一、背景与简介
Redis关于高可用与分布式有三个与之相关的运维部署模式。分别是主从复制master-slave模式、哨兵Sentinel模式以及集群Cluster模式。
这三者都有各自的优缺点以及所应对的场景、对应的业务使用量与公司体量。
1、主从master-slave模式
【介绍】
这种模式可以采用一主一从、一主多从、以及树形结构的嵌套复制结构都是支持的。

【优点】
1、配置以及运维相对简单,可以支持读写分离,master节点负责写操作、slave负责进行读操作,同时slave作为master节点数据的一个备份,避免由于master节点挂掉,整个服务不可用。
【缺点】
1、master节点发生故障时需要人工进行介入,增加运维成本。通知客户端修改master的IP地址与端口,让slave节点顶上来作为主节点。那么之前的slave节点变成了主节点,等之前的old–master节点恢复后,反过来作为之前slave节点的从节点。 即使你可以把这个故障切主的过程进行自动脚本化,但是怎么确保多个slave中选择哪个slave成为新的主节点以及各种异常情况都能hold得住? 自己写的这个脚本就会变得很复杂。
2、切主暂且不说自动化脚本还能解决,但是你让业务方切换IP+端口这个事情万万是不能被接受的。用到这个Redis的地方太多了,你想改也改不过来,改了要发新配置代码,还有就是怕漏改。即使你使用Nacos等配置中心,也是一件让人头疼的事情
基于以上的几点考虑,官方推出了哨兵Sentinel模式,将这个过程自动化。切换流程不需要我们自己编写脚本,哨兵模式会可靠地帮我们完成这个故障切换过程,同时客户端也无须改变任何IP端口,无感进行故障切换。
【适应的公司体量】 小公司、创业公司或者业务量不是特别大的公司
2、哨兵Sentinel模式
【介绍 】
哨兵Sentinel模式其实是将master-slave主从模式故障切换从人工介入换成了自动化切换的过程,哨兵节点会高效、快速、可靠的从剩余的slave节点中选择出1个合适的节点作为新的master主节点,之后将剩余的slave节点切主到这个新的master节点。同时,客户端要获取master节点信息要通过连接sentinel来获取master的IP和端口,这样每次切主的过程,程序会自动完成,无感迁移。

【优点】
1、官方原生支持高可用方案,比第一种master-slave手动写切换脚本以及通知业务方更换IP+端口更加方便、可靠、稳定
【缺点】
1、虽然哨兵解决了高可用问题,但是无法解决高容量、高并发的需求。 因为一个哨兵始终只是维护master-slave的高可用而已,不能解决高并发、高容量问题。 这个后续的Cluster集群模式可以来解决。
2、切主的过程,可能会存在客户端短时间内连接不上master的情况,这个时间取决于故障迁移恢复时间。因为master节点挂了,哨兵在做故障迁移没结束之前,哨兵存储的master的信息还是挂掉的IP+端口,自然客户端继续连接挂掉的主机IP+端口就无法进行正常数据读写。
【适应的公司体量】 稍微有点业务体量与规模的公司
3、集群Cluster模式
【介绍】
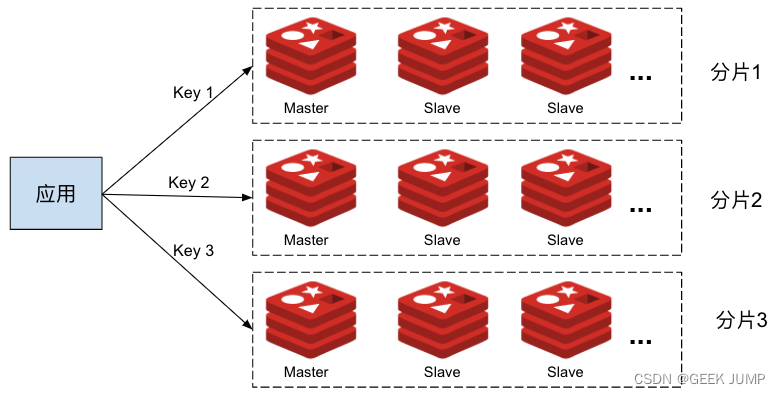
集群Cluster模式支持分布式部署,采用虚拟槽的设计思路,将存储的key进行CRC16($key)%16383的方式对数据进行分片存储和读取。 一共存在0-16383的slot虚拟槽位, 一个虚拟槽位slot理论上可以支持一个master+N个slave的主从架构模式。 那就是理论上可以支持16383个master+slave的主从架构模式, 这样的量就已经很牛逼了。
同时集群模式本身就支持高可用,一旦slot节点的master-slave主从结构的主节点挂了,那么会从它所属的slot的master-slave主从结构中进行重新切主操作。
不过官方推荐整个Redis集群不超过1000个节点。 想想一下,就算是1000个,如果按照一台服务器16G内存的情况计算,如果一半的内存进行存储也就是8G,整个集群的容量高达80TB。 这种基本上除了一线互联网大厂能玩得转,我看其它公司也没这个运维能力以及需求量了。
【优点】
2、同时支持高可用模式,自动切主,实现故障迁移。 虽然故障迁移期间,客户端也可能会出现无法正常访问Redis集群的情况,但是只会影响落到这个slot的这些key, 其它的key还是能正常访问的,具体还得按照实际情况计算,节点越多,单个slot故障影响越小,可能只存在20-30%无法访问,可以理解只是挂了部分。但是,哨兵模式切主过程中产生不可用的情况就不一样,哨兵模式是故障迁移期间整体100%都无法访问。
【缺点】
二、哨兵Sentinel-简单实验
1、主从配置是Sentinel、Cluster的基础
例如存在A节点作为master节点,存在2个slave节点分别是A1、A2.
那么在A1、A2分别执行
slaveof $master_ip $master_port即可完成A作为master节点,A1、A2作为其slave节点的一主两从的拓扑结构。
这个过于简单就不再演示,今天重点做Sentinel哨兵的故障模拟和迁移实验
2、环境搭建与测试
1、环境介绍
我们准备3个sentinel节点, 以及一个一主两从的结构。 让这个3个sentinel哨兵节点对整个一主两从进行监听与负责故障转移。
| hostname | IP | 端口 | 角色 | 备注 |
| s1 | 192.168.32.3 | 26379 | sentinel哨兵节点 | |
| s2 | 192.168.32.2 | 26379 | sentinel哨兵节点 | |
| s3 | 192.168.32.4 | 26379 | sentinel哨兵节点 | |
| master | 192.168.32.7 | 6379 | master节点 | |
| slave1 | 192.168.32.5 | 6379 | slave节点 | 主节点是master |
| slave2 | 192.168.32.6 | 6379 | slave节点 | 主节点是master |
version: "3"
services:
s1:
image: redis:5.0
hostname: s1
volumes:
- "./redis-sentinel-26379.conf:/data/redis-sentinel-26379.conf"
entrypoint: [ "tail", "-f", "/dev/null" ]
s2:
image: redis:5.0
hostname: s2
volumes:
- "./redis-sentinel-26379.conf:/data/redis-sentinel-26379.conf"
entrypoint: [ "tail", "-f", "/dev/null" ]
s3:
image: redis:5.0
hostname: s3
volumes:
- "./redis-sentinel-26379.conf:/data/redis-sentinel-26379.conf"
entrypoint: [ "tail", "-f", "/dev/null" ]
master:
image: redis:5.0
hostname: master
entrypoint: ["tail", "-f", "/dev/null"]
slave1:
image: redis:5.0
hostname: slave1
entrypoint: ["tail", "-f", "/dev/null"]
slave2:
image: redis:5.0
hostname: slave2
entrypoint: ["tail", "-f", "/dev/null"]2、Sentinel哨兵的配置文件
port 26379
daemonize yes
logfile "26379.log"
dir /data/
sentinel monitor mymaster master 6379 2 #Sentinel监控集群别名mymaster,监控的master这个用的host别名,可以写IP形式: 192.168.32.7, 6379是端口, 2是指投票个数
sentinel down-after-milliseconds mymaster 3000
sentinel failover-timeout mymaster 1800003、首先启动1主2从结构
docker-compose up -d --build #启动所有容器
# master节点
docker-compose exec master bash #进入master容器
redis-server &> /dev/null & #运行redis-server进入后台
# slave1节点
docker-compose exec slave1 bash #进入slave1容器
redis-server &> /dev/null & #运行redis-server进入后台
redis-cli #进入控制台
slaveof master 6379 #切主
info replication #查看主从复制情况
# slave2节点
docker-compose exec slave2 bash #进入slave2容器
redis-server &> /dev/null & #运行redis-server进入后台
redis-cli #进入控制台
slaveof master 6379 #切主
info replication #查看主从复制情况
查看master节点的集群节点信息: info replication
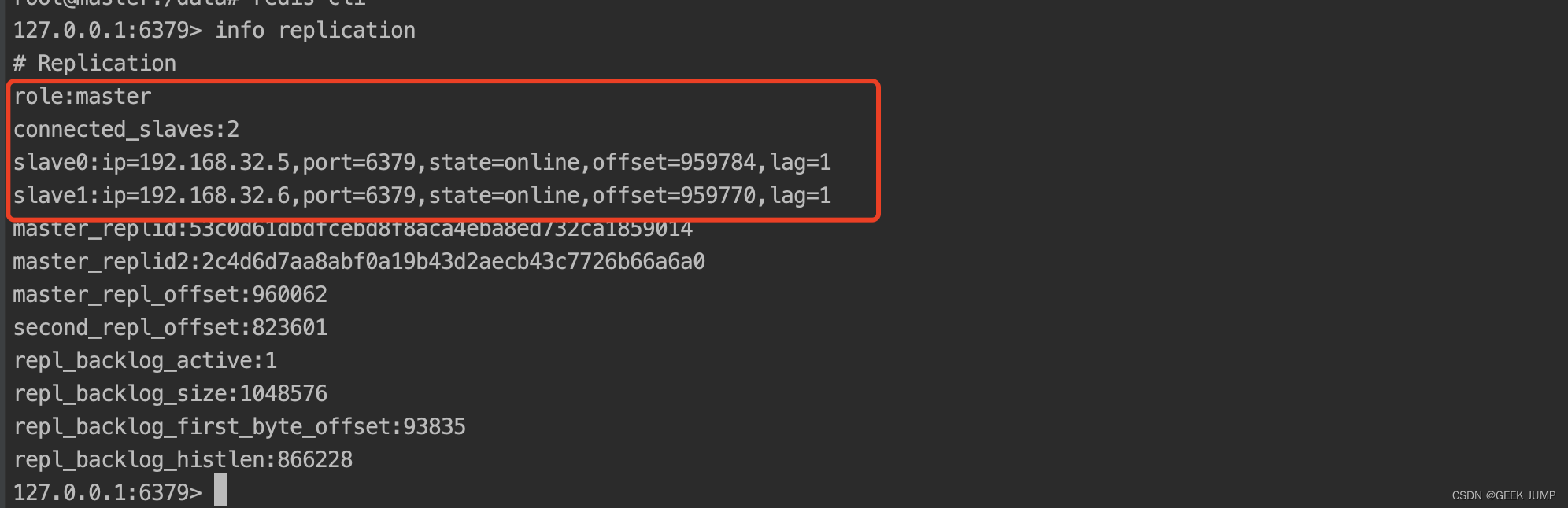
可以看到存在2个slave节点,分别是192.168.32.5(slave1)、192.168.32.6(slave2)正常连接运行
4、依次启动s1、s2、s3的Sentinel节点
redis-sentinel redis-sentinel-26379.conf #后台运行sentinel节点程序5、通过Sentinel API命令查看当前的master信息
sentinel masters
6、模拟master节点故障,将master容器进行docker–compose stop操作

再次进入s1 sentinel节点运行redis-cli, 执行sentinel masters指令查看当前master的信息:

此时可以看到,本来master是192.168.32.7是主节点,后来模拟故障将这个节点进行stop操作。此时故障迁移已经完成, 从192.168.32.5、192.168.32.6选择了192.168.32.5做为新的master节点.
同时我们进入192.168.32.5(slave1)查看当前info replication信息:
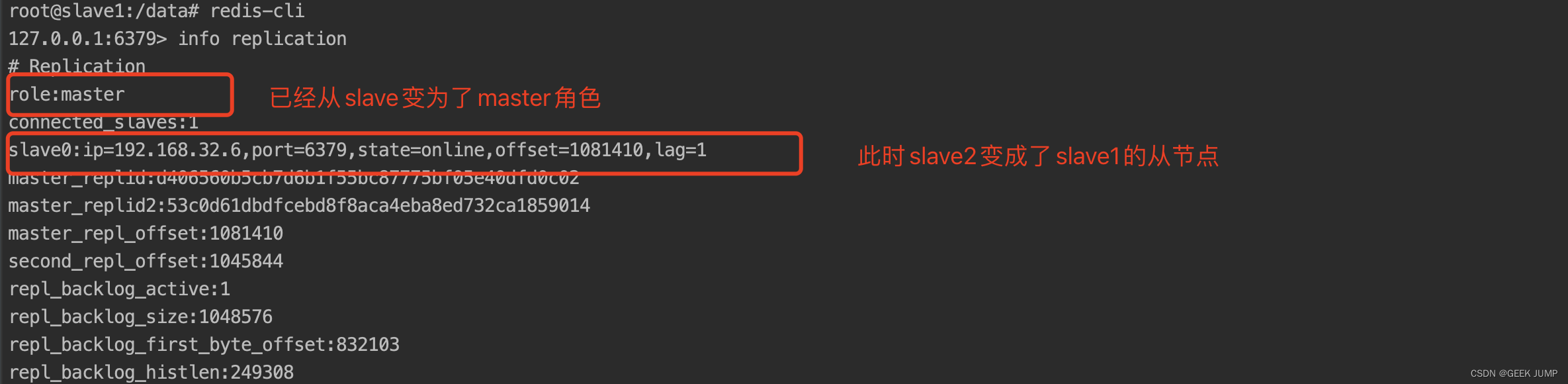
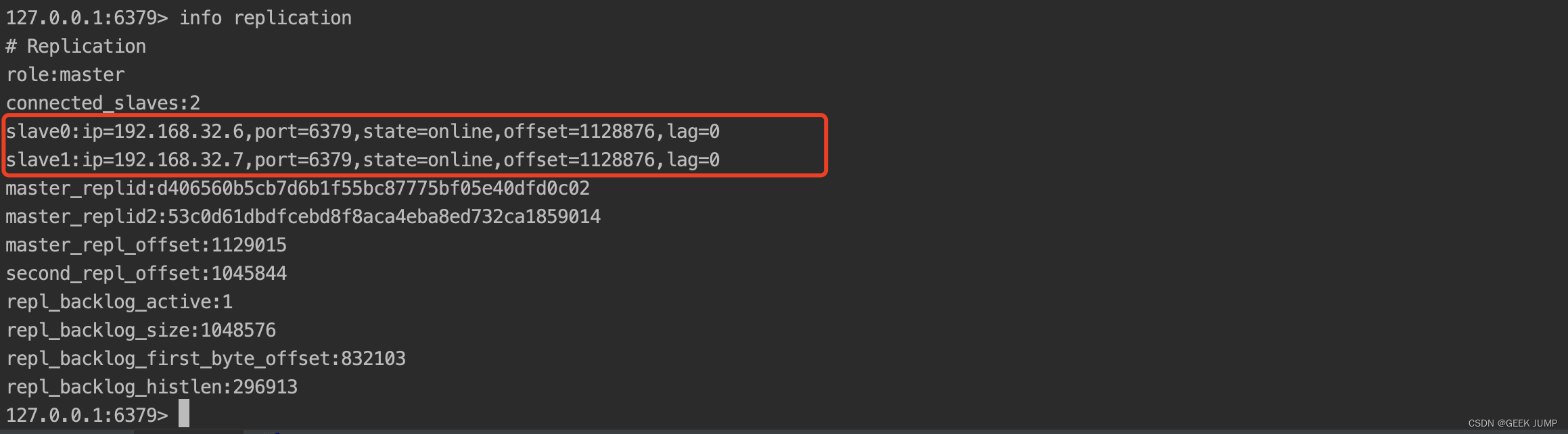
7、恢复刚才的master容器,此时slave1再运行info replication会多出从节点

从slave1节点运行info replication,此时可以看到192.168.32.7从一开始的主节点反过来变成了slave1的从节点, slave1已经变成了新的master主节点:
三、总结
选择简单主从模式、哨兵模式、或者集群模式,可以根据自己公司的业务量以及运维团队规模进行评估,选择合适的方案。 高可用一直和成本成反比关系,想要高可用那么付出的成本要变高,无论是运维成本还是资金成本, 反之,如果降低成本,那么可用性就会降低。
公司体量还很小,处于起步阶段,推荐简单主从模式基本上够用了,成本也不会很高。
如果已经稍微上规模了,还是推荐使用哨兵模式,这样故障迁移的过程就会自动化,无须人工介入更加稳定。
如果已经是发展到哨兵模式都无法满足业务需求了,再考虑使用Cluster集群模式,能够满足更高容量、高并发访问量的需求。
上面的这些模式都是基于IDC自己运维的机房或者自行搭建的机房环境,如果上云,自己想追求高可用性和可靠性,但是又没那么多运维精力的话,可以直接买云厂商的Redis服务即可,付钱买服务即可。
原文地址:https://blog.csdn.net/xyz_dream/article/details/134795673
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_48276.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!