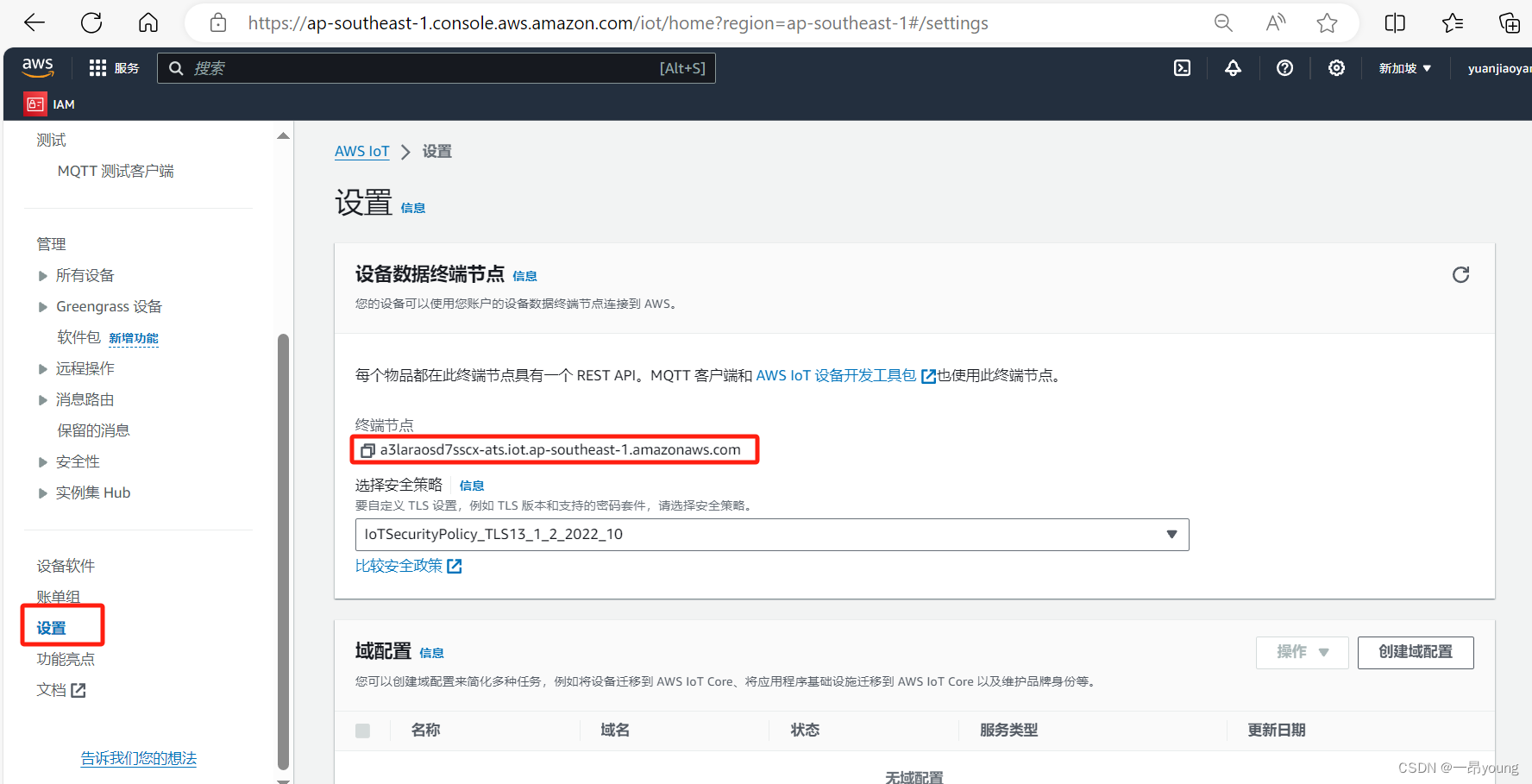
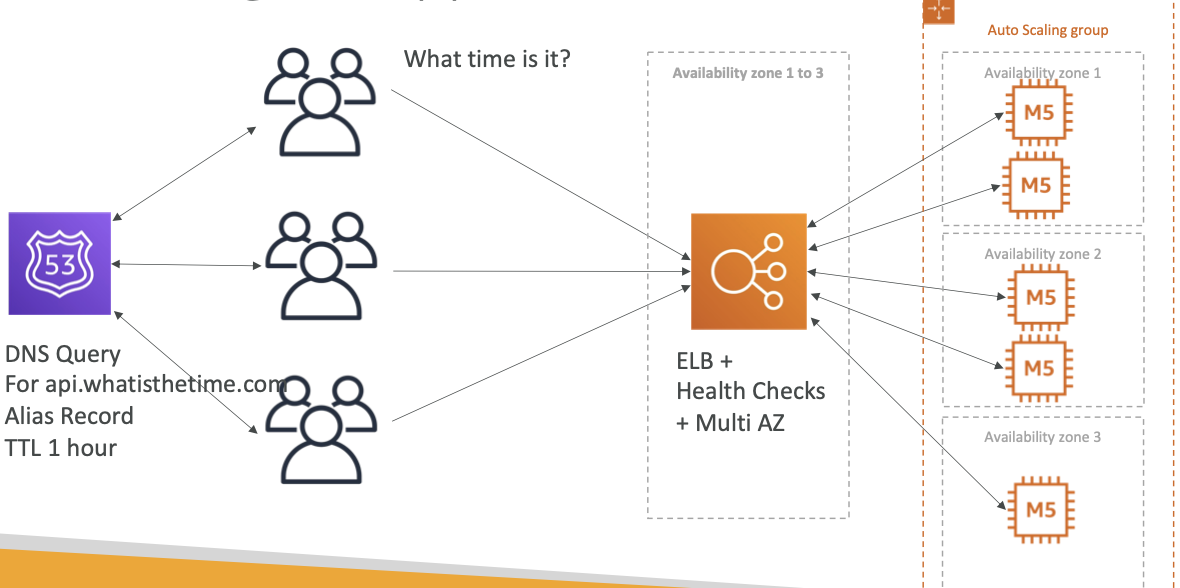
本文介绍: 在此案例中,我们使用了CloudWatch + Kinesis Data Stream完成了前期的数据实时采集的工作,并且,使用了Lambda来作为触发器来对数据进行了一个验证操作(也可使用Lambda来进行ETL工作)。
1 数据采集准备工作
1.1 研究的背景
1.2 使用Glue构建流式ETL的原因
AWS Glue中的流式ETL是基于Apache Spark的结构化流引擎。该引擎提供一种高容错、可扩展且易于实现的方法,能够实现端到端的流处理。
1.3 无服务器流式ETL架构
在此流式ETL架构中,将使用AWS Lambda模拟创建日志和创建AWS CloudWatch指标,并将其以流的形式发布至AWS Kinesis Data Streams中。我们还将在AWS Glue中创建一项流式ETL作业,该作业以微批次(间隔性批次处理)的形式获取连续生成的stream数据,并对数据进行转换、聚合,最后将结果传递至接收器。开发人员利用这部分结果生成可视化图表或在下游流程中继续使用。
1.4 架构

1.5 AWS Kinesis Data Stream创建
我们使用AWS Kinesis Data Stream来实时捕获数据,它可以从数十万个数据源提取并存储数据流,其中包括:
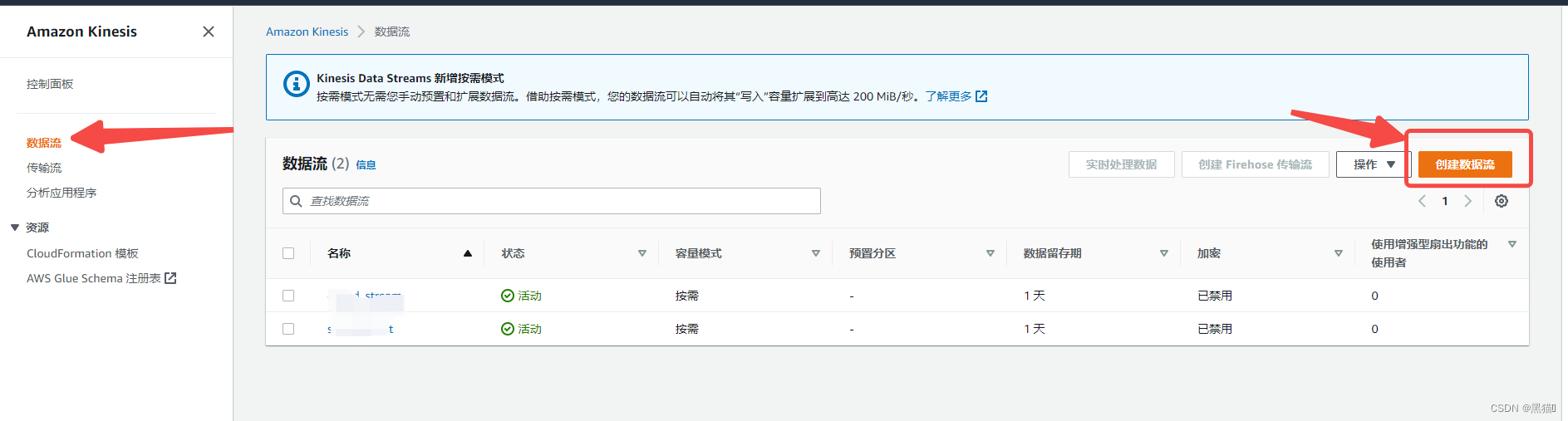

1.6 AWS CloudWatch数据筛选
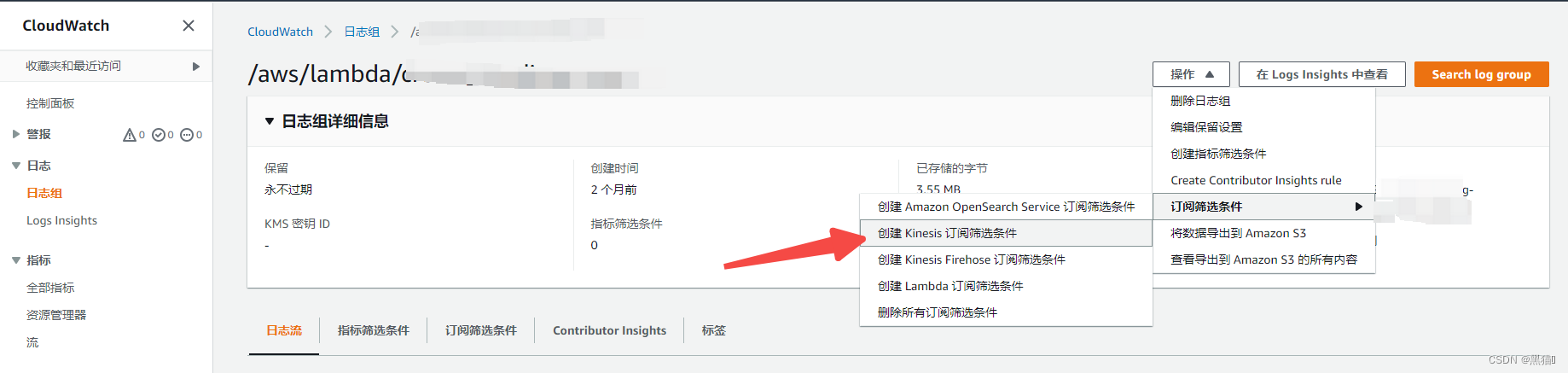
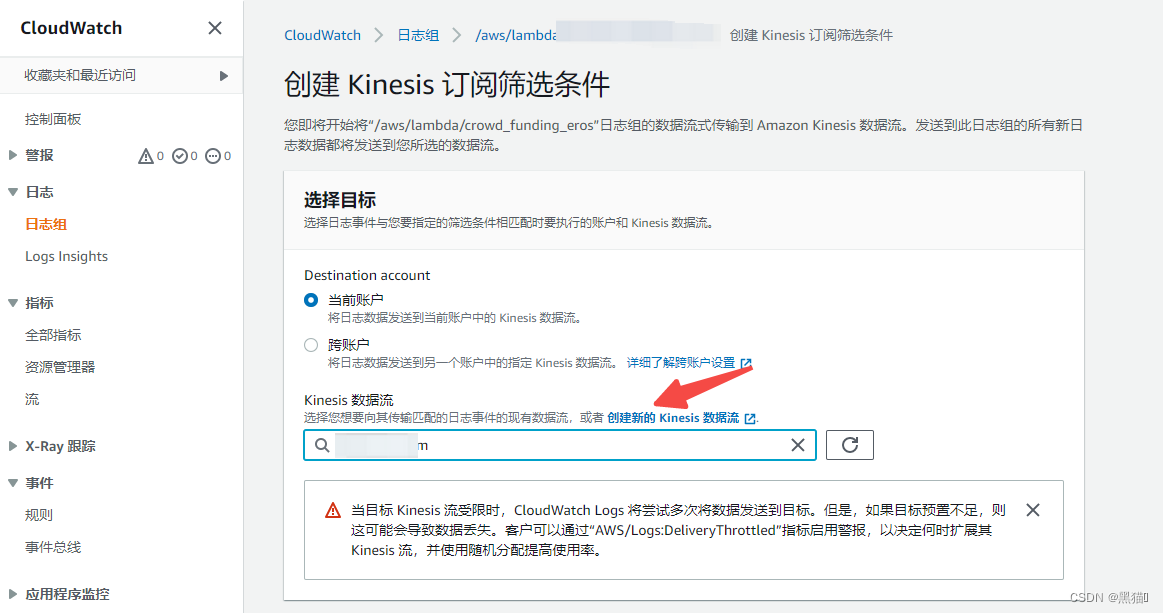
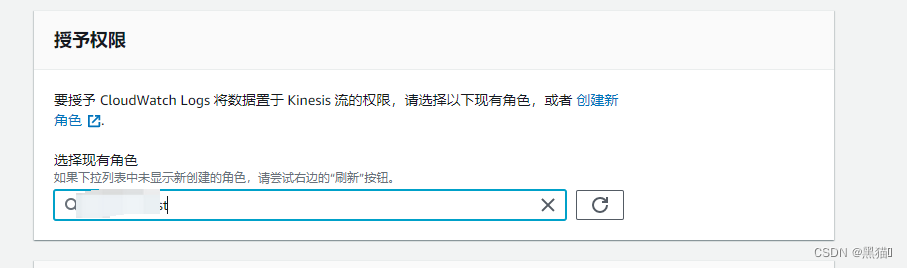
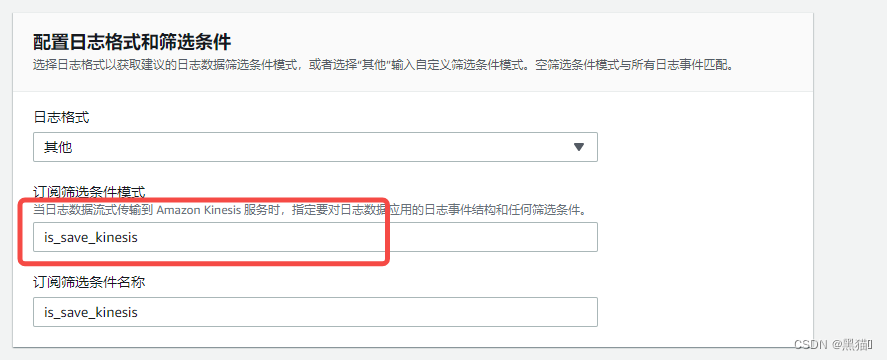

1.6.1 AWS IAM角色权限
1.6.1.1 可信实体
1.6.1.2 策略
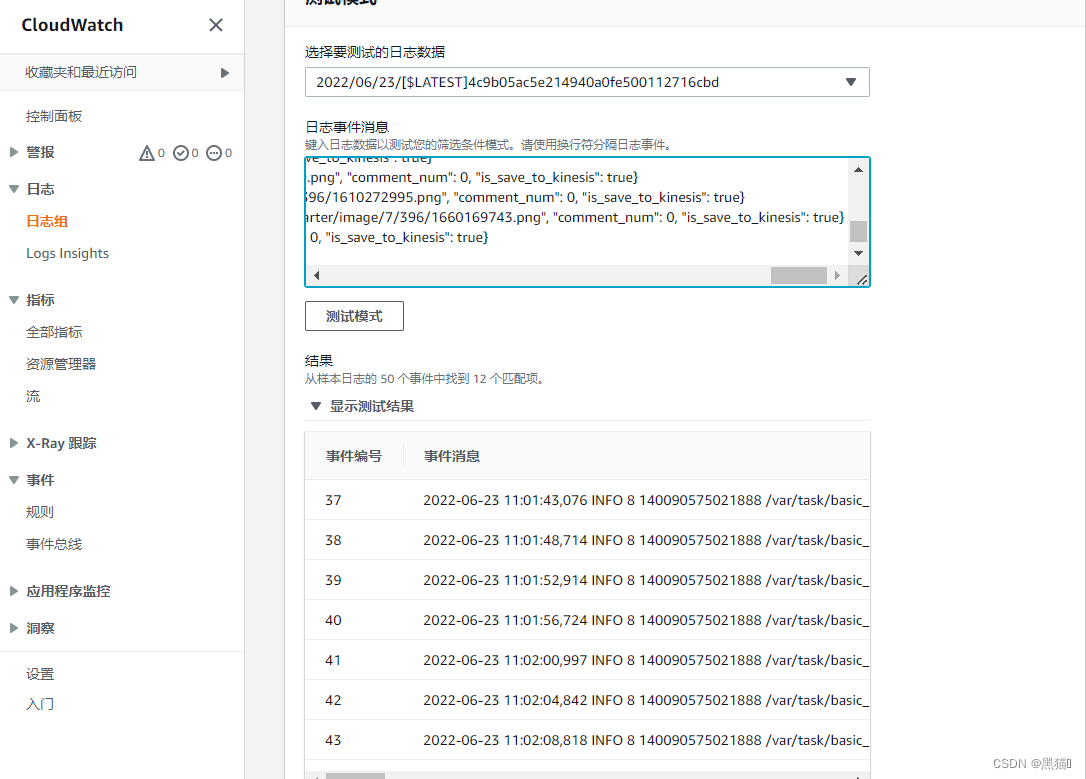
1.7 AWS Kinesis中的数据验证
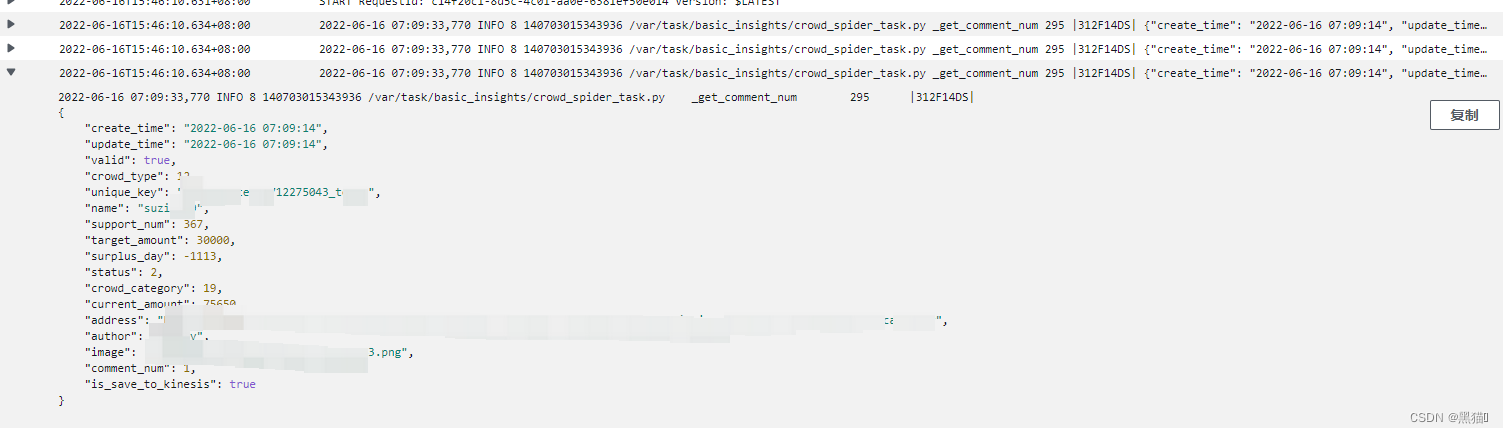
1.7.1 验证代码
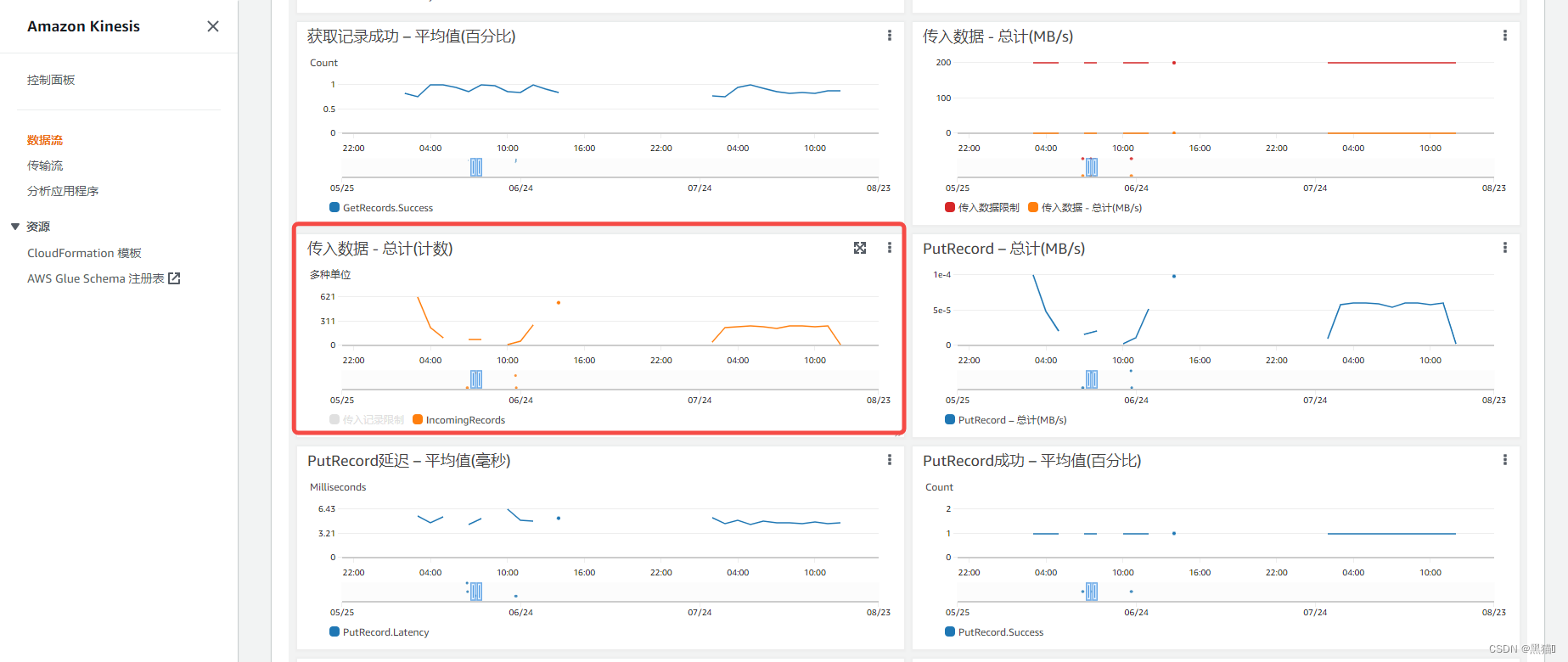
1.7.2 结果
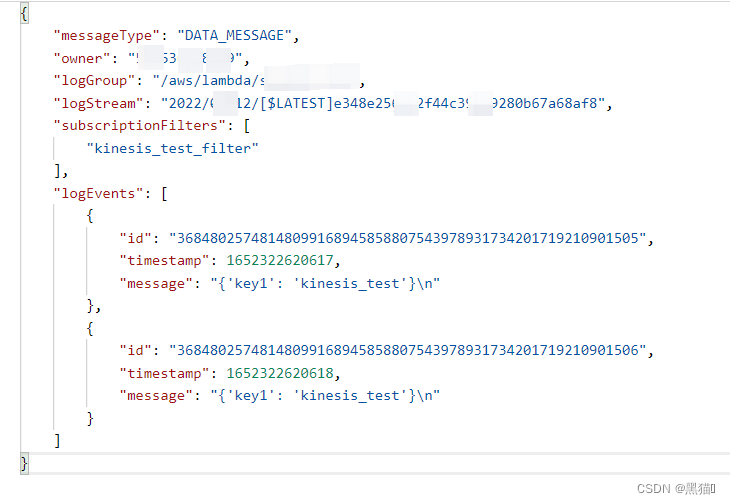
1.8 总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。