本文介绍: 本文整理自阿里云 Flink 团队归源老师关于阿里云 Flink 原理分析与应用:深入探索 MongoDB Schema Inference 的研究。
一、MongoDB 简介
MongoDB 是一种面向文档的非关系型数据库,支持半结构化数据存储;也是一种分布式的数据库,提供副本集和分片集两种集群部署模式,具有高可用和水平扩展的能力,比较适合大规模的数据存储。
MongoDB 使用了弱结构化的存储模式,支持灵活的数据结构和丰富的数据类型,适合 Json 文档、标签、快照、地理位置、内容存储等业务场景。它天然的分布式架构提供了开箱即用的分片机制和自动 rebalance 能力,适合大规模数据存储。另外, MongoDB 还提供了分布式网格文件存储的功能,即 GridFS,适合图片、音频、视频等大文件存储。

二、社区 MongoDB CDC 核心特性
Flink CDC 是基于数据库的日志 CDC(Change Data Capture)技术,实现了全量和增量的一体化读取能力,借助 Flink 优秀的管道能力和丰富的上下游生态,支持实时捕获、加工多种数据的变更并输出到下游,MongoDB 也是支持的数据库之一,支持的主要特性包括:
社区 MongoDB CDC 使用了 MongoDB 3.6推出的 Change Streams特性,通过将 Change Streams 转换成 Flink Upsert changelog,实现了 MongoDB CDC TableSource。在 MongoDB 6.0 之前的版本中,默认不会提供变更前文档及被删除文档的数据,利用这些信息只能实现下图所示的 Upsert 语义。
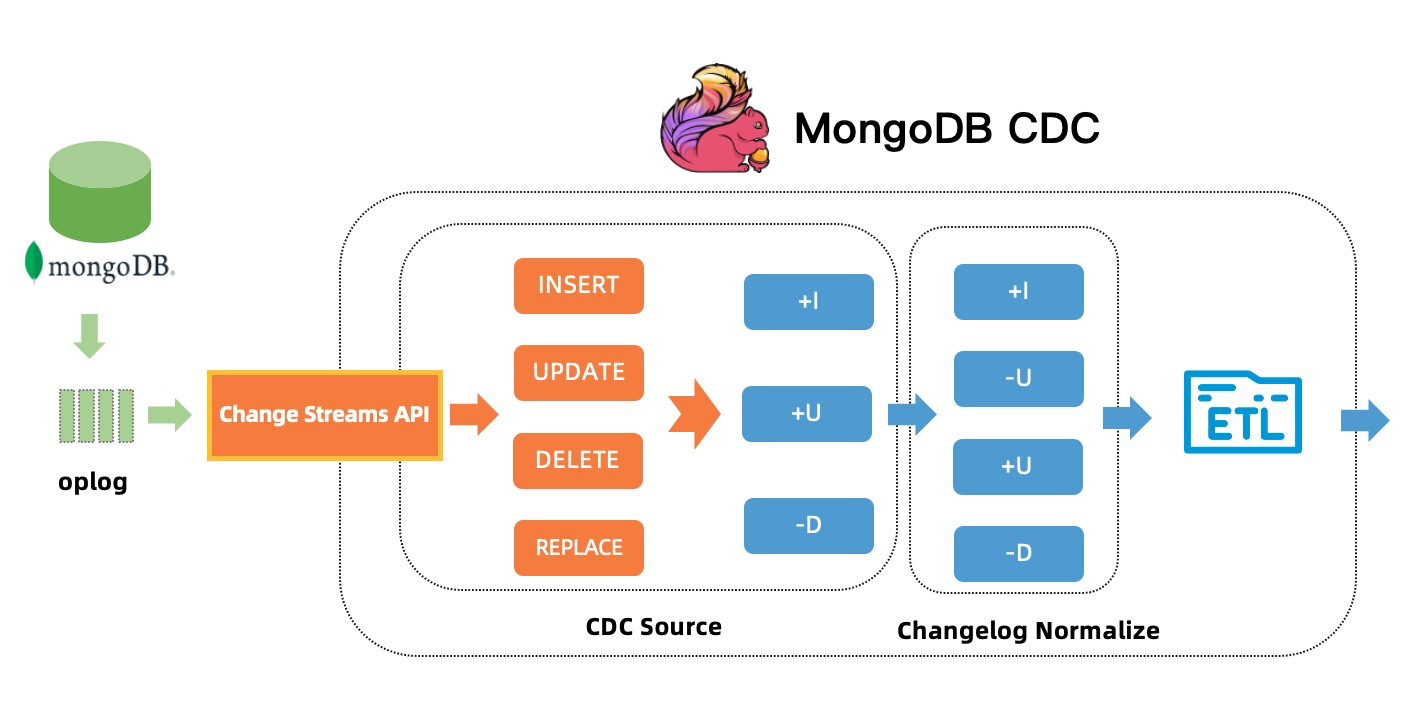
三、MongoDB CDC 在阿里云 Flink 实时计算产品的实践
1.Schema 推导的实现
1.1 数据采样
1.2 Schema 解析
1.3 Schema 合并
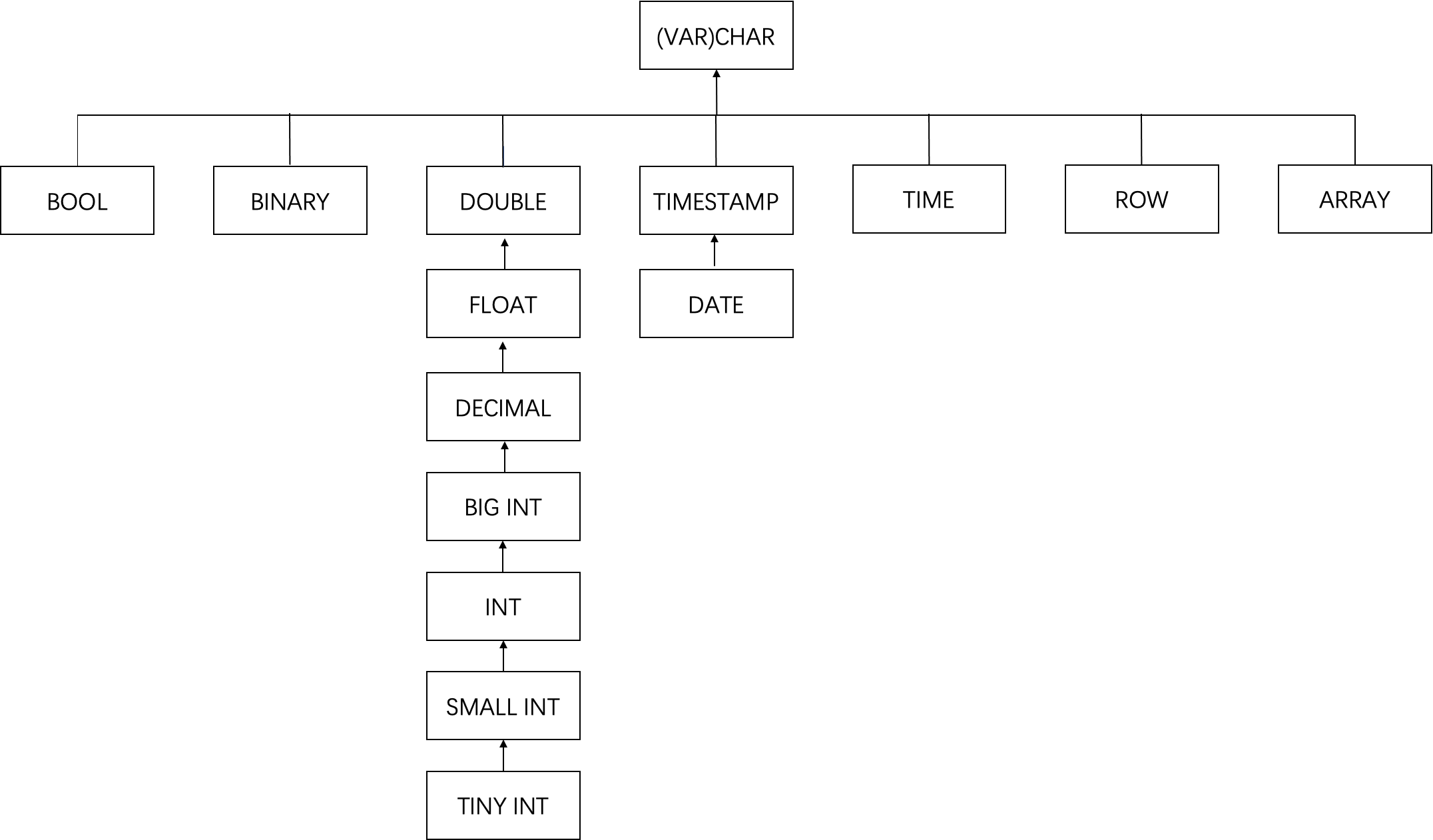
2. Schema Evolution 的实现
3. 通过 CTAS/CDAS 语句同步数据和表结构
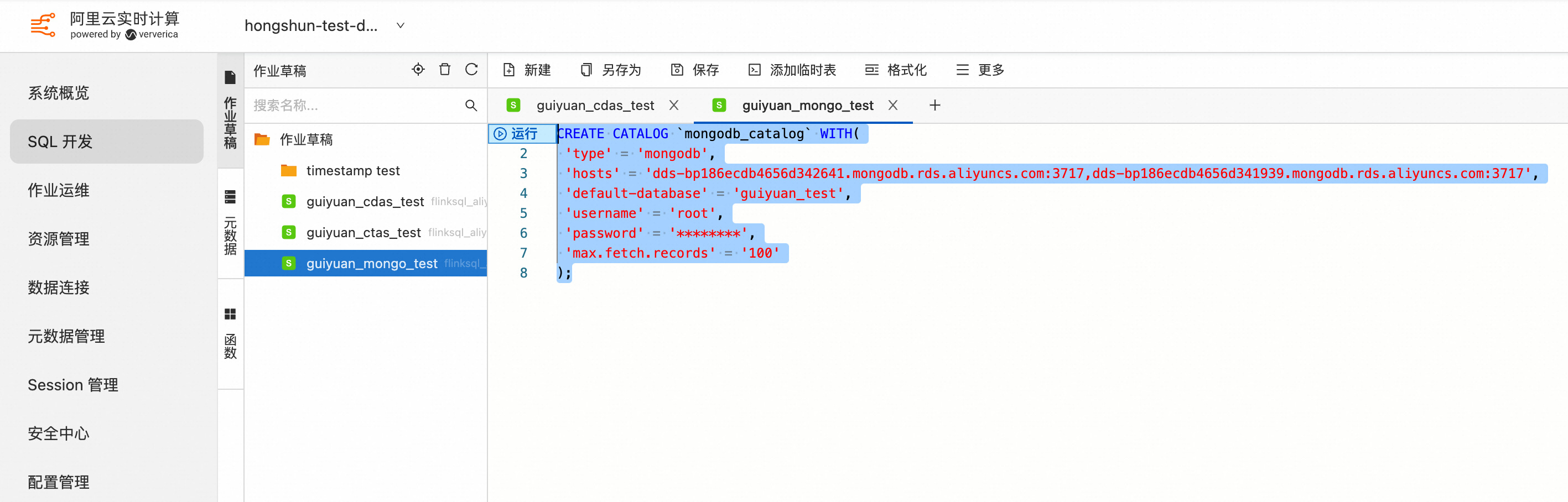
3.1 使用 CTAS 语句同步单个 MongoDB Collection 数据和表结构到下游存储
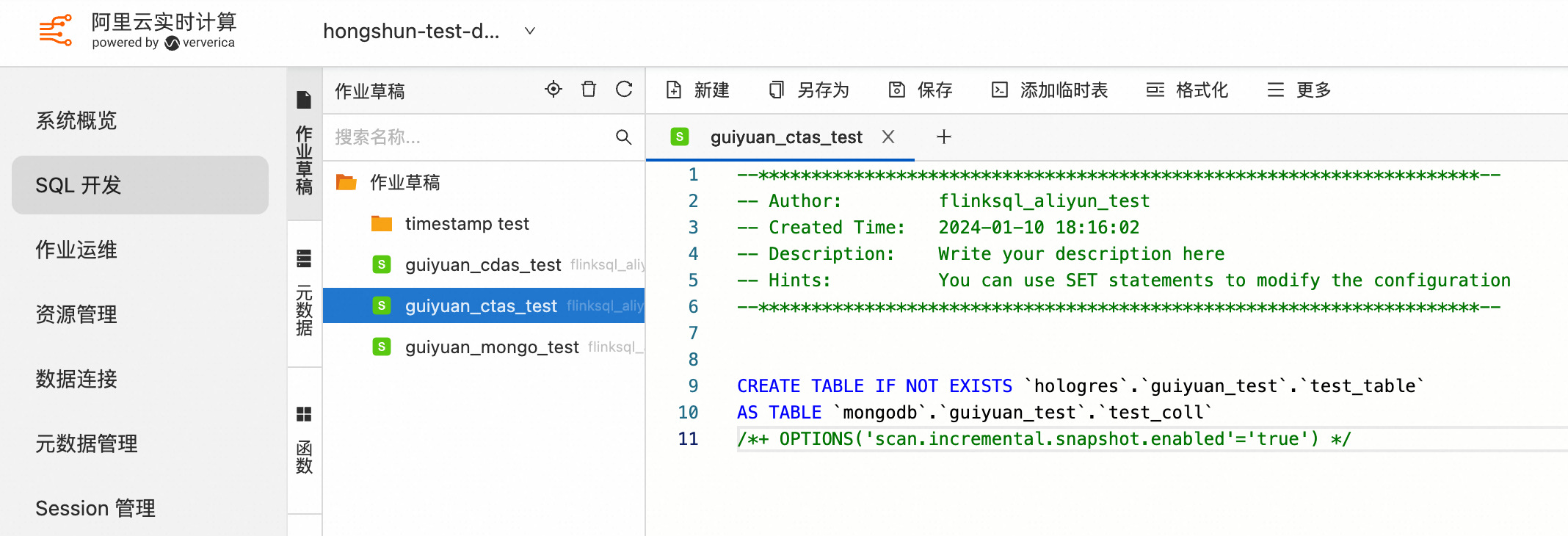
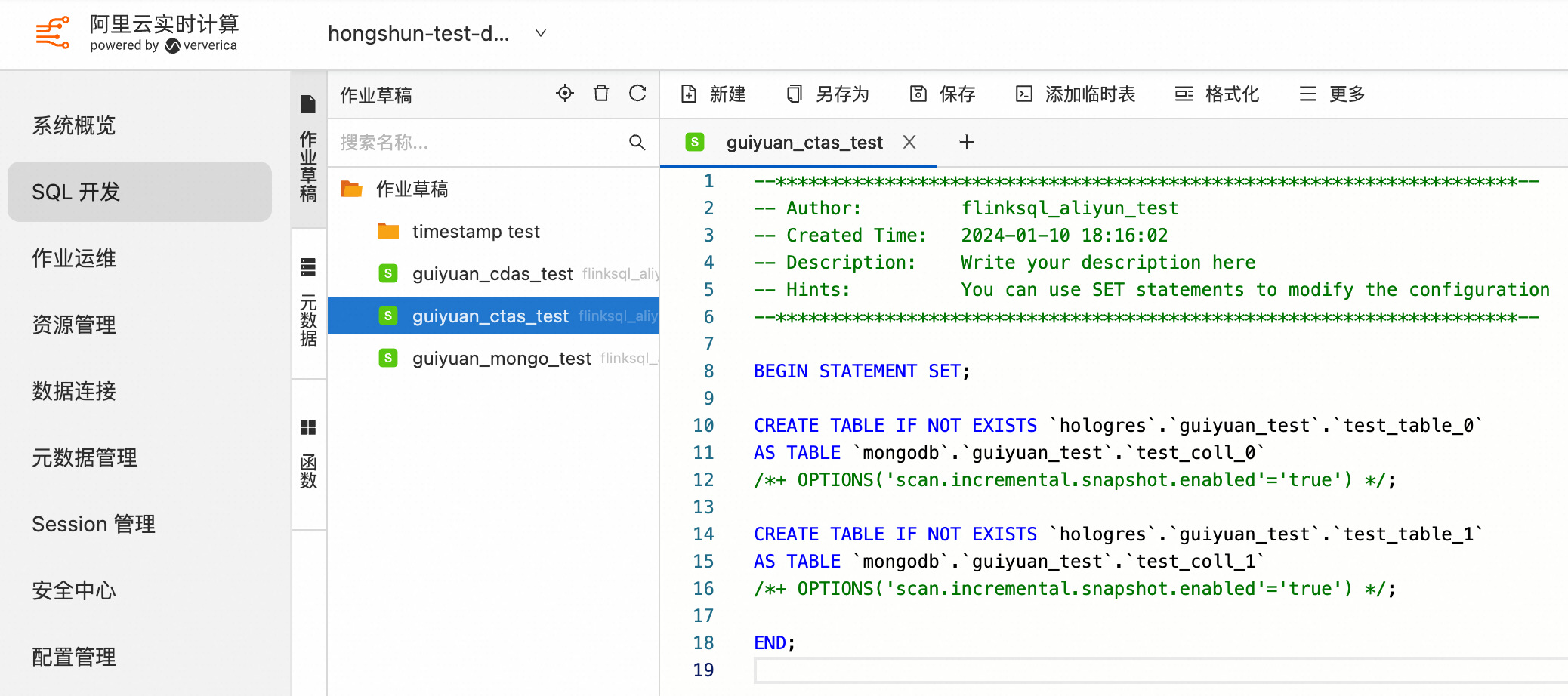
3.2 使用多个 CTAS 语句同时同步多个 MongoDB Collection 数据和表结构到下游存储
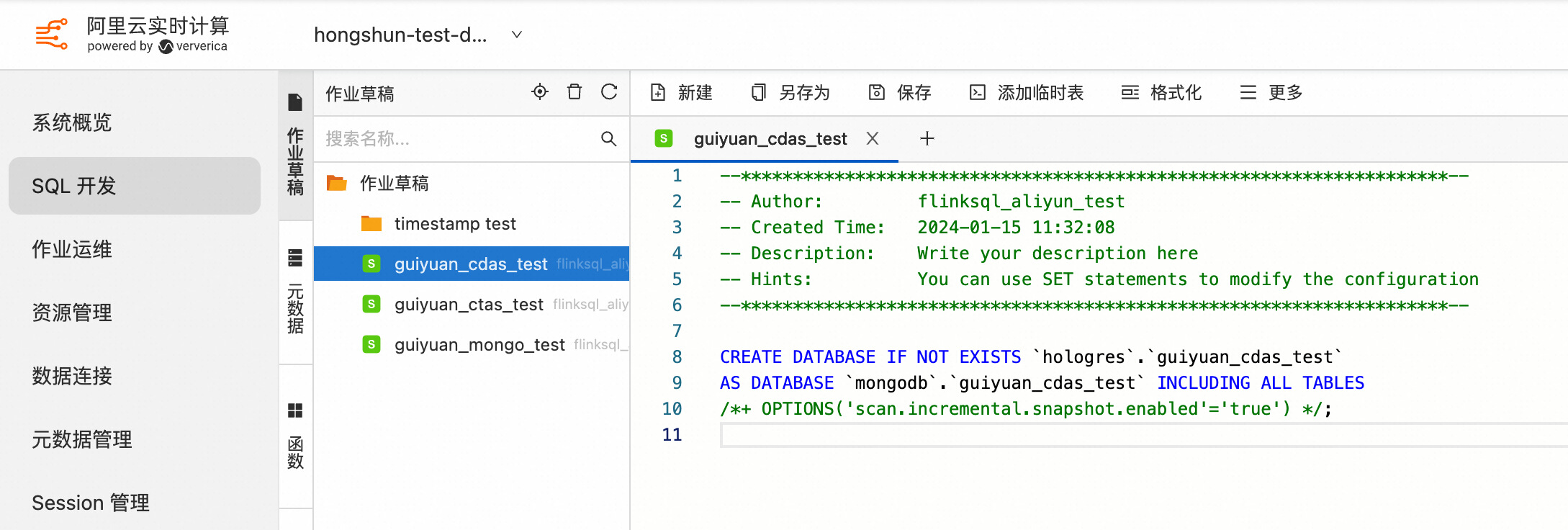
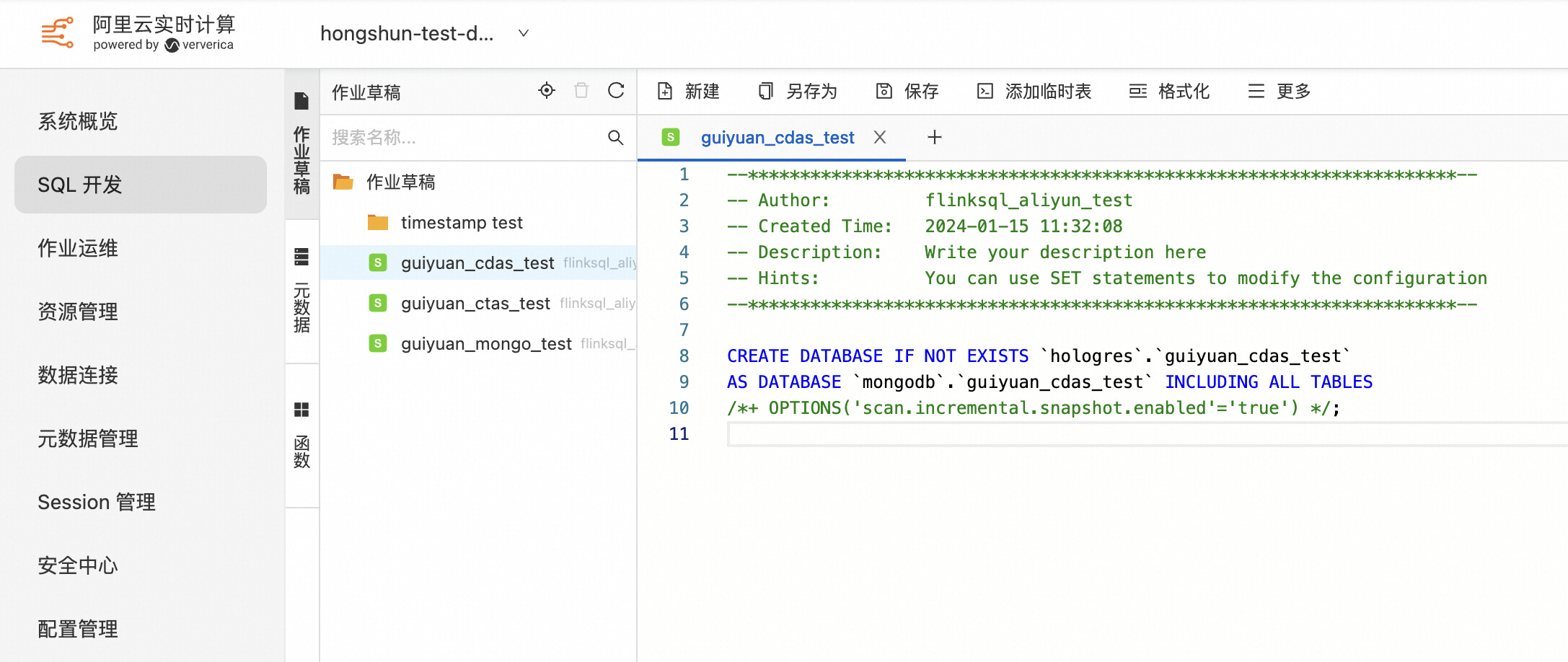
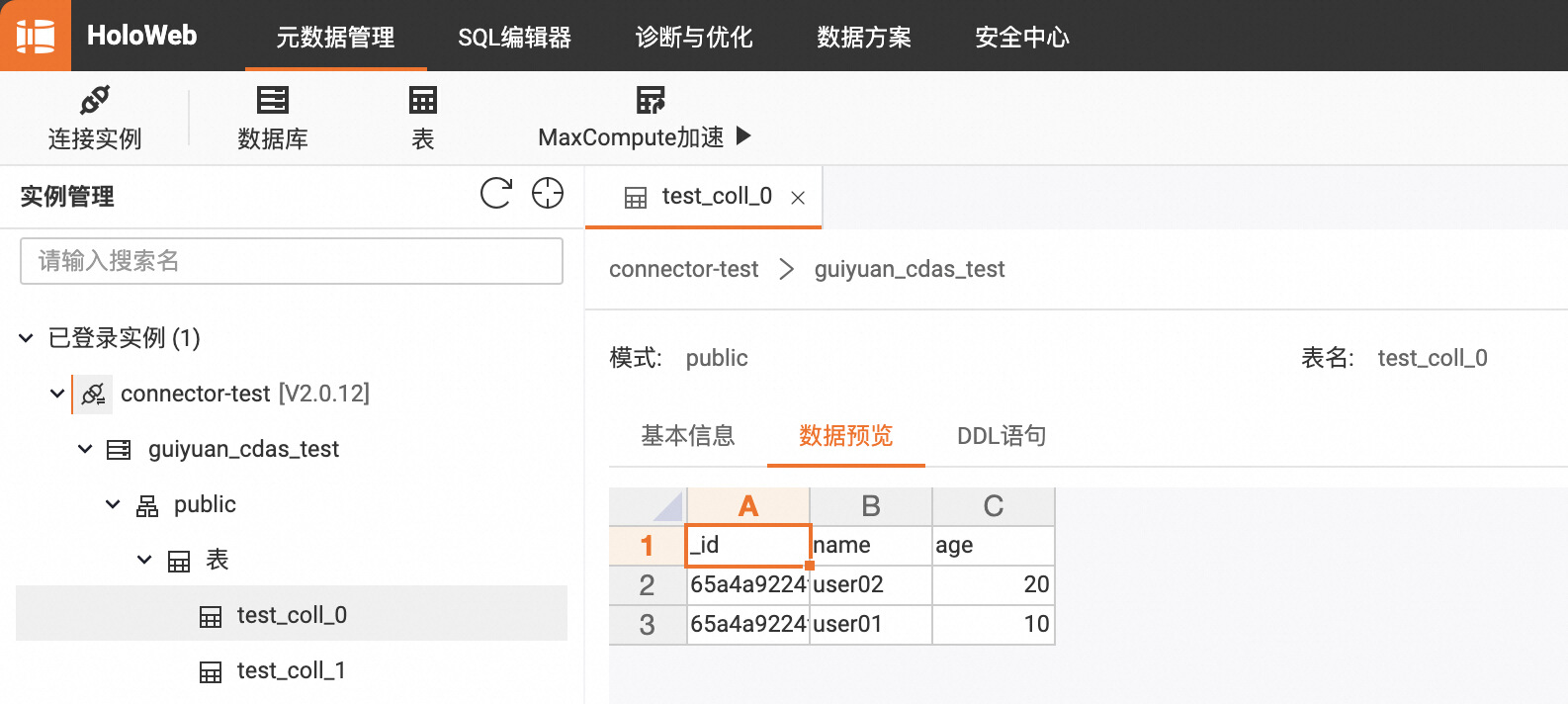
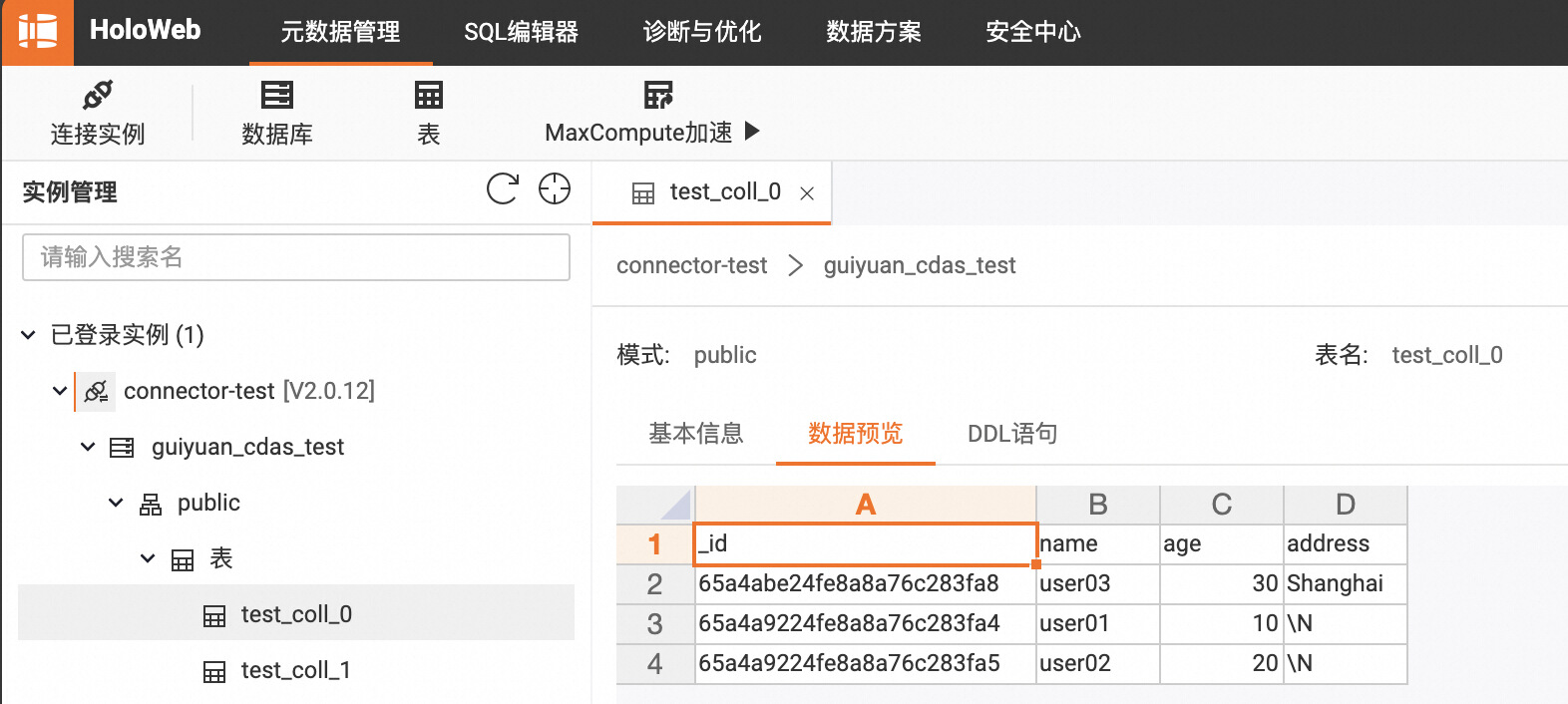
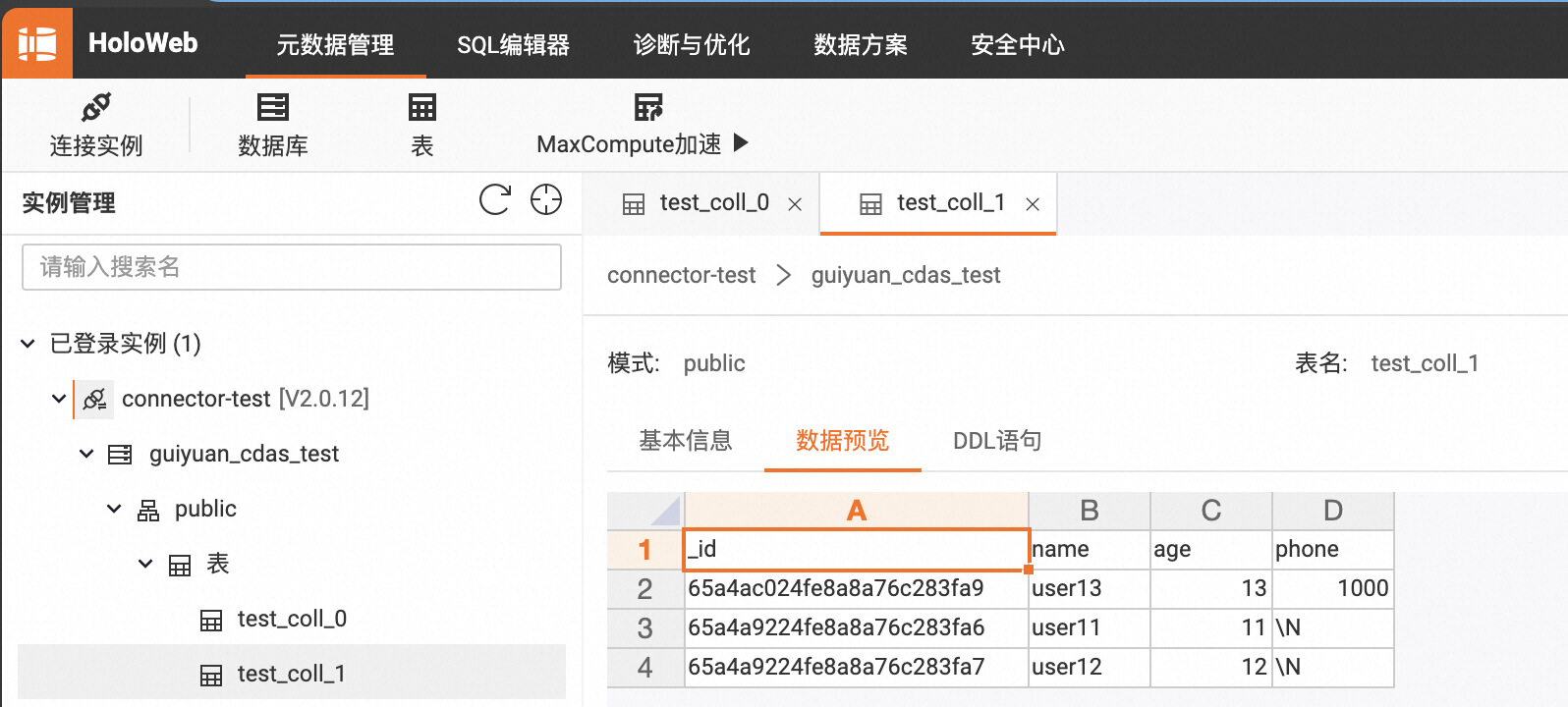
3.3 使用 CDAS 同步 MongoDB 数据库中符合条件的 Collection 数据和表结构到下游存储
4. 使用示例



四. 总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。