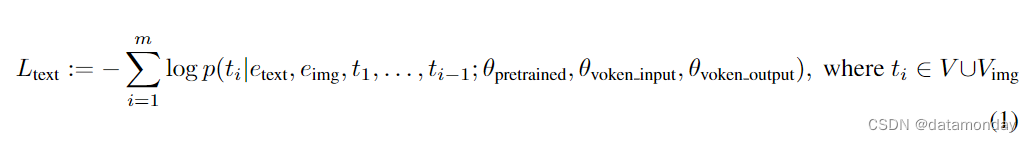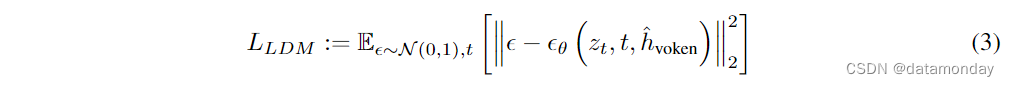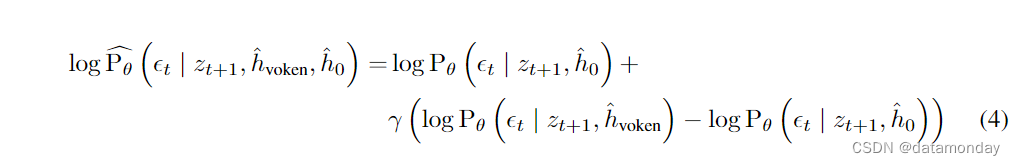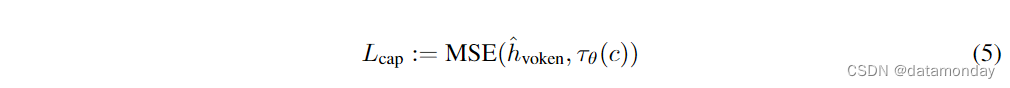ABSTRACT
大型语言模型(LLMs)在自然语言处理方面的进步引起了广泛关注,在文本理解和生成方面显示出无与伦比的实力。然而,同时生成具有连贯文字叙述的图像仍然是一个不断发展的前沿领域。为此,我们引入了一种创新的交错(interleaved)视觉语言生成技术,该技术以生成式符号(generative vokens)为基础,协调(harmonized)图像和文本输出。我们的方法采用独特的两阶段训练策略,侧重于无描述多模态生成(description-free multimodal generation),即训练不需要全面的图像描述。为了加强模型的完整性,我们采用了无分类器指导(classifier-free guidance),从而提高了虚拟图像生成的有效性。在 MMDialog 数据集上,我们的模型 MiniGPT-5 与基线 Divter 模型相比有了显著提高,在 VIST 数据集上的人类评估中,MiniGPT-5 的多模态输出始终保持优异或相当的水平,突出了它在各种基准中的功效。
1 INTRODUCTION
在近期大规模视觉语言模型的发展中,多模态特征整合不仅是一种不断发展的趋势,而且是塑造从多模态对话智能体(Agent)到尖端内容创建工具等广泛应用的关键进步。随着研究和开发工作的激增,视觉语言模型(Wu et al., 2023;Li et al., 2023b;Tsimpoukelli et al., 2021;Alayrac et al., 2022)即将迎来一个时代,人们期待它们能无缝地理解和生成文本与图像内容。这种多方面的能力至关重要,因为它能增强虚拟现实,媒体和电子商务等各个领域的互动。从根本上说,我们的任务是让模型能够利用视觉和文本模式进行连贯的综合,识别和响应,协调信息流并创建连贯的叙述。融合文本和视觉模态并实现交错视觉和语言生成(如图 1 所示)是大型语言模型对更加集成和流畅的多模态交互的迫切需要所驱动的。

首先,虽然目前最先进的大型语言模型(LLMs)在理解文本和处理文本图像对方面表现出色,但在生成图像的细微艺术方面却乏善可陈。其次,新出现的视觉与语言交错(interleaved)任务(Sharma et al., 2018)摒弃了受益于详尽图像描述的传统任务,严重依赖于以主题为中心的数据(topic-centric data),往往需要使用详尽的图像描述符(Huang et al., 2016)。即使在海量数据集上进行了训练,要将生成的文本与相应的图像对齐也是一项挑战。最后,随着我们对 LLM 的研究不断深入,大量的内存需求要求我们设计出更高效的策略,尤其是在下游任务中。
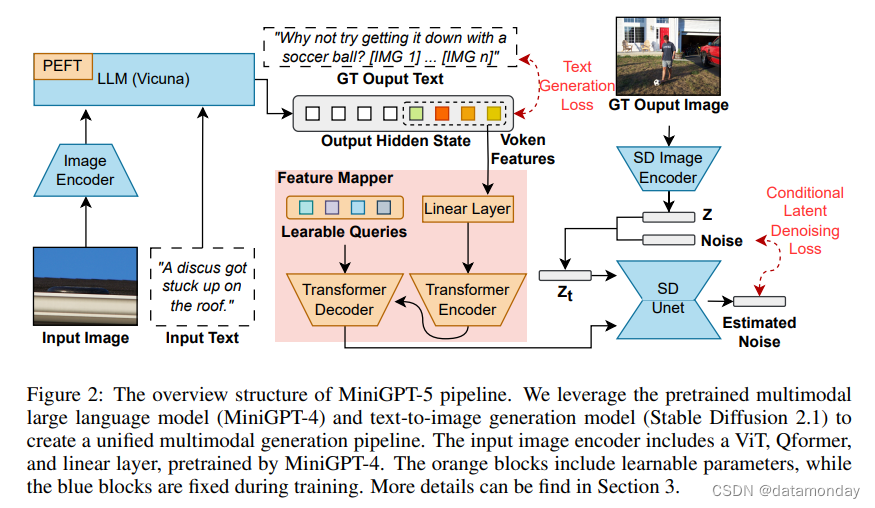
为了应对这些挑战,我们提出了 MiniGPT-5,这是一种创新的交错视觉语言生成技术,以生成式符号(generative vokens)概念为基础。通过特殊的视觉标记(Tan & Bansal,2020)–生成式符号–将稳定扩散机制与 LLM 相结合,我们为熟练的多模态生成预示了一种新模式。同时,我们提出的两阶段训练方法强调了无描述基础阶段的重要性,使模型即使在数据稀缺的情况下也能出色应对。
2 RELATED WORK
Text-to-Image Generation
Multimodal Large Language Models
Multimodal Generation with Large Language Models
3 METHOD
3.1 MULTIMODAL INPUT STAGE
Multimodal Encoding
e
t
e
x
t
∈
R
d
e_{text} ∈ R^d
etext∈Rd 中,而预训练的视觉编码器则将每个输入图像转换为特征
e
i
m
g
∈
R
32
×
d
e_{img} ∈ R^{32×d}
Adding Vokens in LLM
V
V