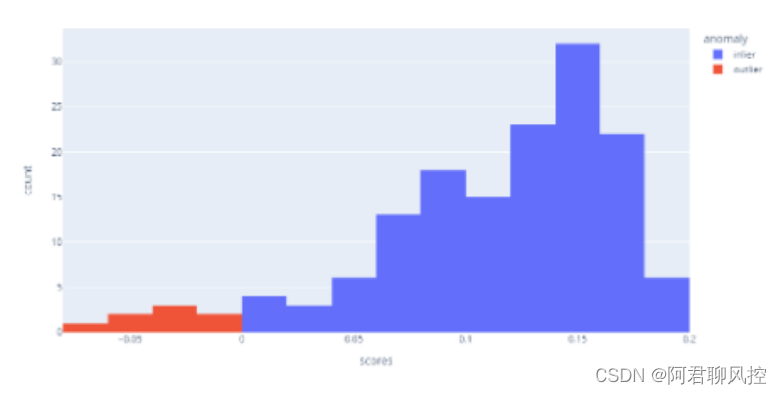
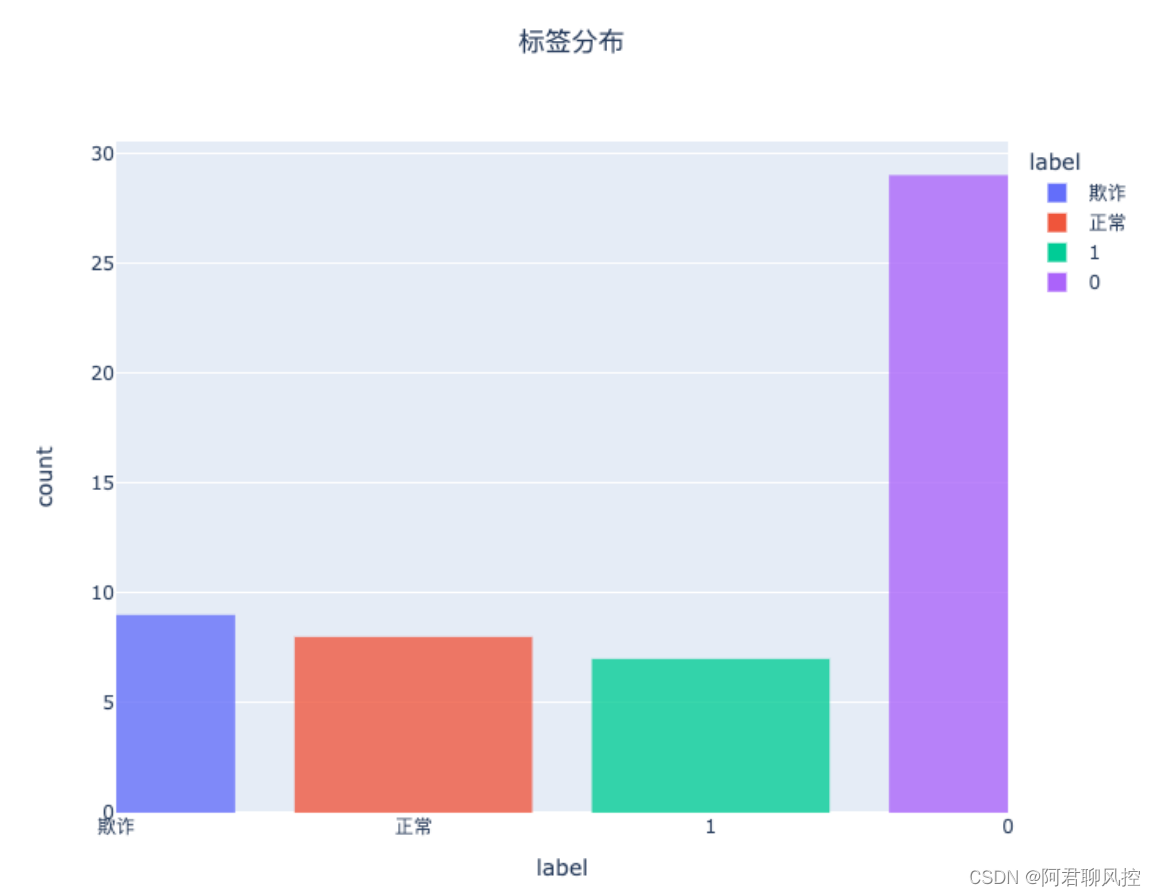
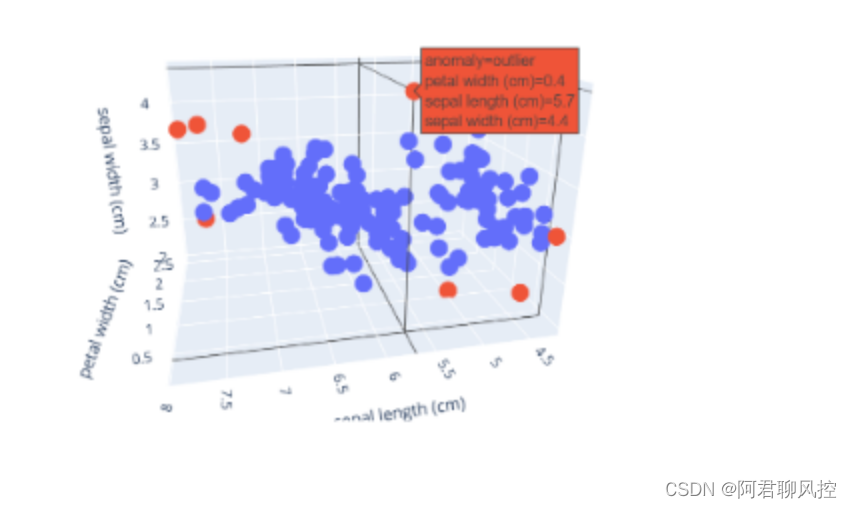
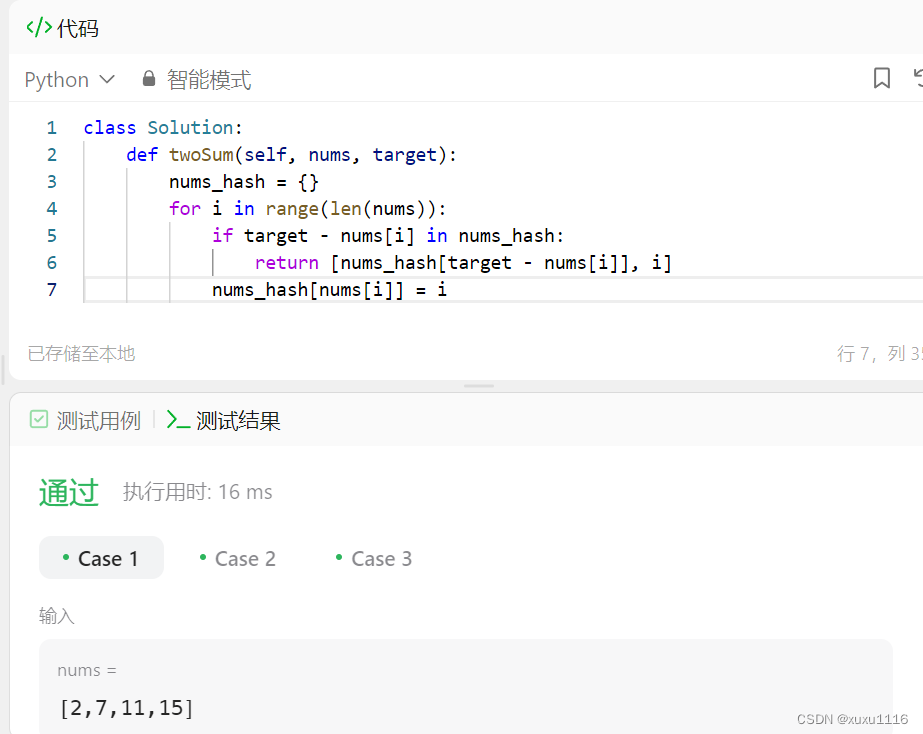
1、柱形图
plt.bar: 是 Matplotlib 库中用于绘制柱状图的函数之一,它可以接受多组数据作为输入,每组数据可以包含 x 轴和 y 轴的坐标值。
plt.bar() 函数的常用参数如下:
x:x 轴的标签,可以是一个数组、列表或者 Series 对象。
height:每个柱子的高度,可以是一个数组、列表或者 Series 对象。
width:每个柱子的宽度,可以是一个数字或者一个数组,如果是一个数组,则每个柱子的宽度可以不同。
color:柱子的颜色,可以是字符串(如 ‘red’)或者 RGB 值(如 (0.1, 0.2, 0.5))。
edgecolor:柱子边缘的颜色,可以是字符串或者 RGB 值。
linewidth:柱子边缘的宽度,可以是一个数字。
tick_label:x 轴的刻度标签,可以是一个数组、列表或者 Series 对象。
align:柱子的对齐方式,可以是 ‘center’、‘edge’ 或者 ‘tip’。
alpha:柱子的透明度,可以是一个 0 到 1 之间的数字。
代码:
2、折线图
plt.plot 包含的参数有哪些?
x: x 轴坐标值,可以是一个数组、列表或者 Series 对象。
y : y 轴坐标值,可以是一个数组、列表或者 Series 对象。
color: 折线的颜色,可以是字符串(如 ‘red’)或者 RGB 值(如 (0.1, 0.2, 0.5))。
linestyle: 折线的样式,可以是字符串(如 ‘–’)或者一个包含实线、虚线等样式的元组。
linewidth: 折线的宽度,可以是一个数字。
marker: 数据点的标记样式,可以是字符串(如 ‘o’)或者一个包含圆形、正方形等样式的元组。
markersize: 数据点的大小,可以是一个数字。
label: 折线的标签,用于图例中显示。
alpha : 折线的透明度,可以是一个 0 到 1 之间的数字。