大纲
1 数据采集准备工作
1.1 研究的背景
1.2 使用Glue构建流式ETL的原因
AWS Glue中的流式ETL是基于Apache Spark的结构化流引擎。该引擎提供一种高容错、可扩展且易于实现的方法,能够实现端到端的流处理。
1.3 无服务器流式ETL架构
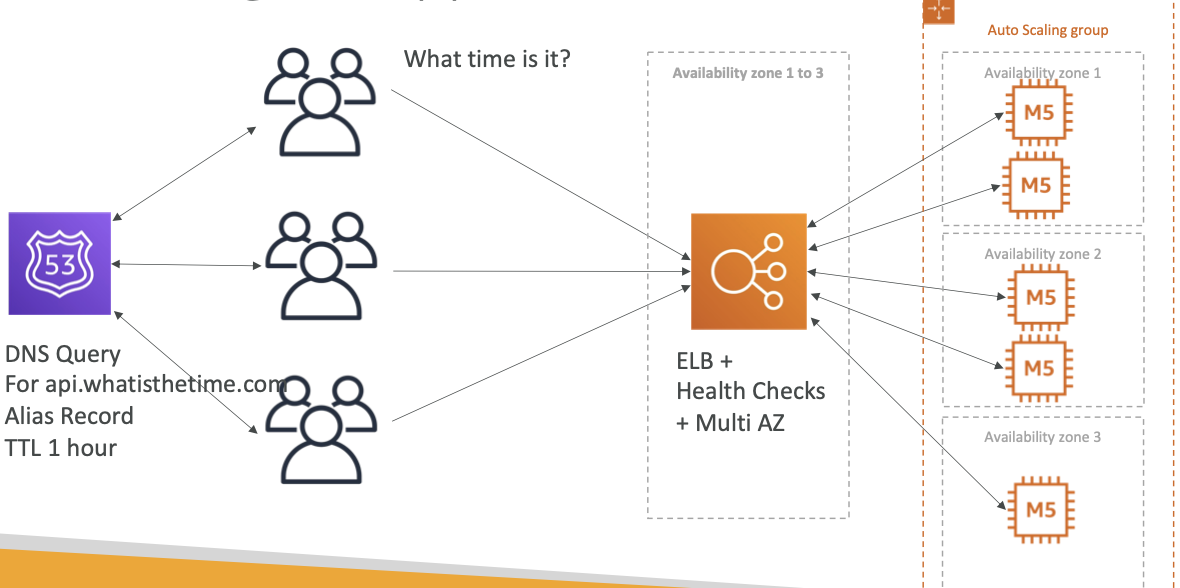
在此流式ETL架构中,将使用AWS Lambda模拟创建日志和创建AWS CloudWatch指标,并将其以流的形式发布至AWS Kinesis Data Streams中。我们还将在AWS Glue中创建一项流式ETL作业,该作业以微批次(间隔性批次处理)的形式获取连续生成的stream数据,并对数据进行转换、聚合,最后将结果传递至接收器。开发人员利用这部分结果生成可视化图表或在下游流程中继续使用。
1.4 架构

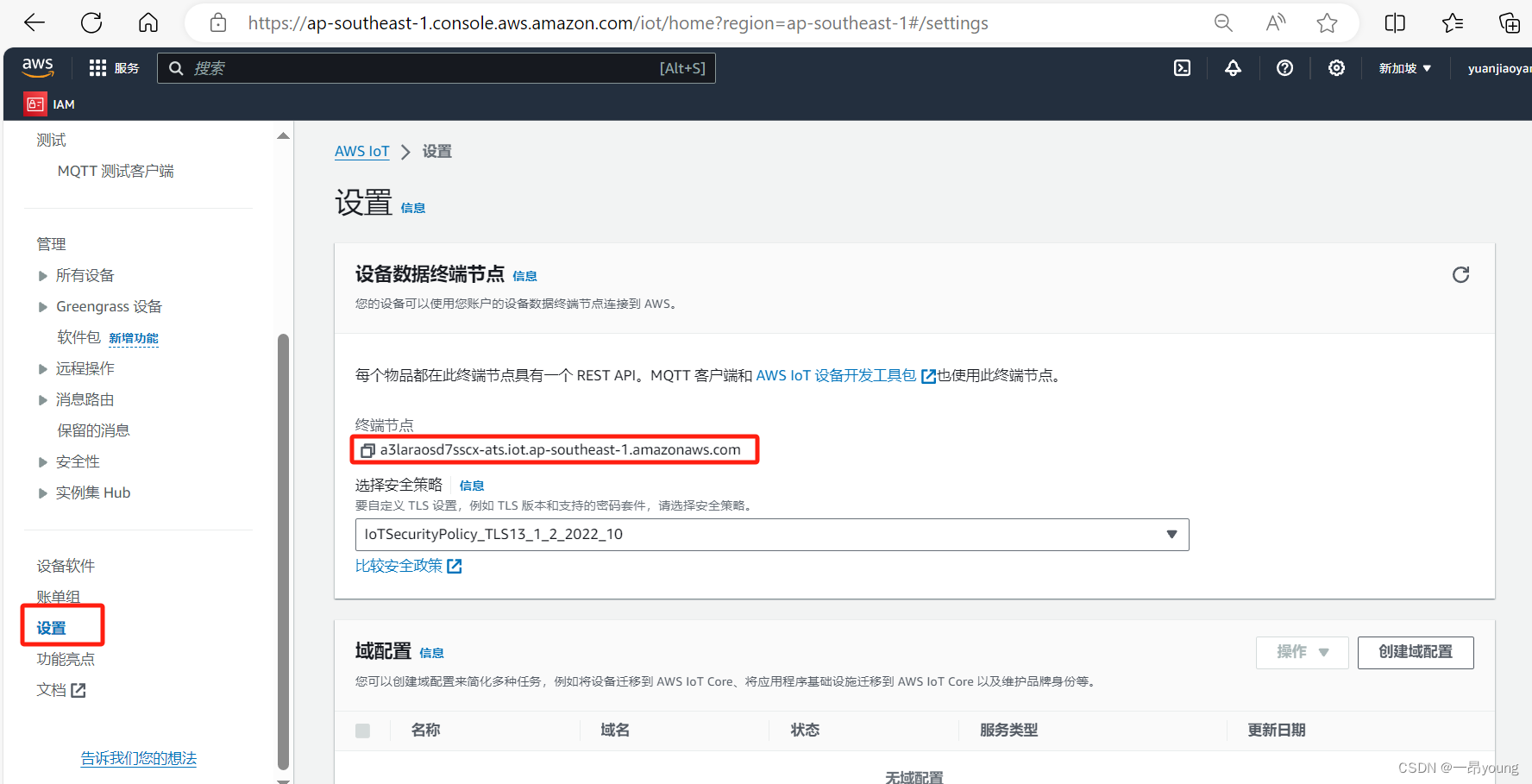
1.5 AWS Kinesis Data Stream创建
我们使用AWS Kinesis Data Stream来实时捕获数据,它可以从数十万个数据源提取并存储数据流,其中包括:
| 步骤 | 图例 |
|---|---|
| 1、入口 | 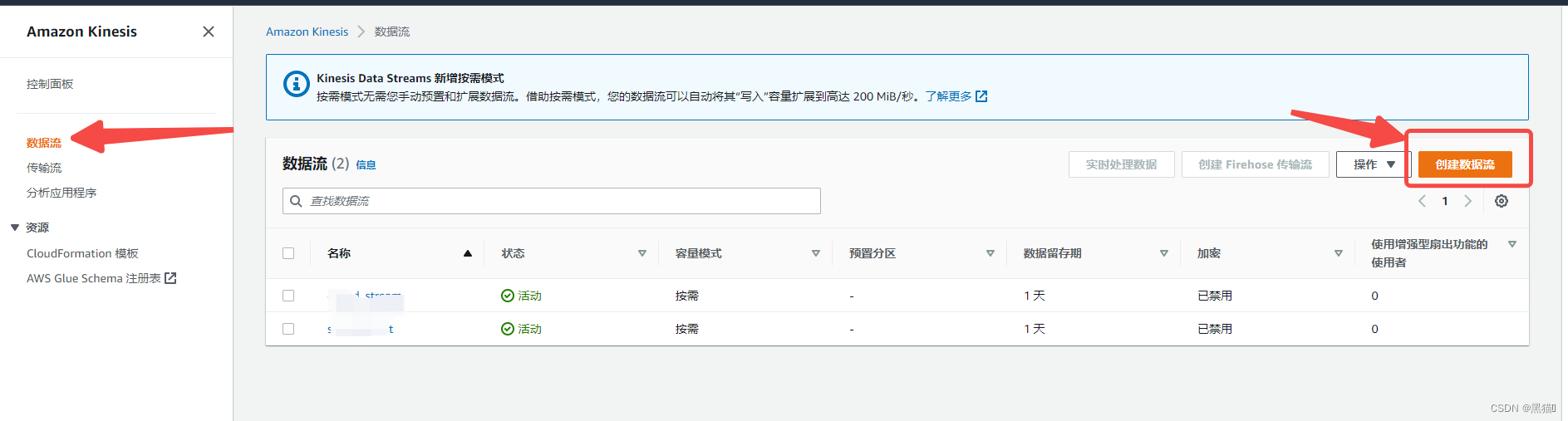 |
| 2、创建(按需模式无需手动预置和扩展数据流) |  |
1.6 AWS CloudWatch数据筛选
前置条件:已准备好用来进行数据采集的AWS CloudWatch
我们将会在某个AWS CloudWatch日志组中创建日志筛选条件
| 步骤 | 图例 |
|---|---|
| 1、入口 | 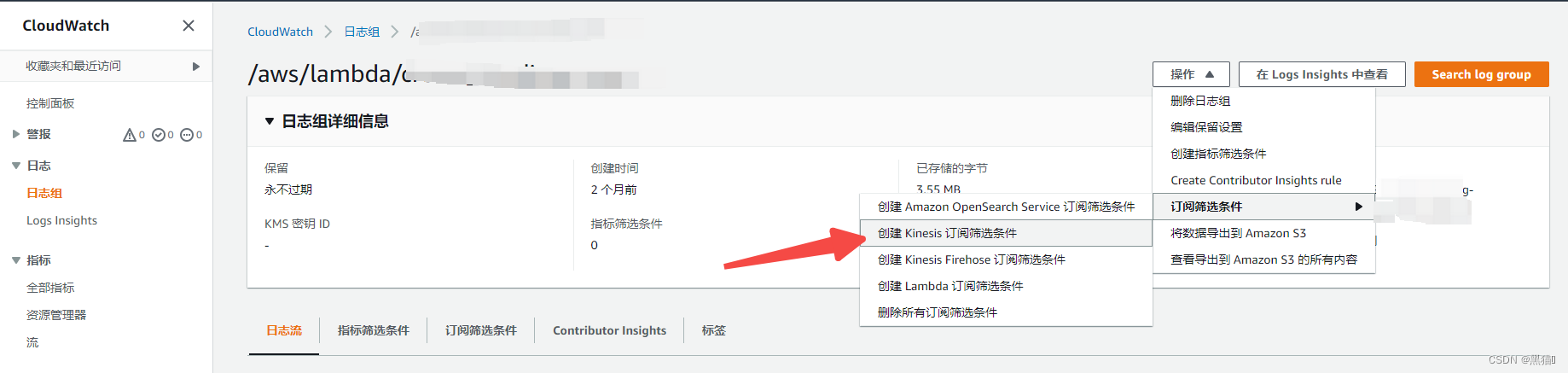 |
| 2、选择上步中创建的AWS Kinesis | 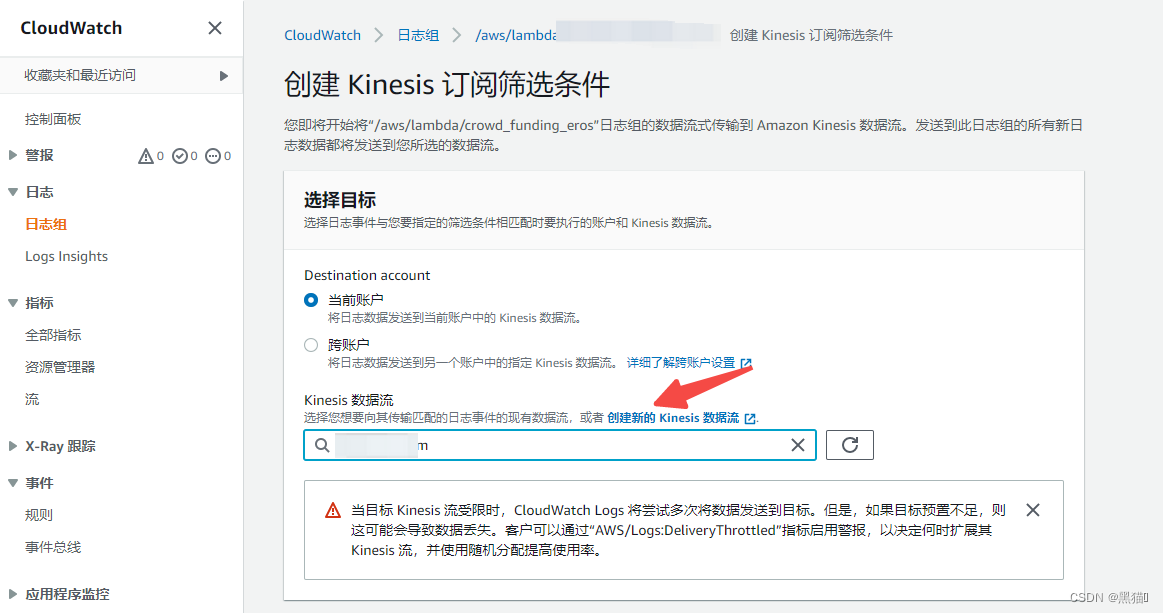 |
| 3、AWS IAM角色(需要有AWS Kinesis Data Stream的权限) | 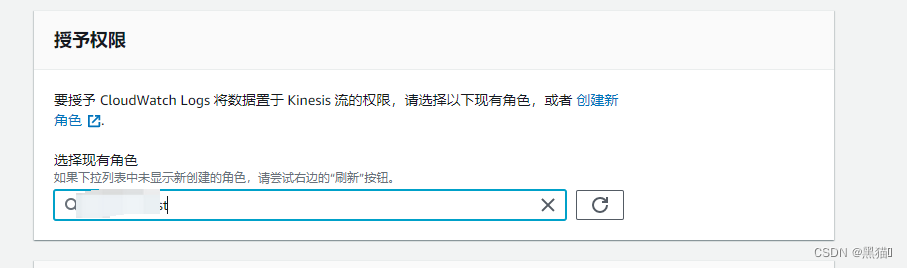 权限与实体见下方“AWS IAM角色权限” 权限与实体见下方“AWS IAM角色权限” |
| 4、配置筛选条件(可根据日志格式自定义)(例如:图中配置为筛选包含“is_save_kinesis“的数据) | 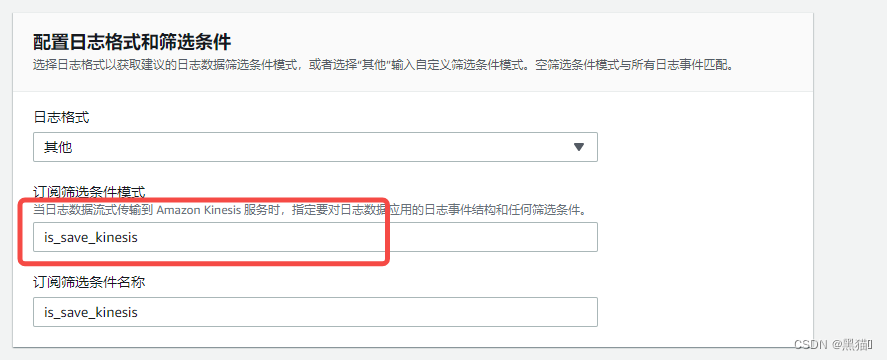 |
| 5、测试数据(可以选定某条日志流,或自定义数据进行测试结果显示) | 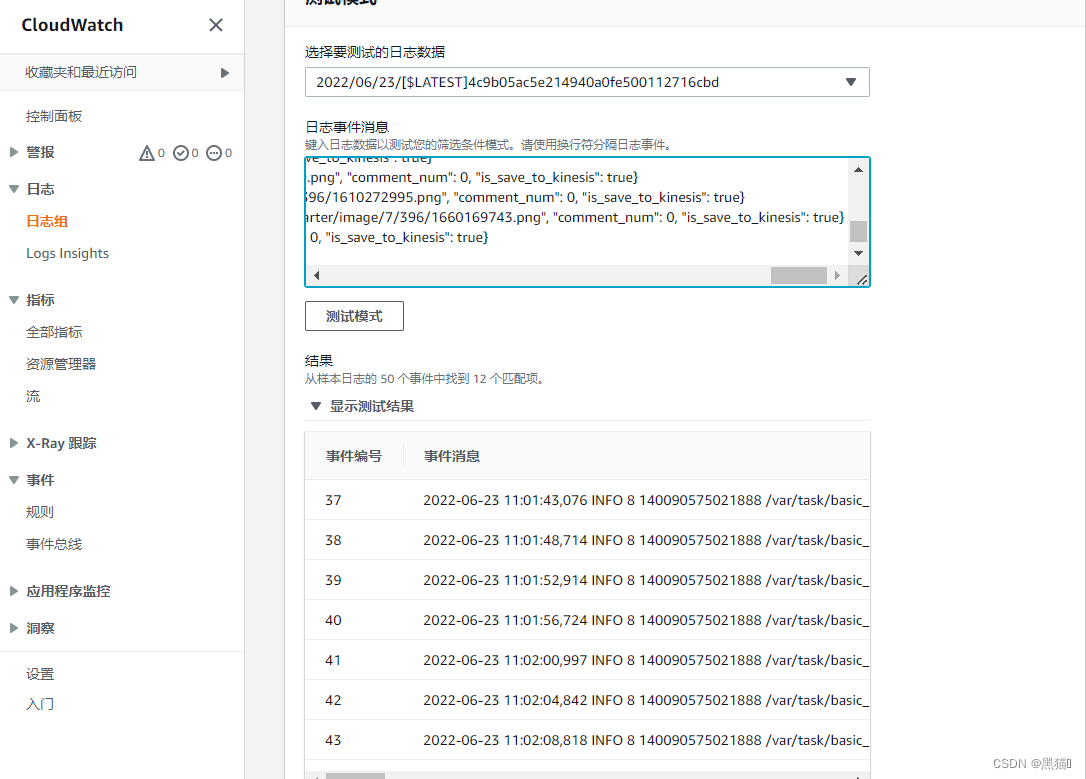 |
| 6、完成日志筛选条件创建(每个日志组最多只能创建两条) |  |
1.6.1 AWS IAM角色权限
1.6.1.1 可信实体
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "logs.【区域】.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringLike": {
"aws:SourceArn": "【CloudWatch的ARN】"
}
}
}
]
}
1.6.1.2 策略
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "WriteOutputKinesis",
"Effect": "Allow",
"Action": [
"kinesis:DescribeStream",
"kinesis:PutRecord",
"kinesis:PutRecords"
],
"Resource": [
"【Kinesis Data Stream的ARN】"
]
}
]
}
1.7 AWS Kinesis中的数据验证
前置条件:一个已绑定上 以AWS Kinesis作为触发器的AWS Lambda实例。
此案例也可使用AWS Lambda来实现数据流的处理。每当AWS Kinesis Data Stream中传入数据时,就会触发绑定了Kinesis的AWS Lambda,由AWS Lambda来对数据进行清洗、转换和存储。
在我们向被监测的AWS CloudWatch中发送一条日志数据后,将会在AWS Kinesis Data Stream控制台监控到数据的流入。
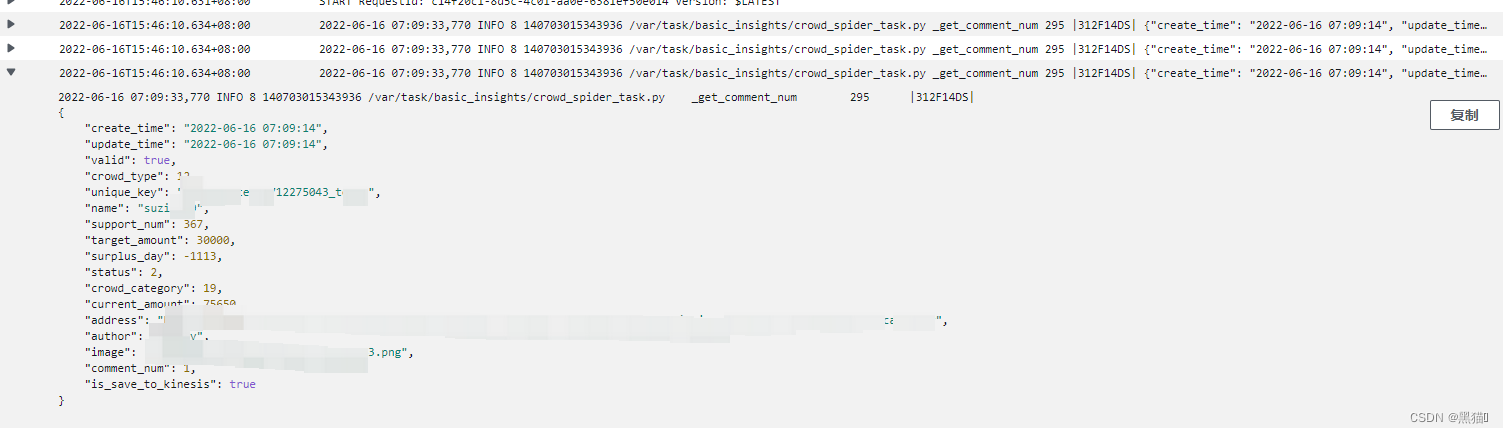
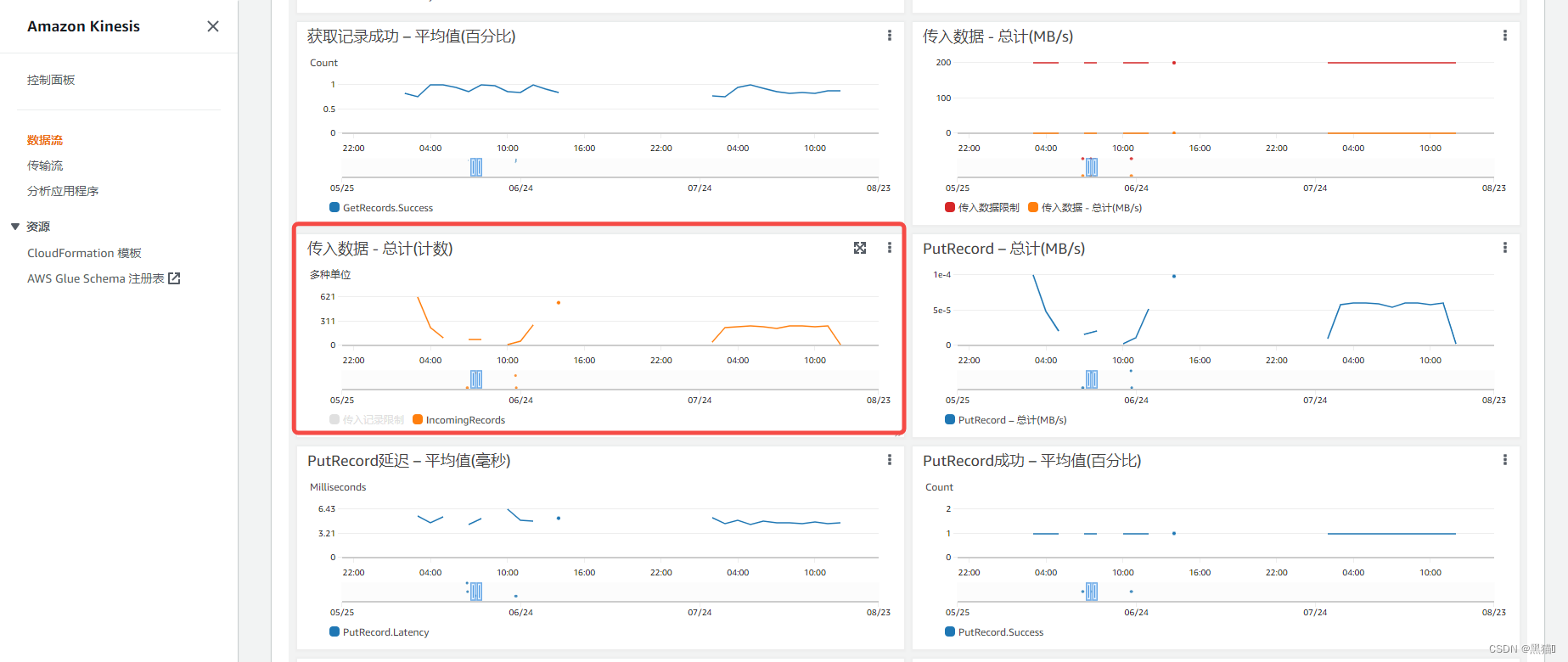
接下来,我们将会验证解析一下Kinesis Data Stream中的数据与格式。
原始数据存储在event.Records[0].kinesis.data中(下一步的ETL工作中,我们会从此处获取数据)
1.7.1 验证代码
def lambda_handler(event, context):
raw_kinesis_records = event['Records']
# records = deaggregate_records(raw_kinesis_records)
records = raw_kinesis_records
for record in records:
#Kinesis data is base64 encoded so decode here
payload = base64.b64decode(record["kinesis"]["data"], validate = False)
data = gzip.decompress(payload).decode("utf-8")
print(data)
1.7.2 结果
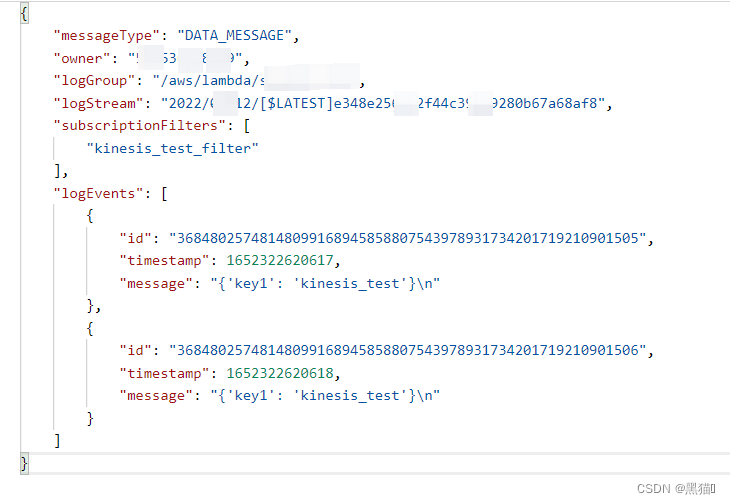
1.8 总结
在此案例中,我们使用了CloudWatch + Kinesis Data Stream完成了前期的数据实时采集的工作,并且,使用了Lambda来作为触发器来对数据进行了一个验证操作(也可使用Lambda来进行ETL工作)。
原文地址:https://blog.csdn.net/wujiesunlirong/article/details/134803575
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_47594.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!