day report_user_cnt report_user_cnt_2 label
2023-10-01 3 3 欺诈
2023-10-02 2 4 欺诈
2023-10-03 6 5 欺诈
2023-10-04 2 1 正常
2023-10-05 4 3 正常
2023-10-06 4 4 正常
2023-10-07 2 6 正常
2023-10-08 3 7 正常
2023-10-09 3 12 正常
2023-10-10 8 1 正常
2023-10-12 5 2 正常
2023-10-13 6 3 欺诈
2023-10-14 2 4 欺诈
2023-10-15 7 5 欺诈
2023-10-16 9 12 欺诈
2023-10-17 6 15 欺诈
2023-10-18 6 5 欺诈
2023-10-19 5 6 1
2023-10-20 3 2 1
2023-10-21 1 5 1
2023-10-22 1 5 1
2023-10-23 2 5 1
2023-10-24 3 5 1
2023-10-25 1 5 1
2023-10-26 2 5 0
2023-10-28 1 5 0
1、柱形图
plt.bar: 是 Matplotlib 库中用于绘制柱状图的函数之一,它可以接受多组数据作为输入,每组数据可以包含 x 轴和 y 轴的坐标值。
plt.bar() 函数的常用参数如下:
x:x 轴的标签,可以是一个数组、列表或者 Series 对象。
height:每个柱子的高度,可以是一个数组、列表或者 Series 对象。
width:每个柱子的宽度,可以是一个数字或者一个数组,如果是一个数组,则每个柱子的宽度可以不同。
color:柱子的颜色,可以是字符串(如 ‘red’)或者 RGB 值(如 (0.1, 0.2, 0.5))。
edgecolor:柱子边缘的颜色,可以是字符串或者 RGB 值。
linewidth:柱子边缘的宽度,可以是一个数字。
tick_label:x 轴的刻度标签,可以是一个数组、列表或者 Series 对象。
align:柱子的对齐方式,可以是 ‘center’、‘edge’ 或者 ‘tip’。
alpha:柱子的透明度,可以是一个 0 到 1 之间的数字。
代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
d = pd.read_csv('test.csv', sep = 't')
x = d['label']
num_fraud = np.sum(d['label'] == 1)
num_normal = np.sum(d['label'] == 0)
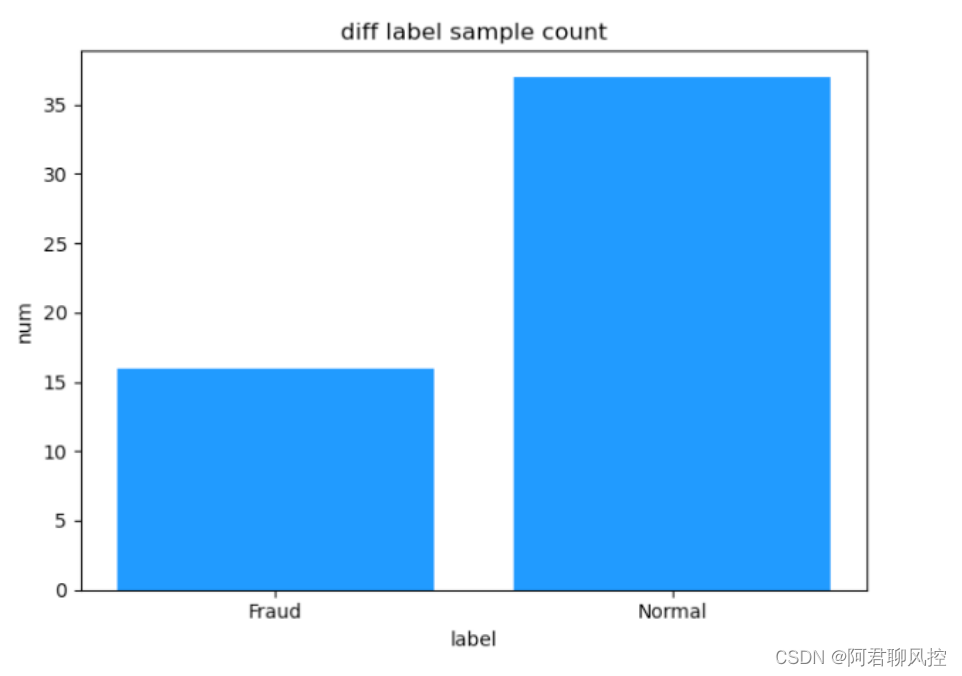
plt.bar(['Fraud', 'Normal'], [num_fraud, num_normal], color='dodgerblue')
plt.ylabel('num')
plt.xlabel('label')
plt.title('diff label sample count')
plt.show()
2、折线图
plt.plot 包含的参数有哪些?
x: x 轴坐标值,可以是一个数组、列表或者 Series 对象。
y : y 轴坐标值,可以是一个数组、列表或者 Series 对象。
color: 折线的颜色,可以是字符串(如 ‘red’)或者 RGB 值(如 (0.1, 0.2, 0.5))。
linestyle: 折线的样式,可以是字符串(如 ‘–’)或者一个包含实线、虚线等样式的元组。
linewidth: 折线的宽度,可以是一个数字。
marker: 数据点的标记样式,可以是字符串(如 ‘o’)或者一个包含圆形、正方形等样式的元组。
markersize: 数据点的大小,可以是一个数字。
label: 折线的标签,用于图例中显示。
alpha : 折线的透明度,可以是一个 0 到 1 之间的数字。
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
d = pd.read_csv('test.csv', sep = 't')
x = d['day']
y = d['report_user_cnt']
plt.figure(figsize=(14, 5))
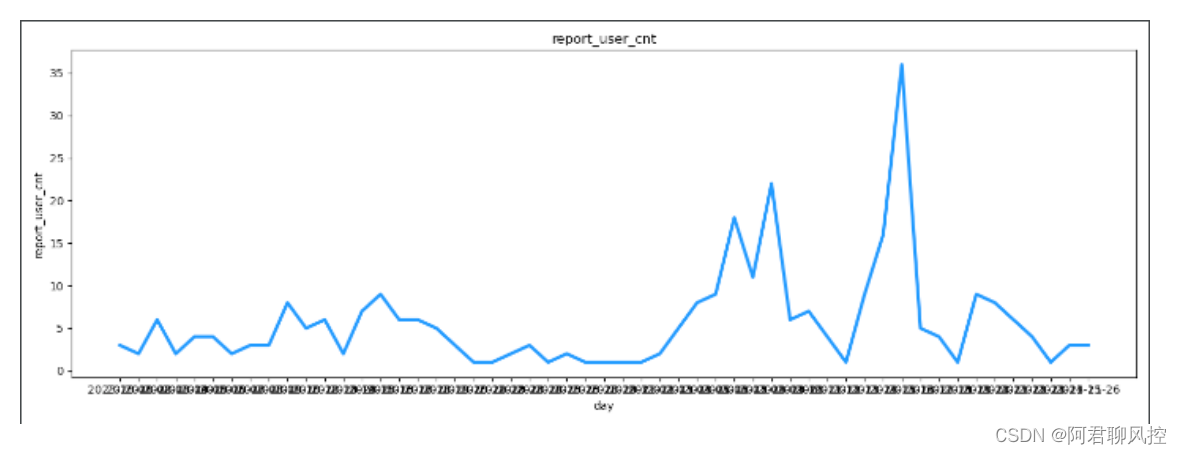
plt.plot(x, y, c='dodgerblue', lw=3)
plt.title('report_user_cnt')
plt.ylabel('report_user_cnt')
plt.xlabel('day')
plt.show()
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
d = pd.read_csv('test.csv', sep = 't')
x = d['day']
y1 = d['report_user_cnt']
y2 = d['report_user_cnt_2']
plt.figure(figsize=(14, 5))
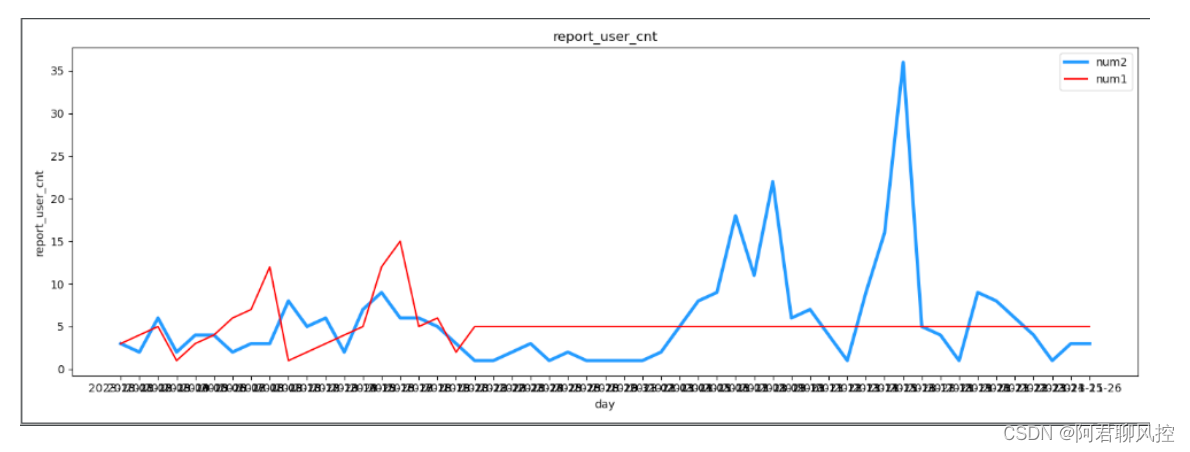
plt.plot(x, y1, c='dodgerblue', lw=3, label = "num2")
plt.plot(x, y2, c='red', label = "num1")
plt.title('report_user_cnt')
plt.ylabel('report_user_cnt')
plt.xlabel('day')
plt.legend()
plt.show()
3)散点图
plt.scatter是绘制散点图
x : x坐标
y : y坐标
s : 散点的大小
c : 点的颜色
marker :点的标记形状
alpha:散点的透明度
label : 散点图的标签
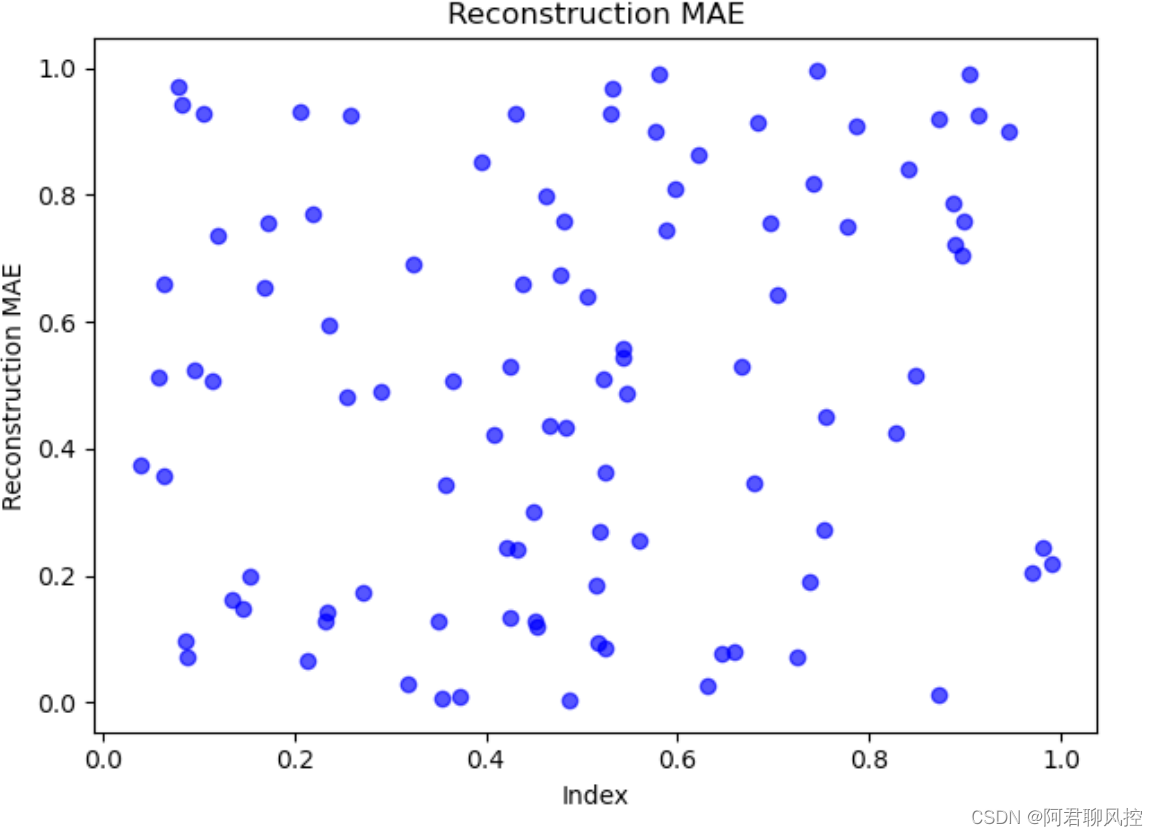
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.scatter(np.random.rand(100), # 随机产生0-1之间的100个随机数
np.random.rand(100),
alpha=0.7,
marker= 'o',
c= 'b',
label= 'mae')
plt.title('Reconstruction MAE')
plt.ylabel('Reconstruction MAE')
plt.xlabel('Index')
plt.show()
4)创建子图
plt.subplot()是Matplotlib库中用于创建子图的函数,
它的参数有三个,分别是
plt.subplot(nrows, ncols, index)。
其中,nrows和ncols表示子图网格的行数和列数,
index表示当前子图的位置。
比如plt.subplot(221)表示将当前子图设置为一个2行2列的网格中的第1个子图。
如果nrows和ncols的值都小于10,则可以将它们组合成一个两位数的整数,比如plt.subplot(221)表示将当前子图设置为一个2行2列的网格中的第1个子图。
如果nrows和ncols的值大于等于10,则需要使用三位数的整数来表示子图位置,比如plt.subplot(2, 2, 1)表示将当前子图设置为一个2行2列的网格中的第1个子图。
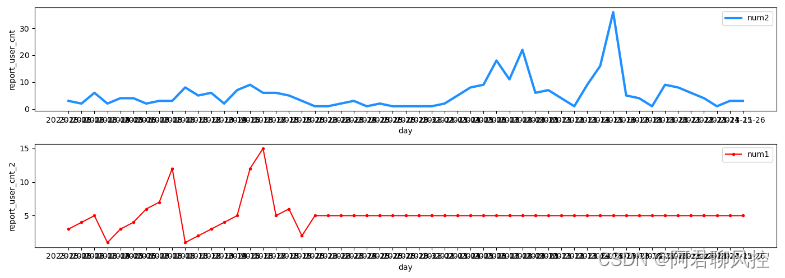
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
d = pd.read_csv('test.csv', sep ='t')
x = d['day']
y1 = d['report_user_cnt']
y2 = d['report_user_cnt_2']
plt.figure(figsize=(14, 5))
plt.subplot(211)
plt.plot(x, y1, c='dodgerblue', linestyle='-', lw=3, label = "num2")
plt.ylabel('report_user_cnt')
plt.xlabel('day')
plt.legend()
plt.subplot(212)
plt.plot(x, y2, c='red',marker='.', label = "num1")
plt.ylabel('report_user_cnt_2')
plt.xlabel('day')
plt.legend()
plt.show()
5) python的高级绘图plotly.express
1、绘制直方图
plotly.express库是一个基于plotly库的高级API,它可以让用户轻松地创建各种数据可视化图表,包括散点图、直方图、热力图、等高线图等。通过简单的函数调用,用户可以快速地生成各种图表,并进行自定义设置。此外,plotly.express还支持各种交互式功能,比如缩放、平移、旋转、悬停等,可以让用户更加方便地探索和分析数据。
import plotly.express as px
df['anomaly'] = df['label'].apply(lambda x: 'outlier' if x==-1 else 'inlier')
# px.histogram()函数创建直方图,统计每个分数对应的样本个数
fig = px.histogram(df,x='scores',color='anomaly')
fig.show()
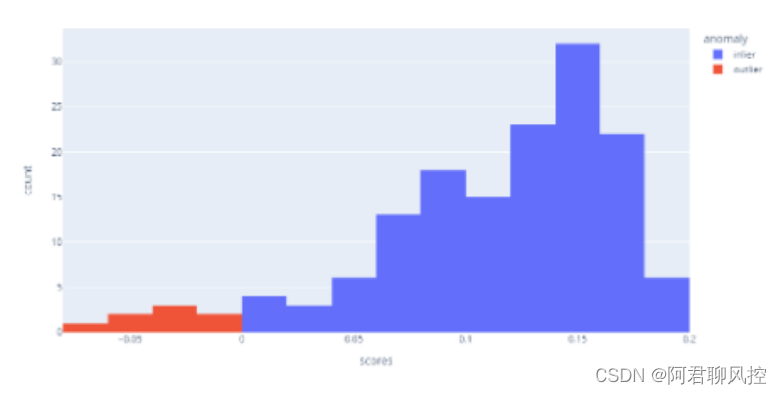
histogram可以根据标签列表,分组后统计每个标签的个数,十分方便
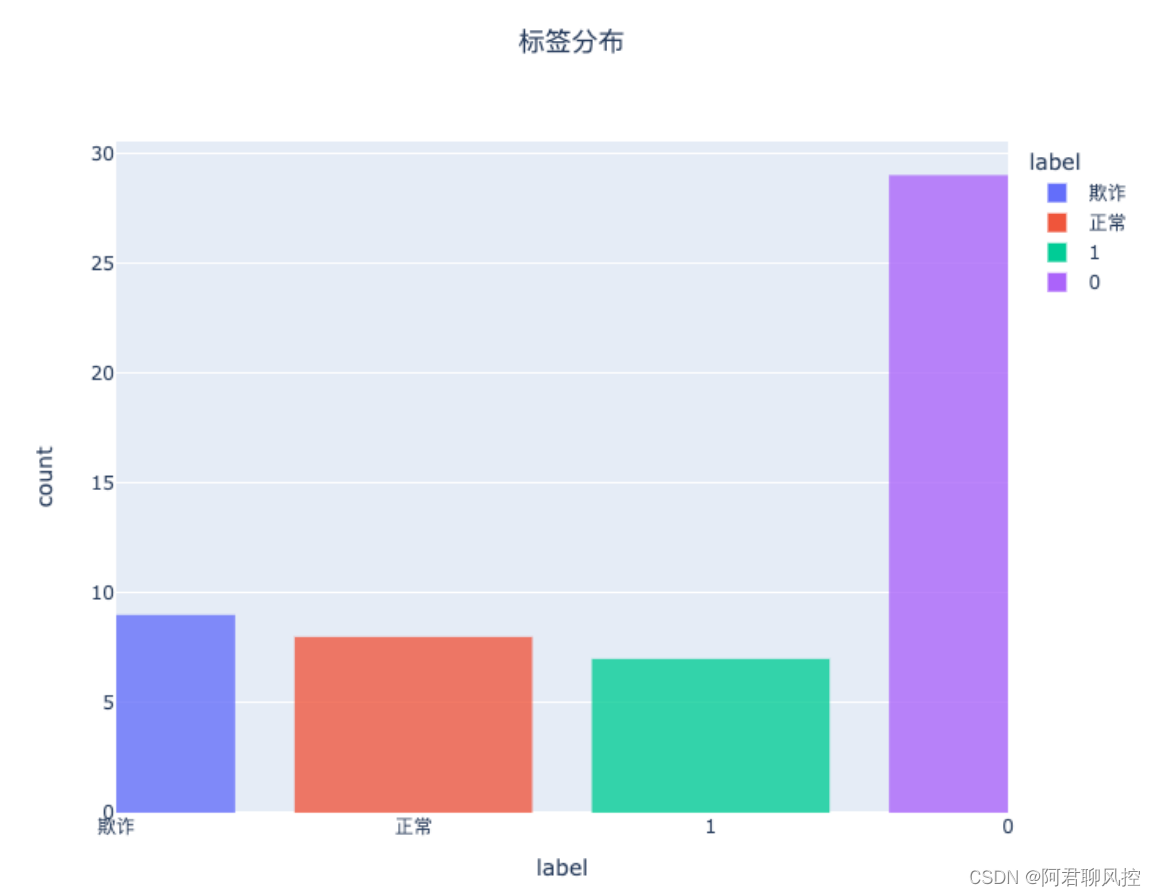
import plotly.express as px
import pandas as pd
df = pd.read_csv('test.csv', sep ='t')
# px.histogram()函数创建直方图
fig = px.histogram(df,x='label',color='label', range_x = [0,3], opacity = 0.8, title = "标签分布")
fig.update_layout(
title={
'text': "标签分布",
'y':0.95,
'x':0.5,
'xanchor': 'center',
'yanchor': 'top'})
fig.show()
px.histogram()是Plotly Express中的直方图函数,用于绘制一维数据的分布情况。它的常用参数如下:
data_frame: 数据框,包含要绘制的数据。
x: 要绘制的数据列名或者数据列表。
nbins: 直方图的箱子数量,可以是整数或者字符串(如“sturges”、“fd”、“sqrt”等)。
range_x: 要绘制的数据的范围,可以是一个元组或列表,如(0, 10)。
color: 按照某个列对数据进行分组,每组用不同的颜色绘制。
opacity: 直方图的透明度,取值范围为0-1。
barmode: 直方图的模式,可以是“overlay”(默认)、“stack”或“group”。
title: 直方图的标题。
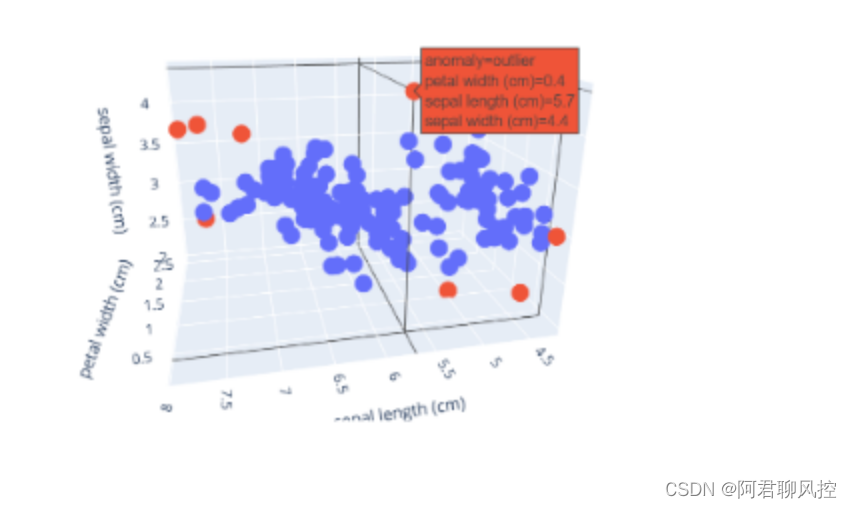
2、创建一个3D散点图
import plotly.express as px
import pandas as pd
df = pd.read_csv('test.csv', sep ='t')
fig = px.scatter_3d(df,x='petal width (cm)',
y='sepal length (cm)',
z='sepal width (cm)',
color='anomaly')
fig.show()
原文地址:https://blog.csdn.net/u010569893/article/details/134739859
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_20822.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!