本文整理自阿里云 Flink 团队归源老师关于阿里云 Flink 原理分析与应用:深入探索 MongoDB Schema Inference 的研究,内容主要分为以下四部分:
- MongoDB 简介
- 社区MongoDB CDC 核心特性
- MongoDB CDC 在阿里云 Flink 实时计算产品的实践
- 总结
一、MongoDB 简介
MongoDB 是一种面向文档的非关系型数据库,支持半结构化数据存储;也是一种分布式的数据库,提供副本集和分片集两种集群部署模式,具有高可用和水平扩展的能力,比较适合大规模的数据存储。
MongoDB 使用了弱结构化的存储模式,支持灵活的数据结构和丰富的数据类型,适合 Json 文档、标签、快照、地理位置、内容存储等业务场景。它天然的分布式架构提供了开箱即用的分片机制和自动 rebalance 能力,适合大规模数据存储。另外, MongoDB 还提供了分布式网格文件存储的功能,即 GridFS,适合图片、音频、视频等大文件存储。

二、社区 MongoDB CDC 核心特性
Flink CDC 是基于数据库的日志 CDC(Change Data Capture)技术,实现了全量和增量的一体化读取能力,借助 Flink 优秀的管道能力和丰富的上下游生态,支持实时捕获、加工多种数据的变更并输出到下游,MongoDB 也是支持的数据库之一,支持的主要特性包括:
- 支持 Exactly-once 语义
- 支持全量、增量订阅
- 支持 Snapshot 数据过滤
- 支持从检查点、保存点恢复
- 支持元数据提取
社区 MongoDB CDC 使用了 MongoDB 3.6推出的 Change Streams特性,通过将 Change Streams 转换成 Flink Upsert changelog,实现了 MongoDB CDC TableSource。在 MongoDB 6.0 之前的版本中,默认不会提供变更前文档及被删除文档的数据,利用这些信息只能实现下图所示的 Upsert 语义。
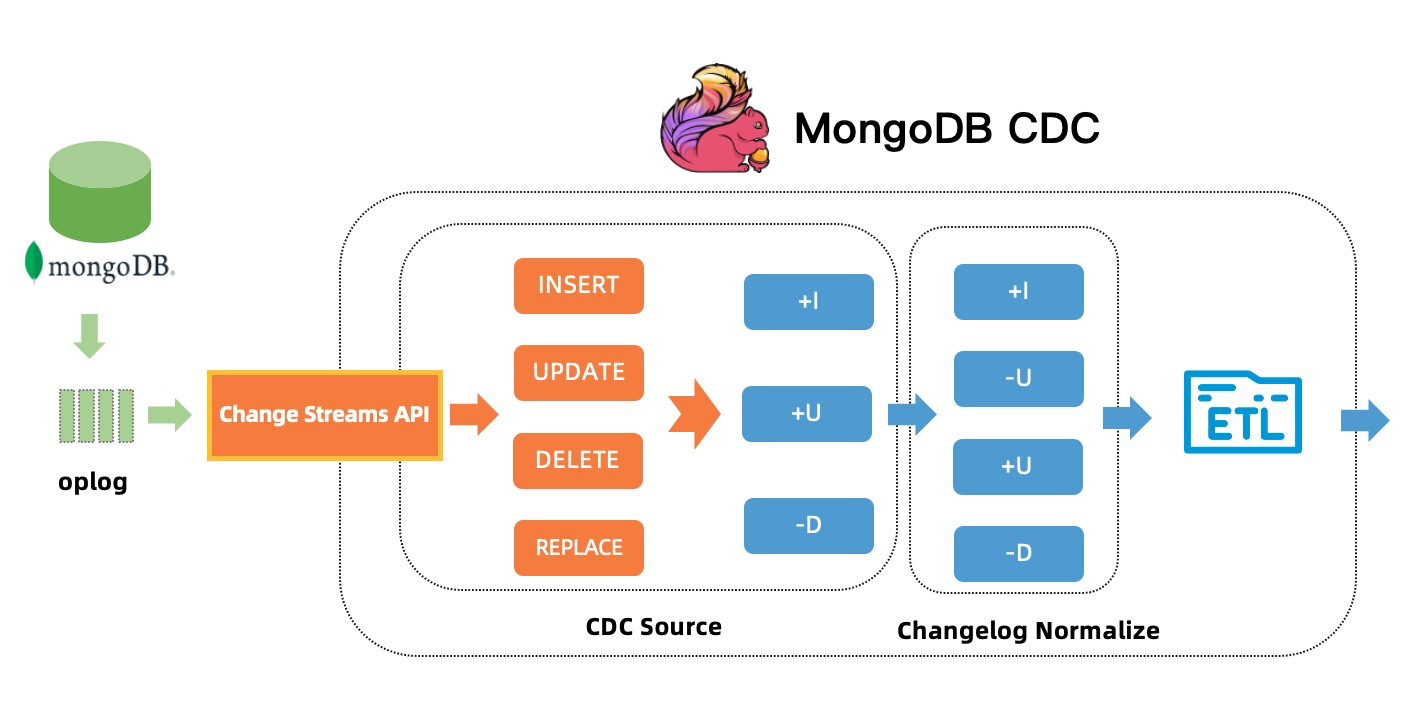
MongoDB 6.0 的 Pre- and Post-Image 新功能提供了一个更高效的解决方案:只要启用changeStreamPreAndPostImages功能,MongoDB 就会在每次变更发生时,在一个特殊的集合中记录文档变更前后的完整状态。MongoDB CDC 支持读取这些记录并产生完整事件流,从而消除了对 ChangelogNormalize 节点的依赖,该功能在社区和阿里云实时计算Flink产品中均可以支持。
三、MongoDB CDC 在阿里云 Flink 实时计算产品的实践
社区的 MongoDB CDC 作为纯引擎,功能已经十分强大。但作为商业化产品,目前仍然存在着不足之处,即无法支持 Schema 变更。
MongoDB 作为 NoSQL 数据库,没有固定的 Schema 要求,Schema 的变更操作十分常见,但目前社区 MongoDB CDC 只能支持固定 Schema,并且无法支持 Schema 变更。同时社区 MongoDB CDC 需要用户手动定义表的 Schema,在使用上也不够便捷。
为了解决上述不足之处,阿里云 Flink 实时计算产品提供了 MongoDB Catalog,支持 MongoDB 的 Schema 推导,无需手动定义 Schema。并且通过 CTAS/CDAS 语句,能够做到在实时同步 MongoDB 数据的同时将上游表结构(Schema)的变更同步到下游表,提高了建表和维护表结构变更的效率。
1.Schema 推导的实现
MongoDB Schema 推导通过 MongoDB Catalog 实现,MongoDB Catalog 会推导出 collection 的 schema,无需手动指定 DDL 即可作为 Flink 源表、维表或结果表使用。Schema 推导的流程包括以下步骤:
1.1 数据采样
MongoDB Catalog 会从 Collection 中采样默认 100 条文档数据,若 Collection 中文档数小于该值,则会获取其中的所有数据。
采样数据量可以通过 MongoDB Catalog 提供的配置项 max.fetch.records 进行设置。
1.2 Schema 解析
在 MongoDB 中,每个 Document 都是一个 BSON 文档。与 JSON 相比,BSON 类型是 JSON 类型的超集,相比 JSON 额外支持了 DateTime、Binary 等类型。在解析单个 BSON 文档的 Schema 时,BSON 类型会与 Flink SQL 类型进行一一对应。对于 BSON 文档中嵌套的 Document 类型,默认会将其解析为 STRING。
为了能够更好地解析嵌套的 Document 类型,MongoDB Catalog提供了 scan.flatten-nested-columns.enabled 配置项,可以用于递归地解析 Document 类型中的字段。假设初始的 BSON 文档如下:
{
"unnested": "value",
"nested": {
"col1": 99,
"col2": true
}
}
如果将 scan.flatten-nested-columns.enabled 设为 false(默认),得到的 Schema 会包含 2 列:
| 列名 | Flink SQL类型 |
|---|---|
| unnested | STRING |
| nested | STRING |
如果将 scan.flatten-nested-columns.enabled 设为 true,得到的 Schema 则会包含 3 列:
| 列名 | Flink SQL类型 |
|---|---|
| unnested | STRING |
| nested.col1 | INT |
| nested.col2 | BOOLEAN |
除此之外,MongoDB Catalog 还提供了 scan.primitive-as-string 配置项,可以将所有 BSON 基本类型都映射为 STRING。
1.3 Schema 合并
当获取到一组 BSON 文档数据后,MongoDB Catalog 会逐条解析 BSON 文档,并按如下规则合并解析出的物理列,最终得到的 Schema 会作为整个 Collection 的 Schema。合并规则如下:
-
如果当前 BSON 文档解析出的物理列中包含结果 Schema 中没有的字段,则 MongoDB Catalog 会自动将这些字段加入到结果 Schema。
-
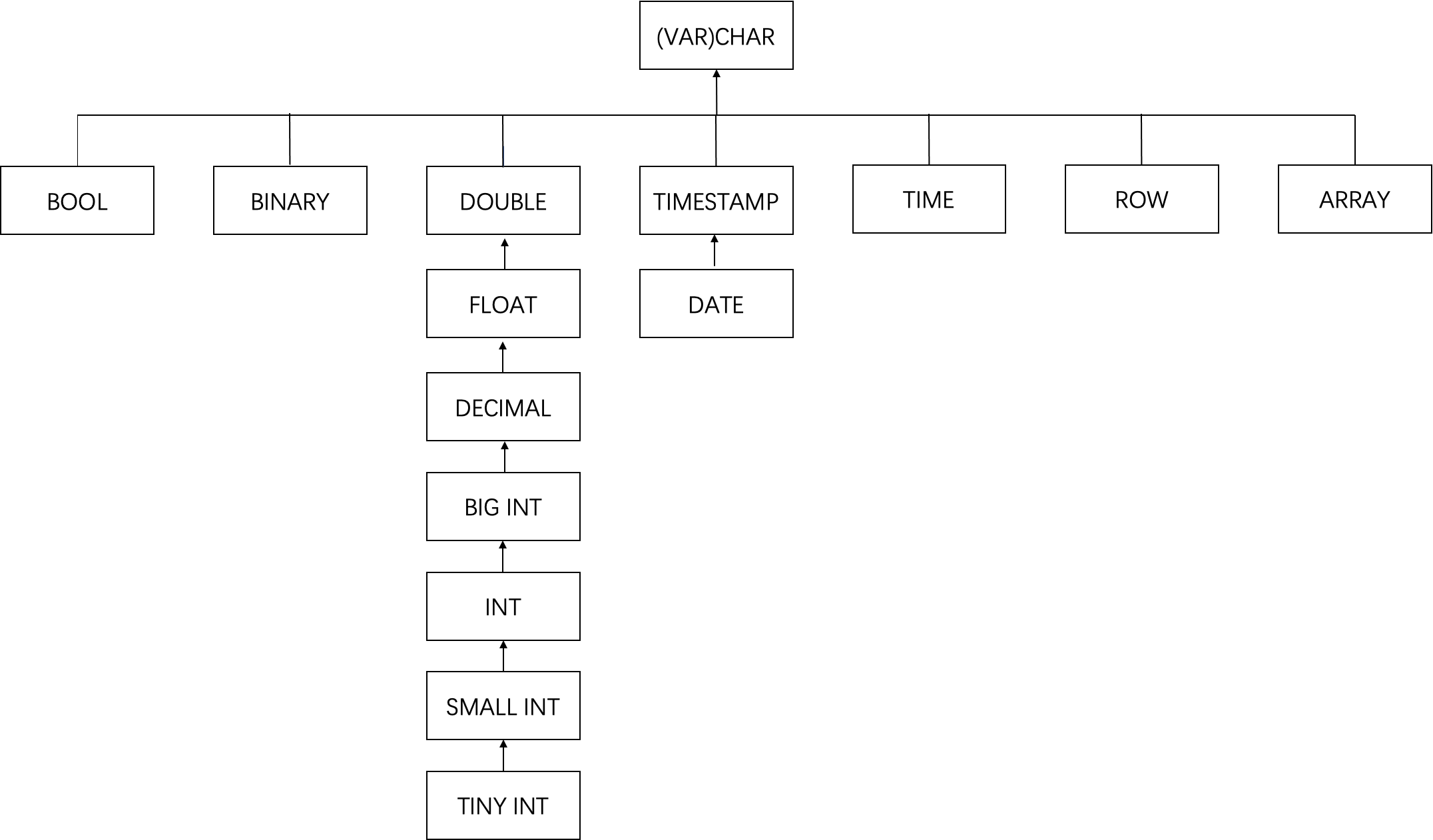
如果当前 BSON 文档解析出的物理列和结果 Schema 出现了同名列,若类型不同,则会按下图的树形结构找到最近公共父节点,作为该同名列的类型。
例如,对于包含如下三条数据的 Collection:
{
"_id": {
"$oid": "100000000000000000000101"
},
"name": "Alice",
"age": 10,
"phone": {
"mother": "111",
"fatehr": "222"
}
}
{
"_id": {
"$oid": "100000000000000000000102"
},
"name": "Bob",
"age": 20,
"phone": {
"mother": "333",
"fatehr": "444"
}
"address": ["Shanghai"],
"desc": 1024
}
{
"_id": {
"$oid": "100000000000000000000103"
},
"name": "John",
"age": 30,
"phone": {
"mother": "555",
"fatehr": "666"
}
"address": ["Shanghai"],
"desc": "test value"
}
对于以上 3 个 BSON 文档,后两个相比第一个多了 address 和 desc 字段,这两个字段在做 Schema 合并时会合并到最终 Schema 中。后两个文档的 desc 字段类型不同,在解析单个文档的 Schema 时,会将这两个字段分别映射为 Flink SQL 类型的 INT 和 STRING,根据上述 Schema 合并时类型合并规则,最终 desc 字段类型会被推导为 STRING。
因此,MongoDB Catalog 最终得到的 Schema 如下:
| 列名 | Flink SQL类型 | 备注 |
|---|---|---|
| _id | STRING NOT NULL | 主键字段 |
| name | STRING | |
| age | INT | |
| phone | STRING | |
| address | STRING | |
| desc | STRING | 类型合并为STRING |
在 MongoDB 中,每个文档都有一个特殊的字段 _id,它用于唯一标识集合(collection)中的一个文档,这个字段在文档创建时会自动生成。
MongoDB Catalog 会把 _id 列作为主键,添加默认的主键约束,确保数据不会重复。
2. Schema Evolution 的实现
在将 MongoDB Catalog 中的表作为 CDC source 使用时,考虑到 Collection 中的数据可能会出现新增字段、更改字段类型等 Schema 变更操作,connector 在处理数据时需要考虑到 Schema evolution。
MongoDB CDC connector 会将 MongoDB Catalog 推导出的 Schema 作为初始 Schema,后续在每读到一条 OpLog 操作日志数据时,操作步骤如下:
- 解析当前数据对应 BSON 文档的 Schema,步骤与上文 BSON 文档 Schema 解析中相同
- 将步骤 1 中解析出的 Schema 与当前 Schema 合并
- 比较步骤 2 中合并后的 Schema 与当前 Schema:
- 若相同,则使用当前 Schema 解析数据
- 若不同,则更新当前 Schema,并下发 Schema 变更信息
3. 通过 CTAS/CDAS 语句同步数据和表结构
CTAS 语句支持同步源表的全量和增量数据到结果表中,在同步数据的同时,能够将源表的表结构变更也实时同步到结果表。CDAS 语句支持整库级别的数据实时同步,也能够支持表结构变更的同步。
在使用 CTAS/CDAS 语句同步数据之前,需要先创建 MongoDB Catalog:
CREATE CATALOG <yourcatalogname> WITH(
'type'='mongodb',
'default-database'='<dbName>',
'hosts'='<hosts>',
'scheme'='<scheme>',
'username'='<username>',
'password'='<password>',
'connection.options'='<connectionOptions>',
'max.fetch.records'='100',
'scan.flatten-nested-columns.enable'='<flattenNestedColumns>',
'scan.primitive-as-string'='<primitiveAsString>'
);
示例如下:
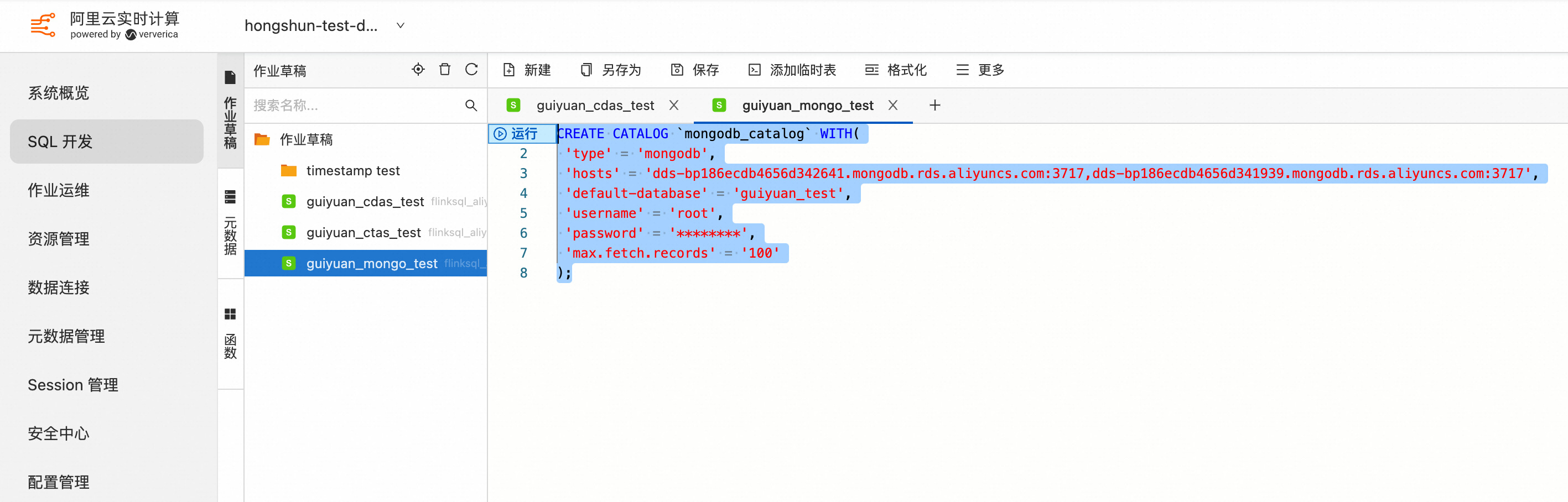
在创建 MongoDB Catalog 后,可以选择如下几种方式实现数据和表结构的同步:
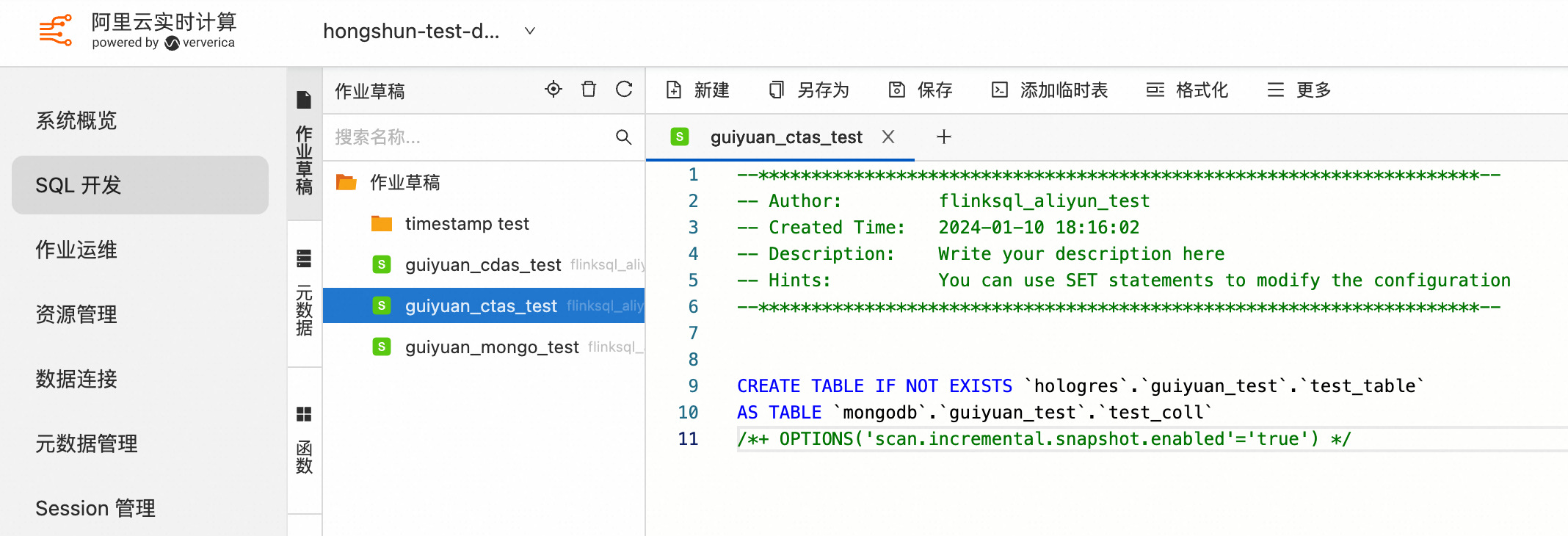
3.1 使用 CTAS 语句同步单个 MongoDB Collection 数据和表结构到下游存储
CREATE TABLE IF NOT EXISTS `${target_table_name}`
WITH(...)
AS TABLE `${mongodb_catalog}`.`${db_name}`.`${collection_name}`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true') */;
示例如下:
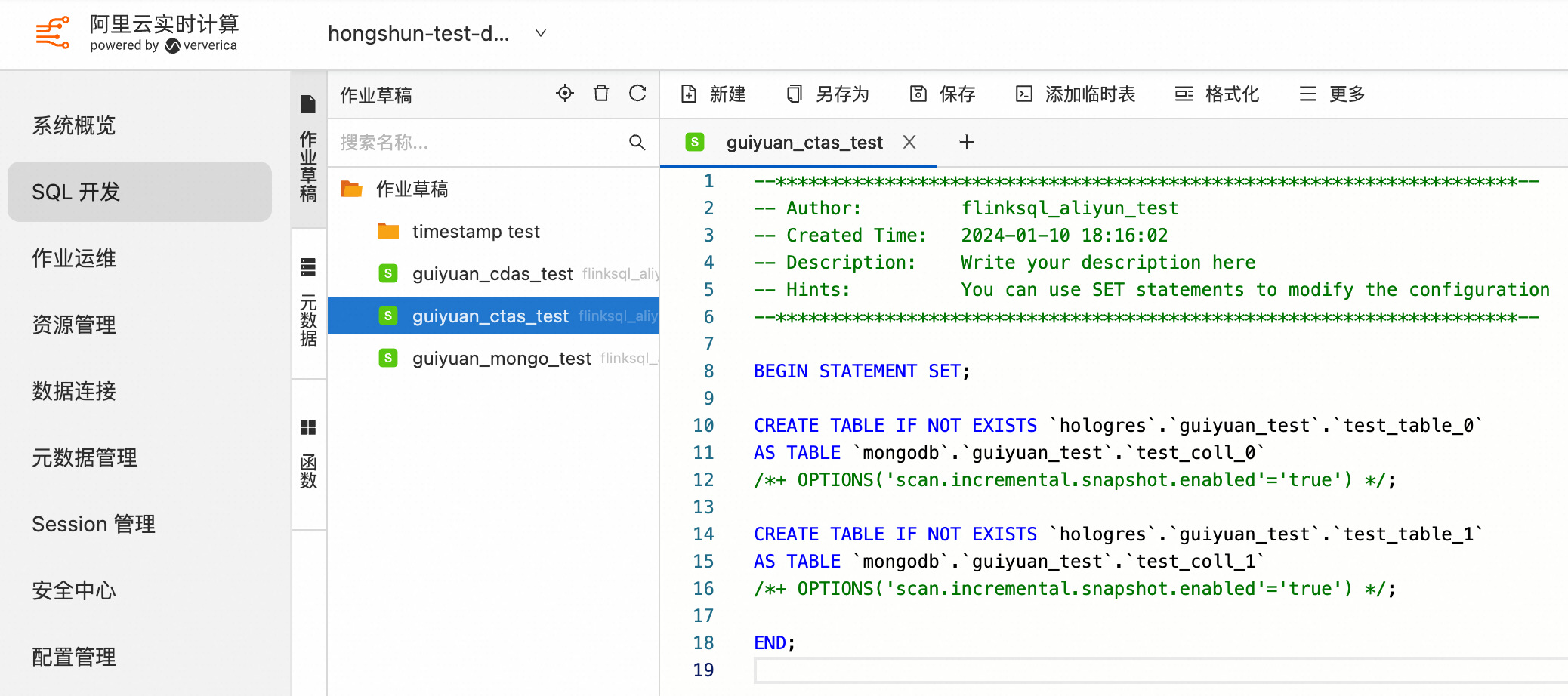
3.2 使用多个 CTAS 语句同时同步多个 MongoDB Collection 数据和表结构到下游存储
BEGIN STATEMENT SET;
CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table0`
AS TABLE `mongodb-catalog`.`database`.`collection0`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true') */;
CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table1`
AS TABLE `mongodb-catalog`.`database`.`collection1`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true') */;
CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table2`
AS TABLE `mongodb-catalog`.`database`.`collection2`
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true') */;
END;
示例如下:
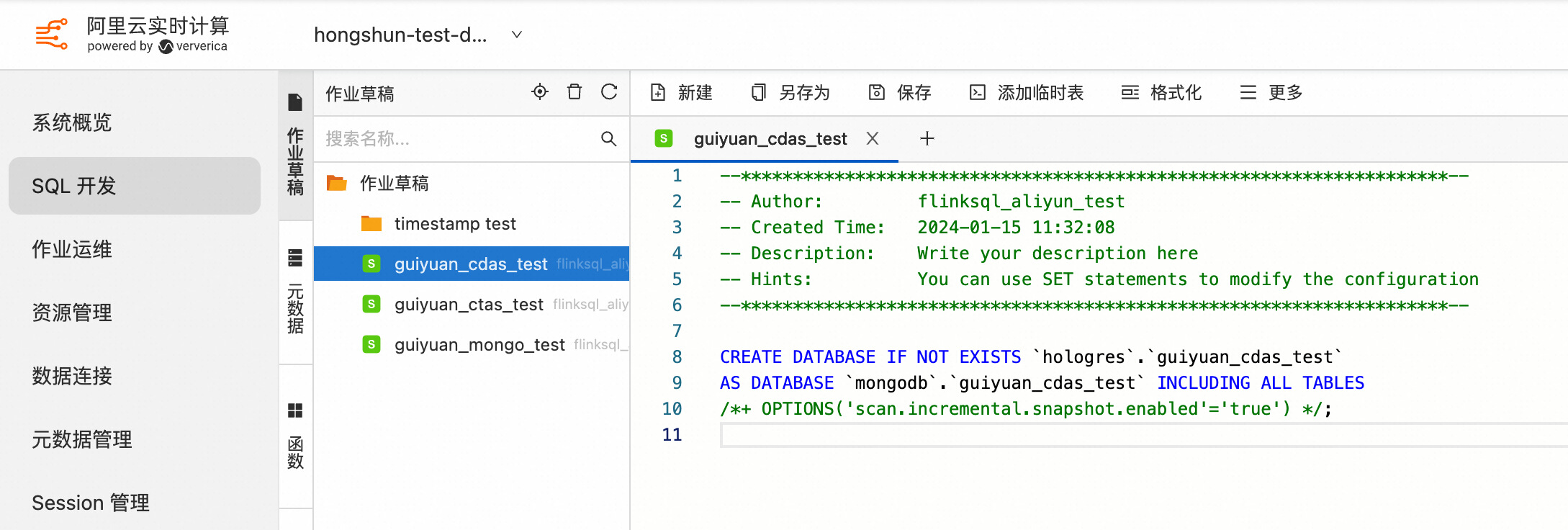
3.3 使用 CDAS 同步 MongoDB 数据库中符合条件的 Collection 数据和表结构到下游存储
CREATE DATABASE IF NOT EXISTS `some_catalog`.`some_database`
AS DATABASE `mongo-catalog`.`database` INCLUDING TABLE 'table-name'
/*+ OPTIONS('scan.incremental.snapshot.enabled'='true') */;
示例如下:
4. 使用示例
(以下示例使用的环境为阿里云实时计算 Flink 版)
假设我们需要同步 MongoDB 中单个数据库下所有 Collection 的数据和表结构到 Hologres,MongoDB 中数据可能出现新增字段。
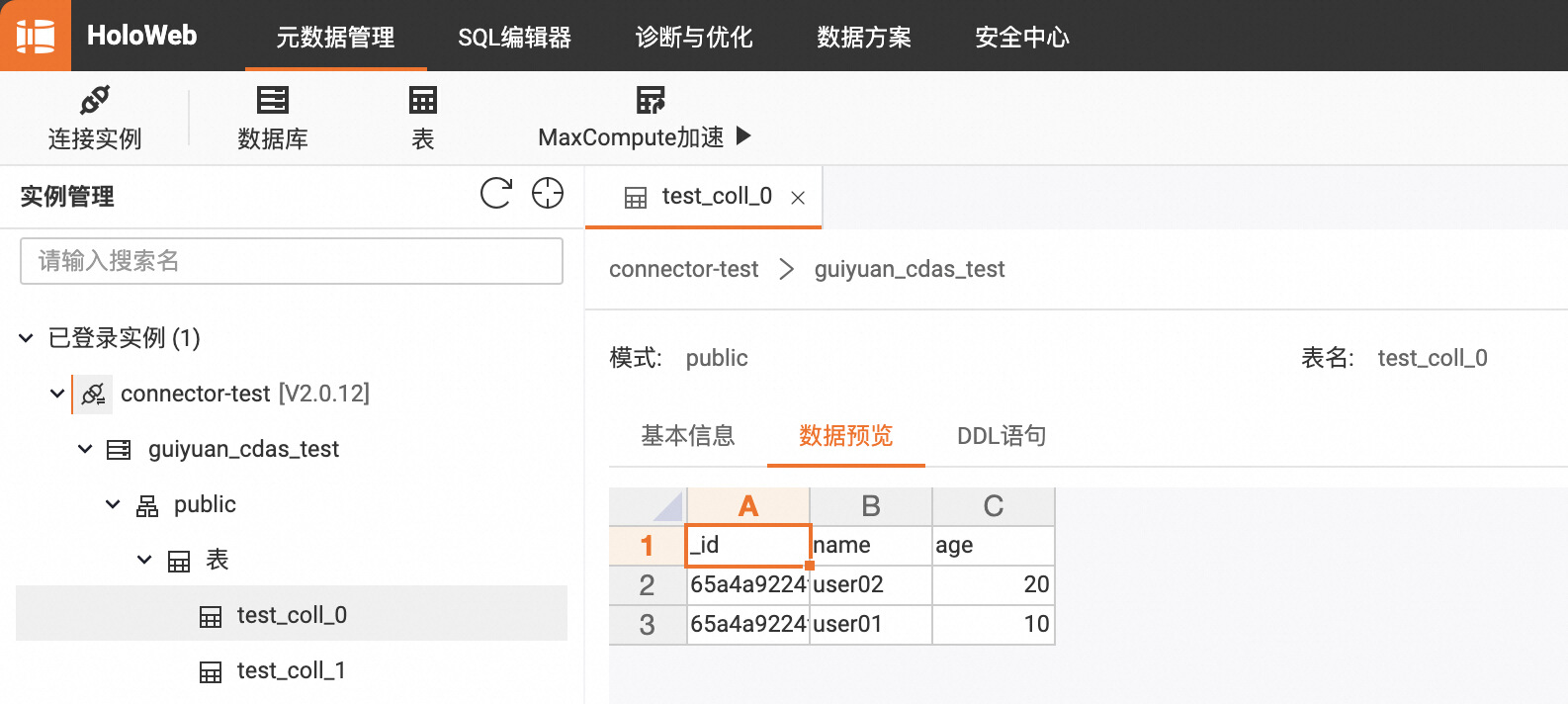
MongoDB 的数据库名称为 guiyuan_cdas_test,其中包含了两个 collection,名称分别为 test_coll_0 和 test_coll_1,我们希望将数据同步到 Hologres 的同名数据库 cdas_test 中。
MongoDB 中两个 collection 的初始数据如下:


创建 MongoDB 和 Hologres 的 Catalog 后,在 SQL 开发页面编写 CDAS 作业,由于 MongoDB Catalog 会对 collection 做 Schema 推导,此处不需要手动定义表的 DDL:
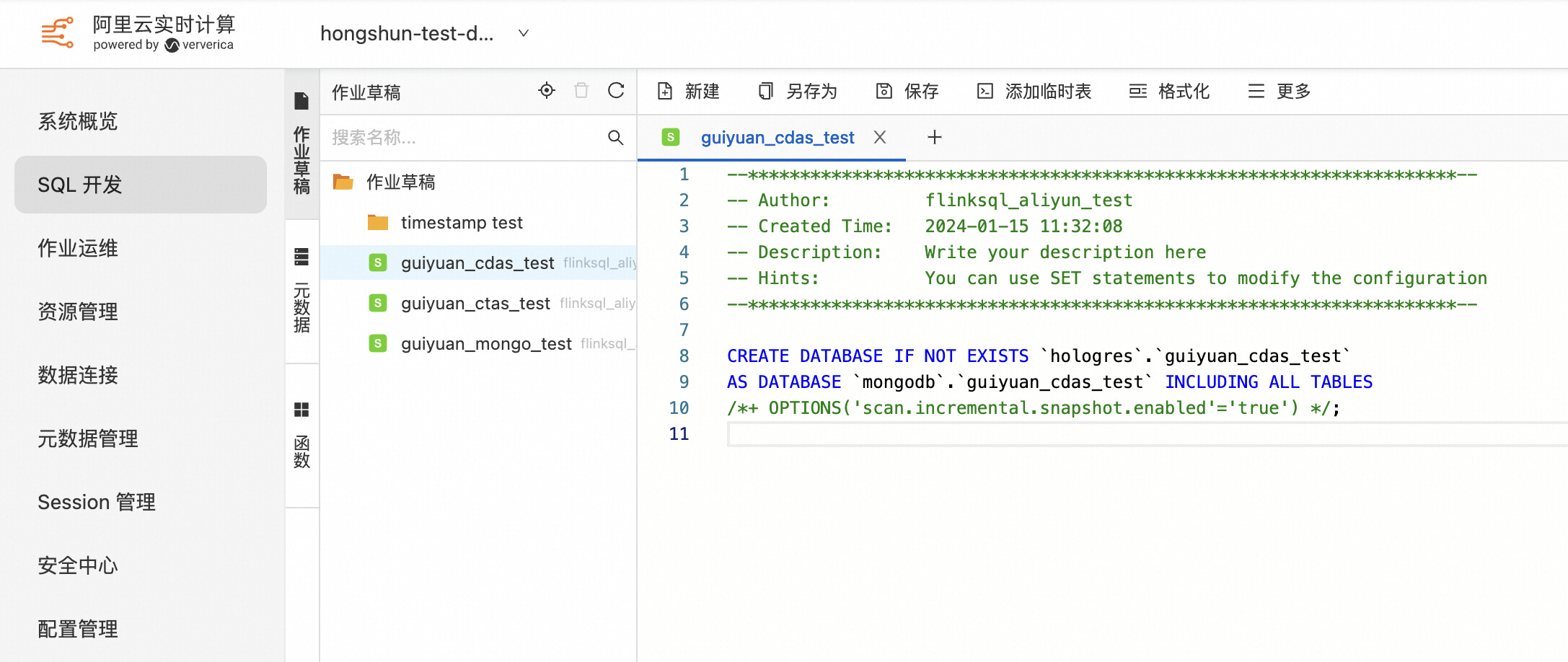
部署运行后,可以看到 Hologres 数据库中已经自动创建了 guiyuan_cdas_test 数据库,并且同步了两个表的初始数据:
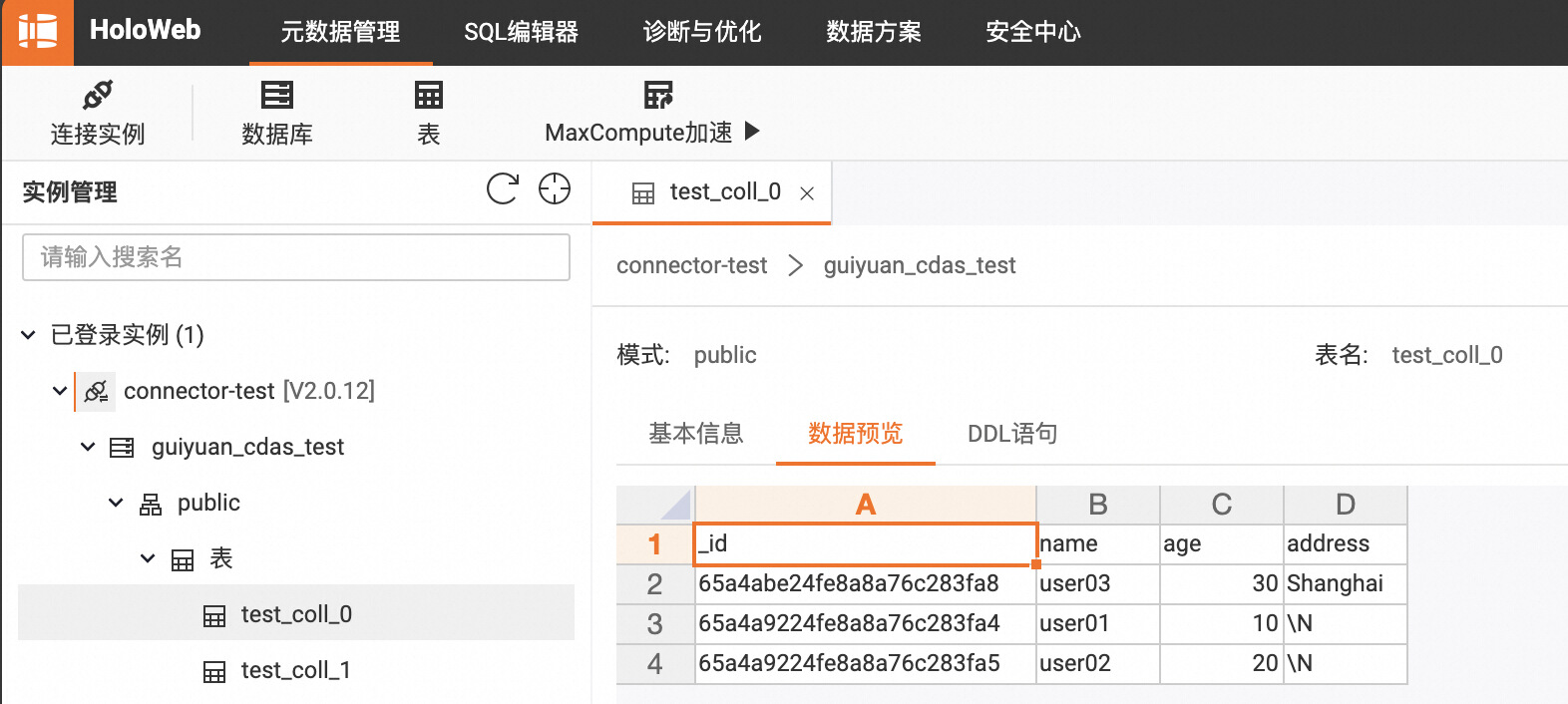
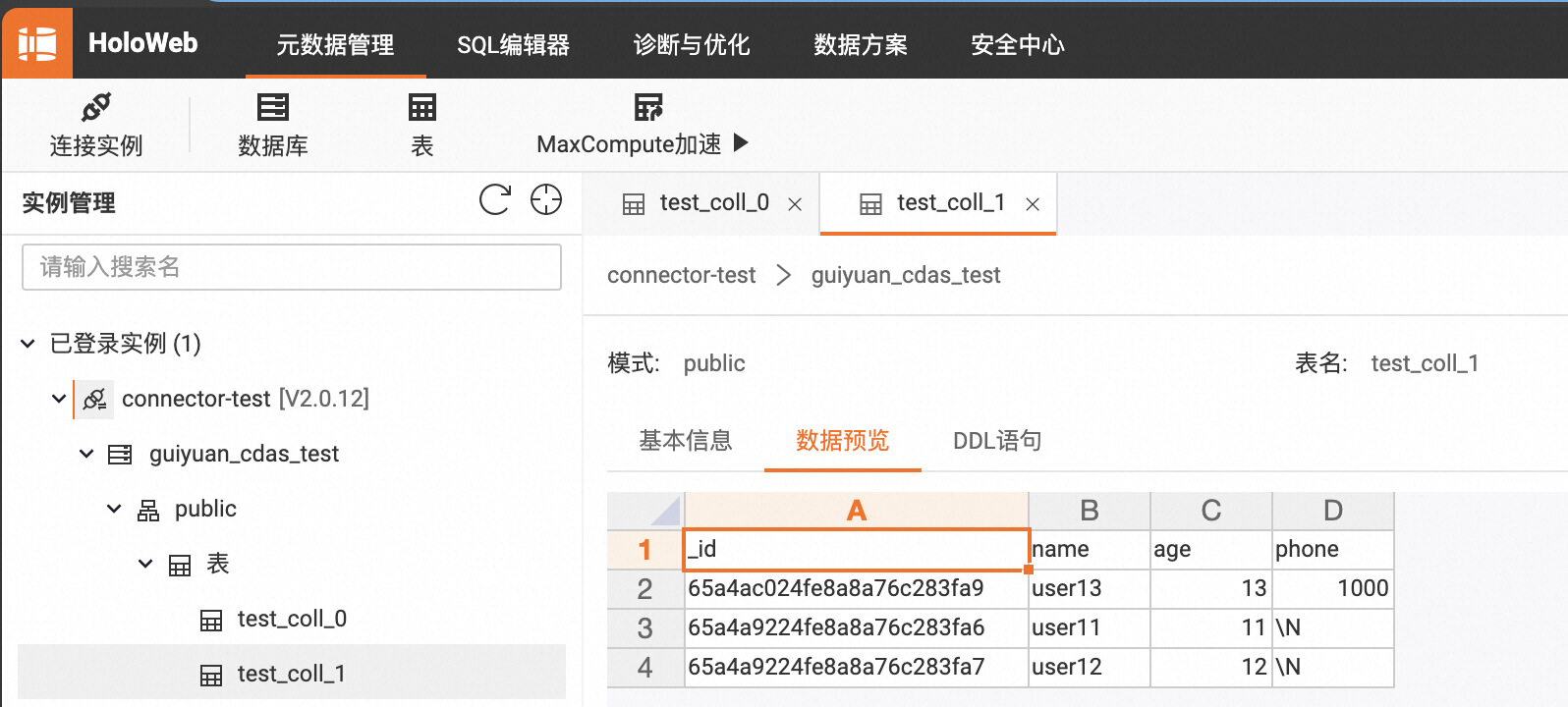
此时,向 MongoDB 的 test_coll_0 中插入一条包含了新字段 address 的数据,同时向 test_coll_1 中插入一条包含了新字段 phone 的数据。

此时观察 Hologres 表,可以看到两个表都已经同步了新的数据和表结构:
四. 总结
Flink CDC 基于 MongoDB 的 Change Streams 实现了 MongoDB CDC Source,支持了 MongoDB 的全增量一体化数据同步。在此基础上,阿里云实时计算 Flink 通过 MongoDB Catalog 实现了 MongoDB Schema 推导,配合 CTAS/CDAS 语句,可以在同步数据的同时支持表结构变更的同步,当 Schema 发生变更时,无需修改 Flink 作业即可同步到下游存储,极大地提升了数据集成的灵活性和便利性。
原文地址:https://blog.csdn.net/weixin_44904816/article/details/135836967
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_62175.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!