论文标题:MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens
论文作者:Kaizhi Zheng* , Xuehai He* , Xin Eric Wang
作者单位:University of California, Santa Cruz
论文原文:https://arxiv.org/abs/2310.02239
论文出处:–
论文被引:1(12/31/2023)
论文代码:https://github.com/eric-ai-lab/MiniGPT-5,717 star
ABSTRACT
大型语言模型(LLMs)在自然语言处理方面的进步引起了广泛关注,在文本理解和生成方面显示出无与伦比的实力。然而,同时生成具有连贯文字叙述的图像仍然是一个不断发展的前沿领域。为此,我们引入了一种创新的交错(interleaved)视觉语言生成技术,该技术以生成式符号(generative vokens)为基础,协调(harmonized)图像和文本输出。我们的方法采用独特的两阶段训练策略,侧重于无描述多模态生成(description-free multimodal generation),即训练不需要全面的图像描述。为了加强模型的完整性,我们采用了无分类器指导(classifier-free guidance),从而提高了虚拟图像生成的有效性。在 MMDialog 数据集上,我们的模型 MiniGPT-5 与基线 Divter 模型相比有了显著提高,在 VIST 数据集上的人类评估中,MiniGPT-5 的多模态输出始终保持优异或相当的水平,突出了它在各种基准中的功效。
1 INTRODUCTION
在近期大规模视觉语言模型的发展中,多模态特征整合不仅是一种不断发展的趋势,而且是塑造从多模态对话智能体(Agent)到尖端内容创建工具等广泛应用的关键进步。随着研究和开发工作的激增,视觉语言模型(Wu et al., 2023;Li et al., 2023b;Tsimpoukelli et al., 2021;Alayrac et al., 2022)即将迎来一个时代,人们期待它们能无缝地理解和生成文本与图像内容。这种多方面的能力至关重要,因为它能增强虚拟现实,媒体和电子商务等各个领域的互动。从根本上说,我们的任务是让模型能够利用视觉和文本模式进行连贯的综合,识别和响应,协调信息流并创建连贯的叙述。融合文本和视觉模态并实现交错视觉和语言生成(如图 1 所示)是大型语言模型对更加集成和流畅的多模态交互的迫切需要所驱动的。

首先,虽然目前最先进的大型语言模型(LLMs)在理解文本和处理文本图像对方面表现出色,但在生成图像的细微艺术方面却乏善可陈。其次,新出现的视觉与语言交错(interleaved)任务(Sharma et al., 2018)摒弃了受益于详尽图像描述的传统任务,严重依赖于以主题为中心的数据(topic-centric data),往往需要使用详尽的图像描述符(Huang et al., 2016)。即使在海量数据集上进行了训练,要将生成的文本与相应的图像对齐也是一项挑战。最后,随着我们对 LLM 的研究不断深入,大量的内存需求要求我们设计出更高效的策略,尤其是在下游任务中。
为了应对这些挑战,我们提出了 MiniGPT-5,这是一种创新的交错视觉语言生成技术,以生成式符号(generative vokens)概念为基础。通过特殊的视觉标记(Tan & Bansal,2020)–生成式符号–将稳定扩散机制与 LLM 相结合,我们为熟练的多模态生成预示了一种新模式。同时,我们提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型即使在数据稀缺的情况下也能出色应对。
- 通用阶段不需要特定领域的注释,这使我们的解决方案与现有作品截然不同。
- 为确保生成的文本和图像和谐一致,我们采用了双损失策略,并通过创新的生成式 voken 方法和无分类器指导进一步加强了这一效果。
- 最后,我们的参数优化微调方法还能应对内存限制,优化训练效率。
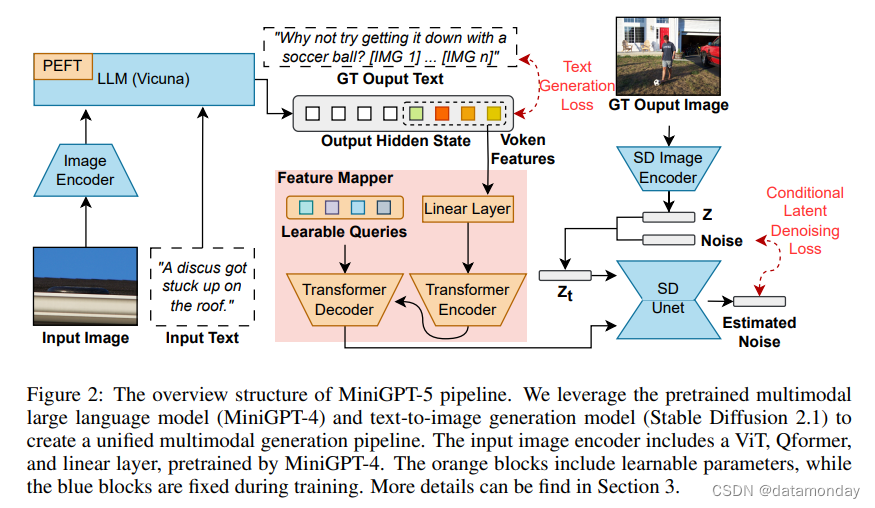
在这些技术的基础上,我们的工作是一种转换方法。如图 2 所示,通过使用 ViT (Vision Transformer) 和 Qformer (Li et al., 2023b) 以及大型语言模型,我们将多模态输入转换为生成式 vokens,并与高分辨率 Stable Diffusion 2.1 model (Rombach et al., 2022b) 无缝配对,实现上下文感知图像生成。通过将图像作为辅助输入与指令微调方法相结合,并率先采用文本和图像生成损失,我们扩大了文本和视觉之间的协同作用。我们提出的 MiniGPT-5 与 CLIP 约束等模型 (Rombach et al., 2022b) 相匹配,巧妙地将扩散模型与 MiniGPT-4 融合在一起,在不依赖特定领域注释的情况下实现了无与伦比的多模态结果。最重要的是,我们的策略可以利用多模态视觉语言基础模型的进步,为增强多模态生成能力带来广阔前景。
我们的贡献有三个方面:
-
我们建议使用多模态编码器,它代表了一种新颖的通用技术,已被证明比 LLM 更有效,并且可以反转为生成式 vokens,并将其与稳定扩散(Stable Diffusion)相结合,生成交错的视觉和语言输出(可进行多模态生成的多模态语言模型)。
-
我们重点介绍一种新的两阶段训练策略,用于无描述多模态生成。
- 单模态对齐阶段从大量文本图像对中获取高质量的文本对齐视觉特征。
- 多模态学习阶段包括一项新颖的训练任务,即提示上下文生成(prompted context generation),确保视觉和文本提示能够很好地协调生成。在训练阶段加入无分类器指导,可进一步提高生成质量。
-
与其他多模态生成模型相比,我们在 CC3M 数据集上取得了最先进的性能。我们还在 VIST 和 MMDialog 等著名数据集上建立了前所未有的基准。
2 RELATED WORK
Text-to-Image Generation
为了将文本描述转化为相应的视觉表征(visual representations),文本到图像模型 (Reed et al., 2016; Dhariwal & Nichol, 2021; Saharia et al., 2022; Rombach et al., 2022b;a; Gu et al., 2023) 采用了复杂的架构和精密的算法,在文本信息和视觉内容之间架起了一座桥梁。这些模型善于解读输入文本的语义,并将其转化为连贯,相关的图像。Stable Diffusion 2 (Rombach et al., 2022b) 是这一领域的最新成果,它利用扩散过程生成条件图像特征,然后根据这些特征重建图像。我们的研究旨在利用这一预训练模型,增强其适应多模态输入和输出的能力。
Multimodal Large Language Models
随着大型语言模型(LLMs)的影响力和可访问性与日俱增,越来越多的研究将这些经过预训练的 LLMs 扩展到多模态理解任务领域 (Zhu et al., 2023; Li et al., 2023b; Dai et al., 2023; OpenAI, 2023; Li et al., 2023a; Alayrac et al., 2022)。例如,为了复现 GPT-4中令人印象深刻的多模态理解能力,MiniGPT-4(Zhuet al., 2023)提出了一个投影层,将BLIP (Liet al., 2023b) 的预训练视觉组件与先进的开源大型语言模型Vicuna (Chiang et al., 2023) 对齐(alignment)。我们利用 MiniGPT-4 作为基础模型,并将该模型的功能扩展到多模态生成。
Multimodal Generation with Large Language Models
为了增强 LLM 无缝集成视觉和语言生成的能力,最近的研究引入了多种创新方法 (Ge et al., 2023; Sun et al., 2021; Koh et al., 2023; Sun et al., 2023b; Yu et al., 2023)。例如,
- CM3Leon(Yu et al., 2023)提出了一种检索增强型纯解码器架构,专为文本到图像和图像到文本应用而设计。
- Emu(Sun et al., 2023b)采用预训练的 EVA-CLIP(Sun et al., 2023a)模型将图像转换为一维特征,并对 LLAMA(Touvron et al., 2023)模型进行微调,通过自回归技术生成内聚的文本和图像特征。
- GILL(Koh et al., 2023)和 SEED(Ge et al., 2023)都探索了将 vokens 映射到预训练稳定扩散模型的文本特征空间的概念;GILL 采用了编码器-解码器框架,而 SEED 则利用了可训练的 Q-Former 结构。
与这些方法相比,我们的模型采用了更直接的方法,将 voken 特征与视觉信息对齐。此外,我们还引入了几种旨在提高图像质量和上下文连贯性的训练策略。
3 METHOD
为了使大型语言模型具备多模态生成能力,我们引入了一个结构化框架,将预训练多模态大型语言模型和文本到图像生成模型整合在一起。为了解决不同模型领域之间的差异,我们引入了特殊的视觉符号——generative vokens——能够直接在原始图像上进行训练。此外,我们还提出了一种两阶段训练方法,并结合无分类器引导策略,以进一步提高生成质量。随后的章节将对这些要素进行详细探讨。
3.1 MULTIMODAL INPUT STAGE
多模态大型语言模型(如 MiniGPT-4)的最新进展主要集中在多模态理解方面,可将图像作为连续输入进行处理。为了将其功能扩展到多模态生成,我们引入了专为输出视觉特征而设计的生成式vokens。此外,我们还在大语言模型(LLM)框架内采用了尖端的,参数效率高的微调技术,用于多模态输出学习。下文将对这些发展进行更详细的介绍。
Multimodal Encoding
每个文本标记(text token)被嵌入到一个向量
e
t
e
x
t
∈
R
d
e_{text} ∈ R^d
etext∈Rd 中,而预训练的视觉编码器则将每个输入图像转换为特征
e
i
m
g
∈
R
32
×
d
e_{img} ∈ R^{32×d}
eimg∈R32×d。这些嵌入向量串联起来就形成了输入提示特征。
Adding Vokens in LLM
由于原始 LLM 的
V
V
V 词汇表只包括文本标记,我们需要在 LLM 和生成模型之间搭建一座桥梁。因此,我们引入了一组特殊标记
V
i
m
g
=
{
[
I
M
G
1
]
,
[
I
M
G
2
]
,
.
.
.
,
[
I
M
G
n
]
}
V_{img} = {[IMG1], [IMG2], … ,[IMGn]}
Vimg={[IMG1],[IMG2],…,[IMGn]}(默认 n = 8)作为生成式 vokens 引入 LLM 的词汇表
V
V
V 中。LLM 输出的隐藏状态将被用于后续图像生成,而这些符号的位置可以代表插入的交错图像。由于 MiniGPT-4 中所有预训练的权重
θ
p
r
e
t
r
a
i
n
e
d
θ_{pretrained}
θpretrained 都是固定的,因此可训练的参数包括额外的输入嵌入值
θ
v
o
k
e
n
_
i
n
p
u
t
θ_{voken_input}
θvoken_input 和输出嵌入值
θ
v
o
k
e
n
_
o
u
t
p
u
t
θ_{voken_output}
θvoken_output。
Parameter-Efficient Fine-Tuning (PEFT)
参数高效微调(PEFT)(Houlsby et al., 2019;Hu et al., 2021;Li & Liang,2021)对于训练大型语言模型(LLMs)至关重要。尽管如此,其在多模态环境中的应用在很大程度上仍未得到探索。我们在 MiniGPT-4(Zhu et al., 2023)编码器上使用 PEFT 来训练模型,使其更好地理解指令或提示,从而提高其在新任务甚至零样本任务中的表现。具体地,在 MiniGPT-4 中的语言编码器 Vicuna (Chiang et al., 2023) 上尝试了 prefix tuning (Li & Liang, 2021) 和 LoRA。它与指令微调相结合,显著提高了 VIST 和 MMDialog 等各种数据集的多模态生成性能。
3.2 MUTIMODAL OUPUT GENERATION
为了使生成标记与生成模型精确对齐,我们制定了一个用于维度匹配(dimension matching)的紧凑映射模块,并纳入了若干监督损失,包括文本空间损失和潜在扩散模型损失。文本空间损失有助于模型学习标记(tokens)的正确位置,而潜在扩散损失则直接将标记与适当的视觉特征对齐。由于生成式 vokens 的特征直接由图像引导,因此我们的方法不需要全面的图像描述,从而实现了无描述学习。
Text Space Generation
首先,我们按照因果语言建模(casual language modeling)的方法,在文本空间中联合生成文本和 vokens。在训练过程中,我们将 vokens 添加到真实(ground truth)图像的位置,并训练模型在文本生成过程中预测 vokens。具体来说,生成的 token 表示为 T = {t1, t2, . , tm},其中 ti ∈ V ∪ Vimg,因果语言建模损失定义为:
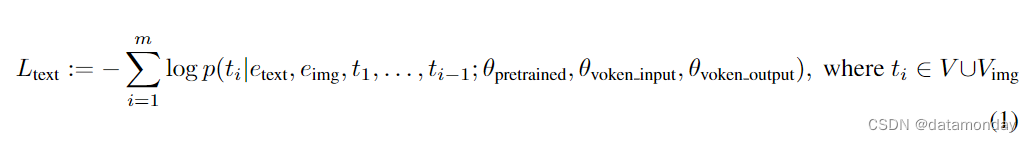
Mapping Voken Features for Image Generation
接下来,我们将输出隐藏状态 hvoken 与文本到图像生成模型的文本条件特征空间对齐。将 voken 特征 hvoken 映射到可行的图像生成条件特征
e
t
e
x
t
_
e
n
c
o
d
e
r
∈
R
L
×
d
^
e_{text_encoder} ∈ R^{L× hat{d}}
etext_encoder∈RL×d^(其中
L
L
L 为文本到图像生成文本编码器的最大输入长度,
d
^
hat{d}
d^ 为文本到图像生成模型中编码器输出特征的维度)。我们构建了一个特征映射模块,包括一个两层 MLP 模型
θ
M
L
P
θ_{MLP}
θMLP,一个四层编码器-解码器变换模型
θ
e
n
c
−
d
e
c
θ_{enc-dec}
θenc−dec 和一个可学习的解码器特征序列
q
q
q:

Image Generation with Latent Diffusion Model (LDM)
为了生成合适的图像,映射特征
h
^
v
o
k
e
n
hat{h}_{voken}
h^voken 被用作去噪过程中的条件输入。直观地说,
h
^
v
o
k
e
n
hat{h}_{voken}
h^voken 应该代表相应的文本特征,引导扩散模型生成真实图像。我们采用潜在扩散模型(Latent Diffusion Model,LDM)的损失作为指导。在训练过程中,首先通过预训练的 VAE 将真实图像转换为潜特征 z0。然后,在 z0 中加入噪声 ε,得到噪声潜特征 zt。预训练的 U-Net 模型 εθ 用于计算条件 LDM 损失,即
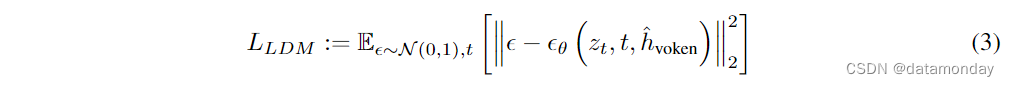
这种全面的方法可确保对文本和视觉元素进行连贯的理解和生成,充分利用了预训练模型,专用 tokens 和创新训练技术的能力。
3.3 TRAINING STRATEGY
鉴于文本域和图像域之间存在不可忽略的域偏移(domain shift),我们发现在有限的交错文本和图像数据集上进行直接训练可能会导致未对齐(misalignment)和图像质量下降。因此,我们采用了两种不同的训练策略来缓解这一问题。
- 第一种策略包括采用 classifier-free guidance (Ho & Salimans, 2022),在整个扩散过程中提高生成 tokens 的有效性。
- 第二种策略分两个阶段展开:最初的预训练阶段侧重于粗略的特征对齐,随后的微调阶段致力于复杂的特征学习。
Classifier-free Guidance (CFG)
为了增强生成的文本与图像之间的一致性,我们首先利用了多模态生成的无分类器引导(Classifier-free Guidance)思想。在文本到图像的扩散过程中引入了无分类器引导。这种方法认为,生成模型 Pθ 可以通过对有条件生成和无条件生成进行训练,并进行条件剔除(conditioning dropout),从而获得更好的条件结果。在我们的上下文中,我们的目标是突出可训练的条件 hvoken,而生成模型是固定的。在训练过程中,我们以 10% 的概率将 hvoken 替换为零特征
h
0
∈
0
n
×
d
h_0 ∈ 0^{n×d}
h0∈0n×d,得到无条件特征
h
^
0
=
θ
e
n
c
−
d
e
c
(
θ
M
L
P
(
h
0
)
,
q
)
hat{h}_0 = θ_{enc-dec}(θ_{MLP}(h_0), q)
h^0=θenc−dec(θMLP(h0),q)。在推理过程中,
h
^
0
hat{h}_0
h^0 作为负提示(negative prompting),细化去噪过程(refined denoising process)表示为:
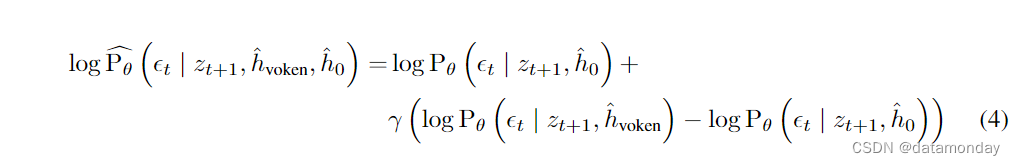
Two-stage Training Strategy
认识到纯文本生成和文本图像生成之间的 non-trivial domain shift,我们提出了一种两阶段训练策略:单模态对齐阶段(UAS)和多模态学习阶段(MLS)。首先,我们将 voken 特征与单文本-图像配对数据集(如 CC3M)中的图像生成特征进行对齐,在单文本-图像配对数据集中,每个数据样本只包含一个文本和一张图像,文本通常是图像的描述。在这一阶段,我们利用标题作为 LLM 输入,使 LLM 能够生成 vokens。由于这些数据集包含图像描述信息,我们还引入了辅助损失来帮助 voken 对齐,最小化文本到图像生成模型中生成特征
h
^
v
o
k
e
n
hat{h}_{voken}
h^voken 与来自文本编码器 τθ 的标题特征之间的距离:
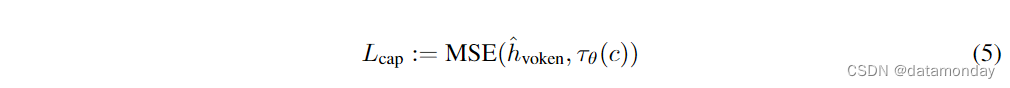
单模态对齐阶段损失表示为 LUAS = λ1 ∗ Ltext + λ2 ∗ LLDM + λ3 ∗ Lcap,选取值 λ1 = 0.01,λ2 = 1,λ3 = 0.1,以将损失调整到类似的数值范围。
在单模态配准阶段之后,该模型能够为单一文本描述生成图像,但在交错视觉语言生成方面却举步维艰,因为交错视觉语言包含多个文本-图像对,需要对文本和图像生成进行复杂的推理。为了解决这个问题,在多模态学习阶段,我们通过交错视觉语言数据集(如 VIST)进一步微调了带有 PEFT 参数的模型。在这一阶段,我们从数据集中构建了三种类型的任务,包括:
- 1)纯文本生成:给定下一幅图像,生成相关文本
- 2)纯图像生成:给定下一段文本,生成相关图像
- 3)多模态生成:根据给定上下文生成文本-图像对
多模态学习阶段的损失为 LMLS = λ1 ∗ Ltext + λ2 ∗ LLDM。更多实现细节见附录 A。
4 EXPERIMENTS
为了评估我们模型的功效,我们在多个基准中进行了一系列评估。这些实验旨在解决几个关键问题:
- 1)我们的模型能否生成可信的图像和合理的文本?
- 2)在单轮和多轮交错视觉语言生成任务中,我们的模型与其他最先进模型相比性能如何?
- 3)每个模块的设计对整体性能有什么影响?
在随后的小节中,我们将深入探讨这些评估所使用的数据集和实验设置,然后对我们模型的性能进行全面分析。有关数据集和数据格式的更多详情,请参阅附录 B。
4.1 EXPERIMENTAL SETTINGS
Baselines
为了全面评估我们在多模态生成方面的性能,我们与几个著名的基准模型进行了比较分析:Fine-tuned Unimodal Generation Model,GILL 和 Divter。
- Fine-tuned Unimodal Generation Model: 为便于在图像和文本生成方面进行公平比较,我们利用 VIST 数据集对稳定扩散 2.1 和 MiniGPT4 这两个独立模型进行了微调。在稳定扩散 2.1 模型中,U-Net 参数被解冻,而 MiniGPT-4 的 LLM 部分则加入了 LoRA 参数。
- GILL (Koh et al., 2023): GILL 是最近的一项创新,它允许 LLM 使用预先训练好的文本到图像生成模型生成 vokens,用于单图像生成。与我们采用条件生成损失指导的方法不同,GILL 将文本到图像文本编码特征与 voken 特征之间的平均平方误差(MSE)损失最小化,类似于我们方法中的 Lcap。由于他们的方法需要图像描述来进行训练,因此我们仅在单模态对齐阶段与其进行比较。
Metrics
为了全面评估模型在图像,文本和多模态维度上的性能,我们采用了一系列不同的指标。为了评估生成图像的质量和多样性,我们采用了:
- Inception Score (IS) (Salimans et al., 2016)
- Fr ́echet Inception Distance (FID) (Heusel et al., 2017)
文本性能通过 BLEU (Papineni et al., 2002), Rouge-L (Lin, 2004), METEOR (Banerjee & Lavie, 2005), and Sentence-BERT (SBERT) (Reimers & Gurevych, 2019) scores 等指标来衡量。
在多模态方面,我们利用基于 CLIP 的指标 (Rombach et al., 2022b) 来评估生成内容与 ground truth 之间的一致性。CLIP-I 评估生成图像与真实图像之间的相似性,而 CLIP-T 则侧重于生成图像与真实文本之间的一致性。为了解决多模态生成中可能出现的未对齐问题,例如当 ground truth 是纯文本但输出是多模态时,我们采用了 MM-Relevance(Feng et al., 2022)。该指标根据 CLIP 相似度计算 F1 分数,从而对多模态一致性进行细致入微的评估。
认识到生成的多模态输出可能有意义,但与 ground truth 不同,我们还结合了人工评估来评估模型的性能。我们从三个方面考察模型的有效性:
- 1)语言连续性–评估生成的文本是否与所提供的上下文无缝衔接
- 2)图像质量–评估生成图像的清晰度和相关性
- 3)多模态一致性–确定文本与图像的组合输出是否与初始上下文一致
4.2 EXPERIMENTAL RESULTS
在本节中,我们将定量分析我们的模型在不同训练阶段的不同基准上的性能。定性实例见图 3。

4.2.1 MULTIMODAL LEARNING STAGE
在本小节中,我们将介绍不同模型在 VIST(Huang et al., 2016)和 MMDialg(Feng et al., 2022)数据集上的表现。我们的评估横跨视觉(图像相关指标)和语言(文本指标)两个领域,以展示所提模型的通用性和鲁棒性。
VIST Final-Step Evaluation
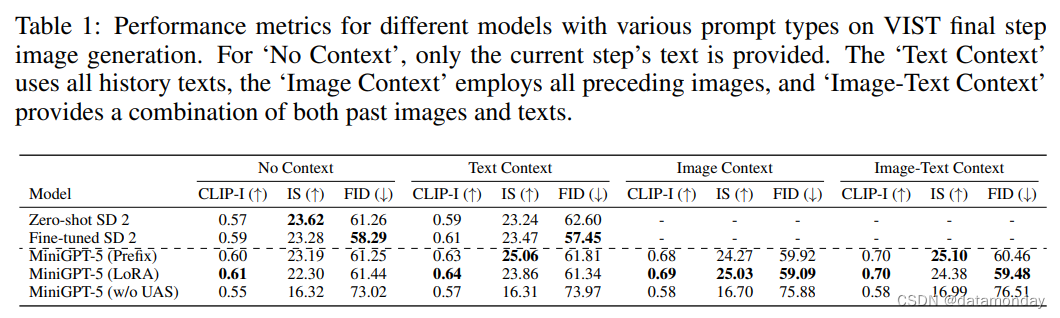
我们的第一组实验涉及单步评估,即根据最后一步的提示,模型生成相应的图像。表 1 总结了这一设置的结果。在所有三种情况下,MiniGPT-5 的性能都优于经过微调的 SD 2,显示了 MiniGPT-5 管道的优势。值得注意的是,MiniGPT-5(LoRA)模型的 CLIP 得分在多种提示类型中始终超过其他变体,尤其是在结合图像和文本提示时。另一方面,FID 分数凸显了 MiniGPT-5(Prefix)模型的竞争力,表明图像嵌入质量(由 CLIP 分数反映)与图像的多样性和真实性(由 FID 分数反映)之间可能存在权衡。与直接在 VIST 上进行训练而不包含单模态配准阶段的模型(MiniGPT-5 w/o UAS)相比,虽然该模型保留了生成有意义图像的能力,但图像质量和一致性明显下降。这一观察结果凸显了我们两阶段训练策略的重要性。
VIST Multi-Step Evaluation

在详细而全面的评估中,我们系统地为模型提供了先前的历史背景,并随后在每个步骤中对生成的图像和叙述进行评估。表 2 和表 3 概述了这些实验的结果,分别概括了图像和语言指标的性能。实验结果表明,MiniGPT-5 能够在所有数据中利用长横向多模态输入提示生成连贯,高质量的图像,而不会影响原始模型的多模态理解能力。这凸显了我们的模型在不同环境中的功效。
VIST Human Evaluation
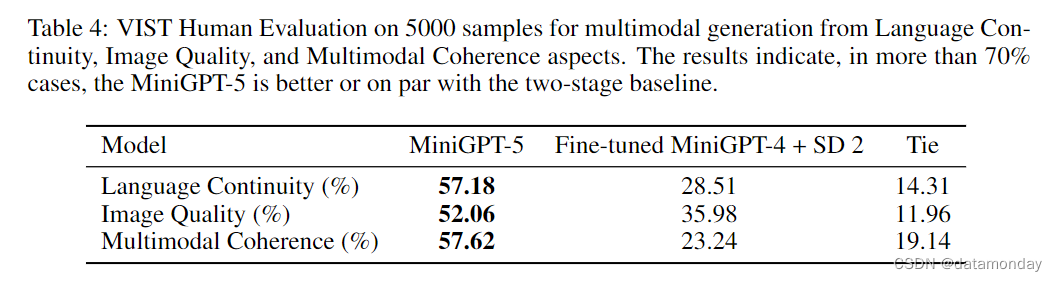
为了评估多模态生成的质量,我们在 VIST 验证集上测试了我们的模型和基线模型。在每个任务中,给定前面的多模态序列,模型的任务是生成后面的场景。为了确保比较的公平性,我们使用了经过微调的 MiniGPT-4,该模型专门用于生成没有任何 vokens的叙述。随后,这些叙述将通过文本到图像管道直接纳入 Stable Diffusion 2。我们随机抽取了 5000 个序列,每个序列都需要两名工作人员进行评估。这些评估人员的任务是根据三项标准确定优秀的多模态输出:语言连续性,图像质量和多模态一致性。Amazon Mechanical Turk (Crowston, 2012) 为这一评估提供了便利,附录中提供了一个具有代表性的示例 (Fig. 4)。如表 4 所示,我们的模型 MiniGPT-5 在 57.18% 的案例中生成了更贴切的文字叙述,在 52.06% 的案例中提供了更出色的图像质量,在 57.62% 的场景中生成了更连贯的多模态输出。与采用文本到图像提示叙述而不包含 vokens的两阶段基线相比,这些数据明显展示了其更强的多模态生成能力。
MMDialog Multi-Turn Evaluation
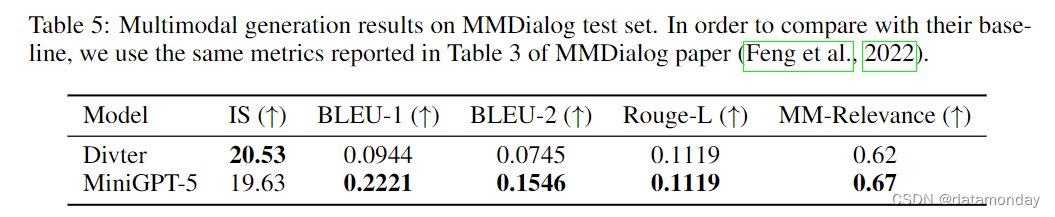
我们在 MMDialog 数据集上对我们的方法进行了评估,以确定在多轮对话场景中生成精确,适当的多模态信息的有效性。在该数据集的对话中,模型需要根据之前的回合生成单模态或多模态响应。表 5 所示的结果表明,MiniGPT-5 在生成更准确的文本回复方面优于基线模型 Divter。虽然生成的回复的图像质量相似,但与基准模型相比,MiniGPT-5 在 MM 相关性方面更胜一筹。这表明我们的模型可以更好地学习如何适当定位图像生成,并生成高度一致的多模态响应。
4.2.2 UNIMODAL ALIGNMENT STAGE
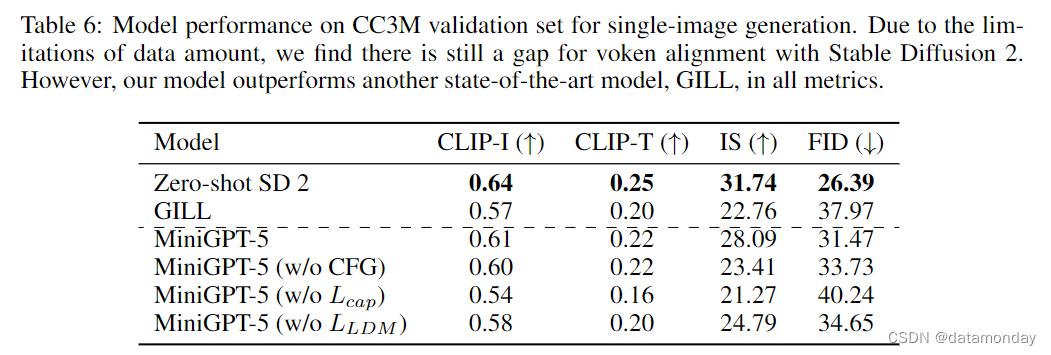
我们没有在多轮多模态数据集上进行评估,而是在单图像数据集 CC3M (Sharma et al., 2018) 中对模型进行了评估,如表 6 所示。结果表明,虽然我们的模型在多轮场景下可以有更好的生成效果,但 Stable Diffusion 2 模型在单图像生成的所有指标上都取得了最佳结果。由于我们的模型在这一阶段试图与 Stable Diffusion 2 的预训练文本编码器保持一致,因此由于数据量的限制,在性能上略有差距。与在 VIST 数据集上的观察结果相比,我们可以得出结论:MiniGPT-5 可以正确提取长横向多模态信息中的特征,而不是单一的文本输入。这指明了如何将 LLM 与生成模型高效地结合起来的未来方向。另一方面,我们的模型在所有指标上都优于另一个最先进的多模态生成模型 GILL。我们的模型生成的图像更连贯,质量更高,与预训练的稳定扩散模型生成的图像非常相似。为了进一步评估我们设计的有效性,我们进行了多项消融研究,关于 voken 数量和 CFG 尺度的更多消融研究可参见附录 C。
Evaluation of Different Loss Guidance
我们在 CC3M 训练中引入了辅助损失,称为 Lcap。为了评估该损失的影响,并确定仅靠单一的标题损失是否能生成像 GILL 这样的高质量图像,我们在不使用图像描述损失 Lcap 和条件潜在扩散损失 LLDM 的情况下分别对模型进行了训练。结果(如表 6 所示)表明,图像描述损失对生成更好的图像有显著帮助,而条件潜扩散损失则进一步提高了一致性和图像质量方面的性能。
Evaluation of Classifier-Free Guidance (CFG)
为了评估 CFG 策略的有效性,我们在没有 CFG 下降的情况下对模型进行了训练。在推理过程中,模型使用了原始的 CFG 去噪过程,该过程利用了 Stable Diffusion 2 文本编码器中的空图像描述特征作为负提示特征。表 6 中的结果表明,在没有 CFG 的情况下,所有指标都变差了,这表明 CFG 训练策略提高了图像生成质量。

5 CONCLUSION
在本文中,我们介绍了 MiniGPT-5,其目的是通过将 LLM 与预先训练的文本到图像生成模型对齐,增强 LLM 在多模态生成方面的能力。综合实验证明,我们的方法有很大的改进。通过这项工作,我们希望在多模态生成模型方面树立一个新的标杆,为以前由于现有图像和文本合成范式的脱节而被认为具有挑战性的应用打开大门。
A IMPLEMENTATION DETAILS
B EXPERIMENTAL SETTINGS
B.1 DATASETS
B.2 DATA FORMAT
C MORE EXPERIMENTS
C.1 EVALUATION OF GUIDANCE SCALE:
C.2 EVALUATION OF VOKEN NUMBER:
D MORE QUALITATIVE EXAMPLES
原文地址:https://blog.csdn.net/weixin_39653948/article/details/135431320
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_52860.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!





