本文介绍: Redis关于高可用与分布式有三个与之相关的运维部署模式。分别是主从复制master–slave模式、哨兵Sentinel模式以及集群Cluster模式。这三者都有各自的优缺点以及所应对的场景,以及对应的业务使用量,我们该怎么选择…
一、背景与简介
Redis关于高可用与分布式有三个与之相关的运维部署模式。分别是主从复制master-slave模式、哨兵Sentinel模式以及集群Cluster模式。
这三者都有各自的优缺点以及所应对的场景、对应的业务使用量与公司体量。
1、主从master-slave模式
【介绍】
这种模式可以采用一主一从、一主多从、以及树形结构的嵌套复制结构都是支持的。

2、哨兵Sentinel模式

3、集群Cluster模式
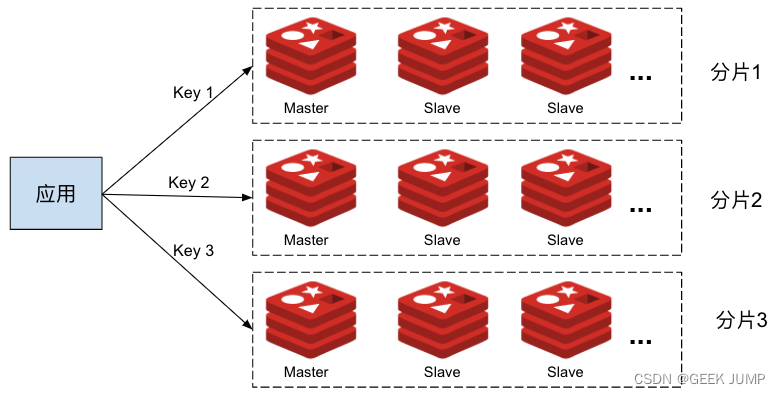
二、哨兵Sentinel-简单实验
1、主从配置是Sentinel、Cluster的基础
2、环境搭建与测试
1、环境介绍
2、Sentinel哨兵的配置文件
3、首先启动1主2从结构
4、依次启动s1、s2、s3的Sentinel节点
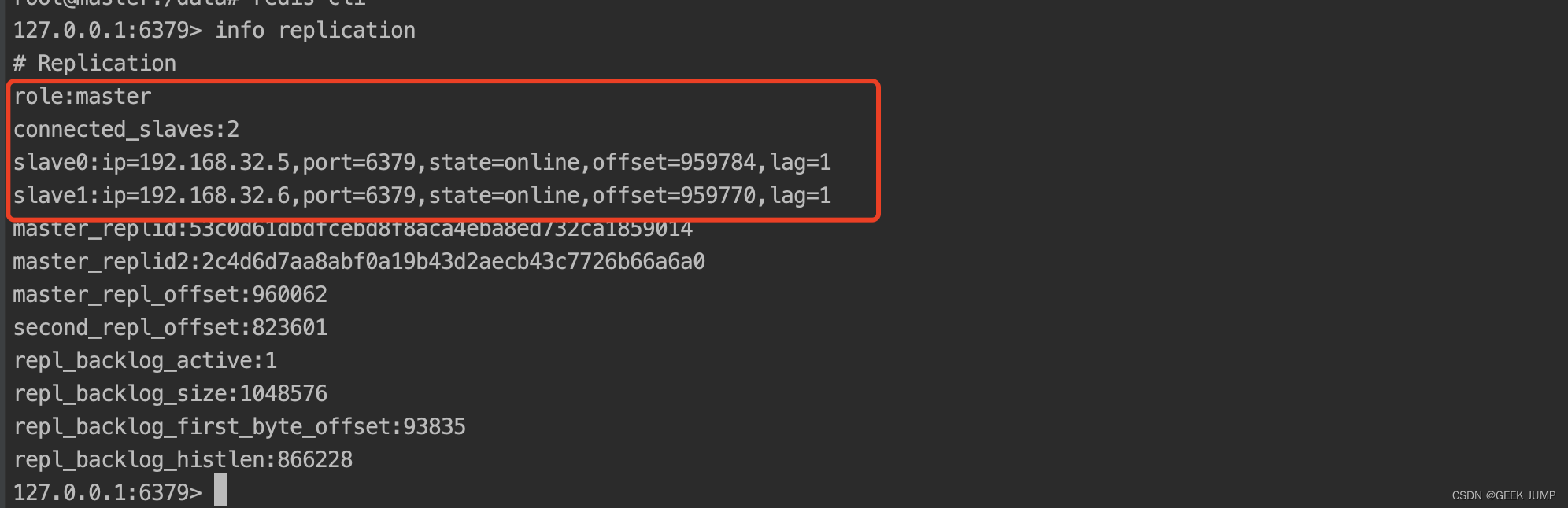
5、通过Sentinel API命令查看当前的master信息

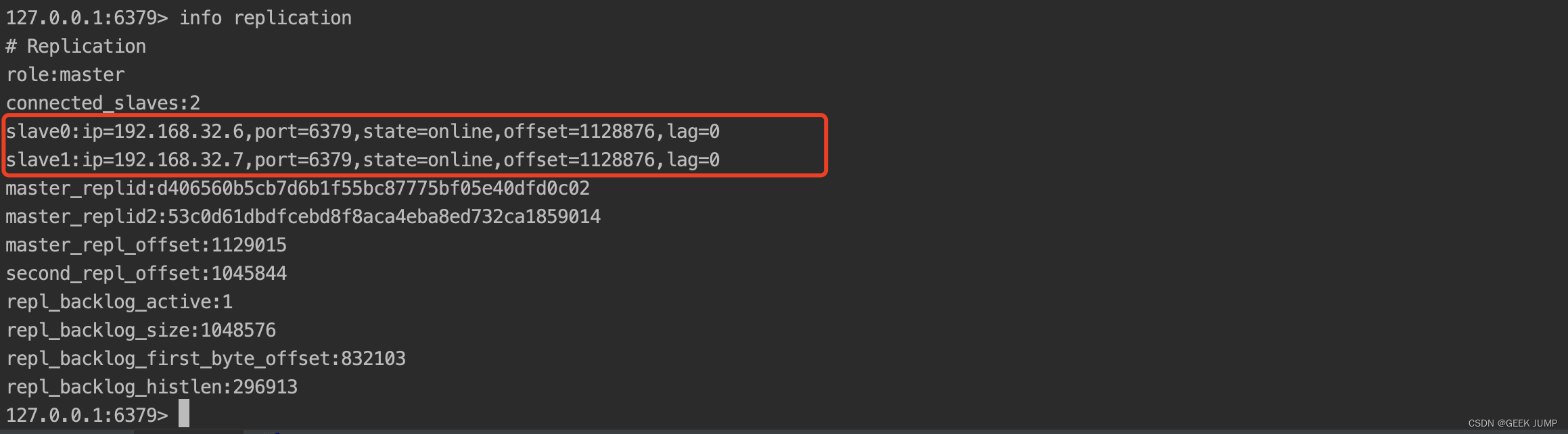
6、模拟master节点故障,将master容器进行docker–compose stop操作


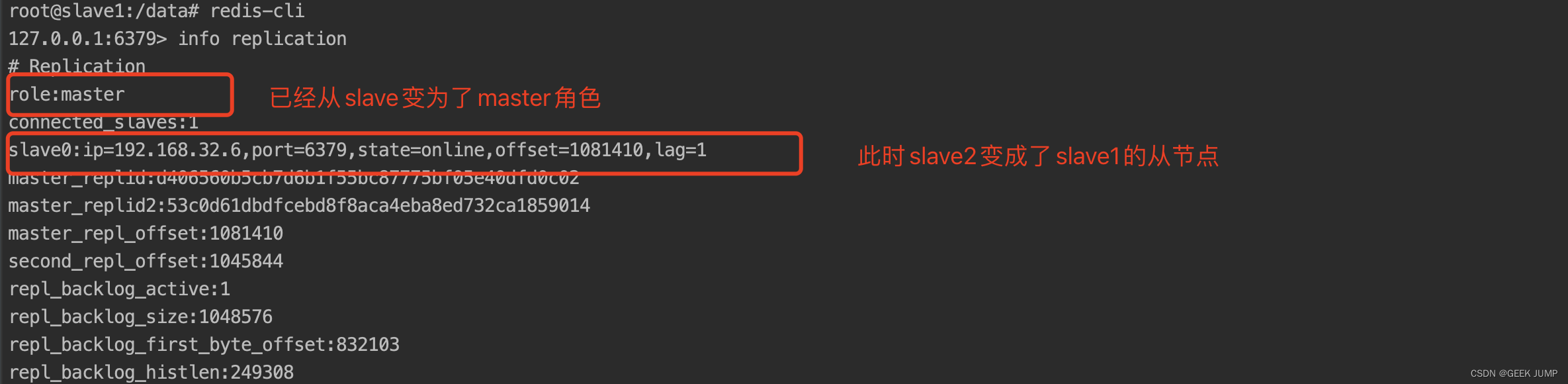
7、恢复刚才的master容器,此时slave1再运行info replication会多出从节点

三、总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。