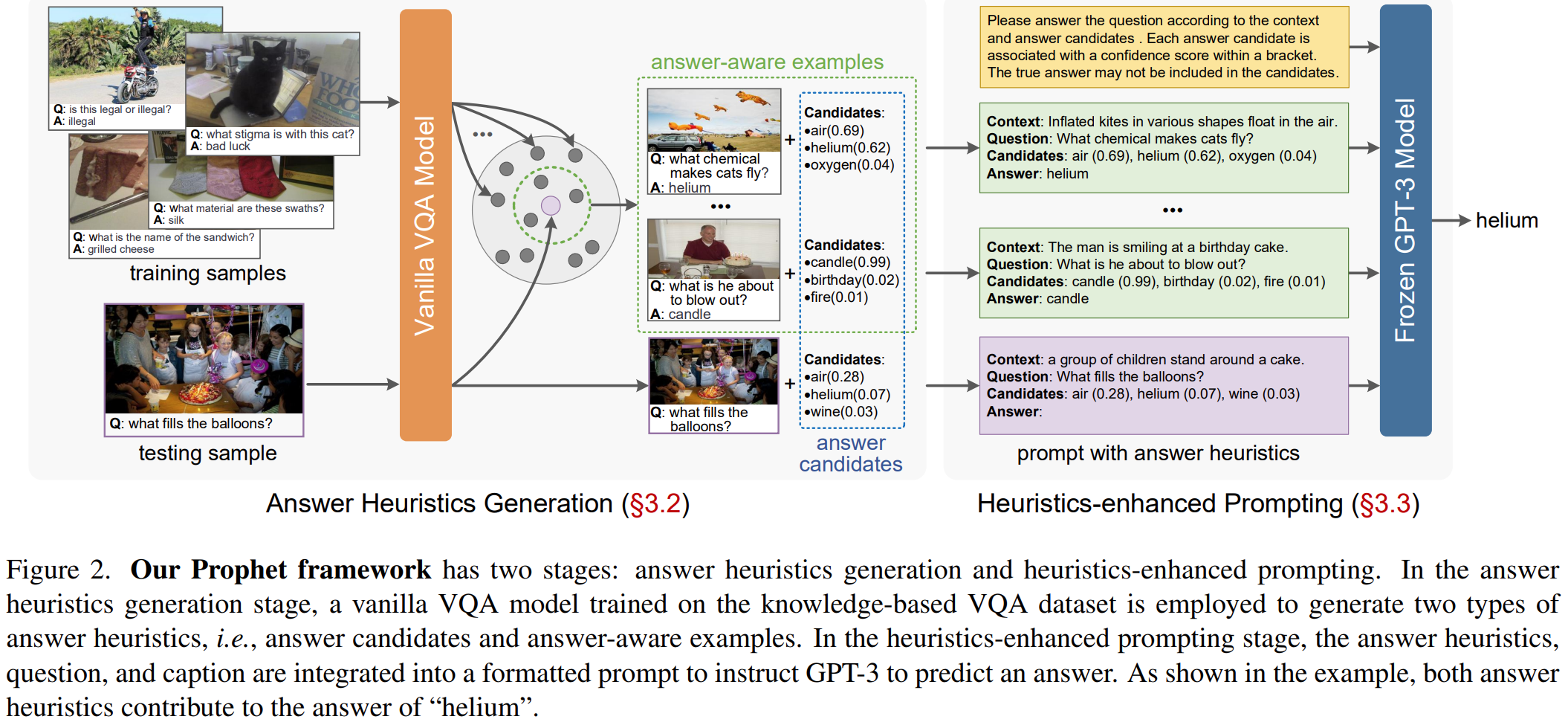
本文介绍: 这个模型分为两阶段:一是答案启发生成阶段(answer heuristics generation stage),即在一个基于知识的VQA数据集上训练一个普通的VQA模型,产生两种类型的答案启发,答案候选列表和答案例子;首先介绍VQA模型,有一个数据集D,一个答案词库W,一个VQA模型可以分为两部分,一部分是backbone Mb,一部分是分类头Mh,骨干网络用来将输入的图片和问题融合为一个特征z,分类器一般是简单的线性分类器,得到yi,表示得到得到答案wi的分数。从VQA得到的答案y里面选出前K个答案。
这个模型分为两阶段:一是答案启发生成阶段(answer heuristics generation stage),即在一个基于知识的VQA数据集上训练一个普通的VQA模型,产生两种类型的答案启发,答案候选列表和答案例子;二是启发增强提示阶段(heuristics-enhanced prompting stage),即将答案启发、问题、描述融合为一个格式化的提示prompt,引导GPT-3预测答案。
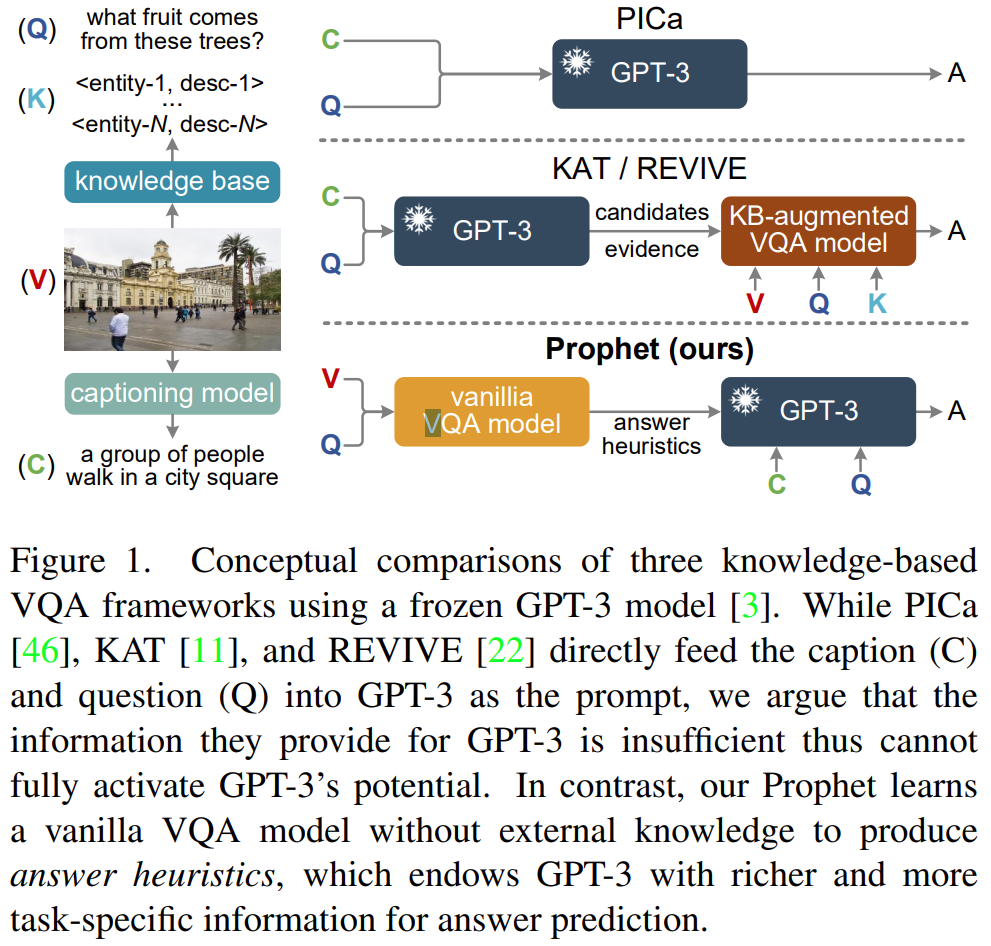
本文的方法采用了PICa这个方法的pipline。PICa方法大致如下:
![]()
具体在利用GPT-3的in-context few-shot learning能力时,输入下面这个,C是caption,对一张图片的描述,Q、A分别的问题、答案。

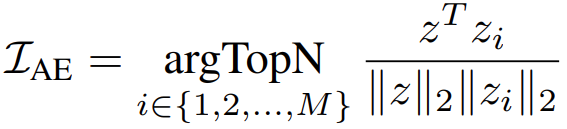

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






