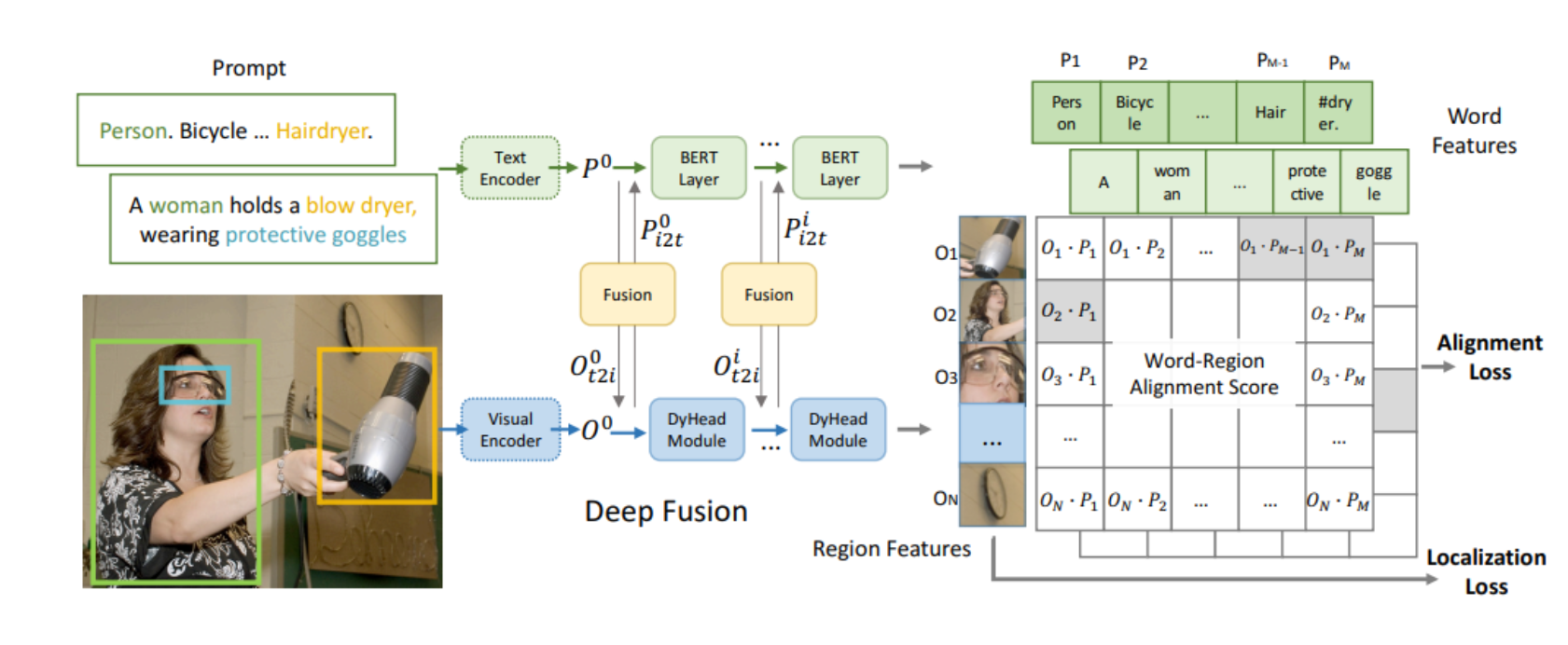
论文:《InstructDiffusion: A Generalist Modeling Interface for Vision Tasks》
github:https://github.com/cientgu/InstructDiffusion
InstructPix2Pix:参考
摘要
作者提出InstructDiffusion,一个统一通用框架用于对齐cv任务与instruction,将不同视觉任务映射为人工引导的图像处理任务。InstructDiffusion可处理各种视觉任务,包括理解任务(分割、关键点检测)、生成类任务(编辑和增强)。InstructDiffusion迈向视觉任务通用模型接口重要一步。
引言
难点:
1、计算机视觉任务的多样性使得其很难找到一个适用于所有任务的统一的表征;
2、不同的任务需要不同的方法,作为对比,NLP任务基于更一致的方法;
3、视觉任务输入输出是连续性的,通过VQ-VAE量化时容易产生量化误差;
本文中作者利用DDPM优势,提出一种新方法将所有视觉任务看做图像生成,解决所提到挑战。
输出格式有三种:RGB图、二进制图、关键点;
算法
作者提出InstructDiffusion,一种通用模型接口适用于各种视觉任务。利用DDPM,将所有视觉任务看做人类引导的图像处理过程,输出在一个灵活和交互的像素空间。
输出为三种格式:3通道RGB图、二进制mask、关键点
视觉任务统一引导
训练集
i
x_i
c
i
,
s
i
,
t
i
{c_i, s_i, t_i}
ci,si,ti,其中
c
i
c_i
s
i
s_i
si和
t
i
t_i
ti分别表示原图和目标图。Instruct-Pix2Pix天然符合该任务;
关键点检测:作者使用更自然详细指令用于关键点检测,比如:”Please use red to encircle the left shoulder of the man.”,仅在输出图中对应位置展示红圈;
分割:识别特定目标区域,instruction实例”apply a blue semi-transparent mask to the rightmost dog while maintaining the remainder un- altered.” 变透明mask更利于评估同时增强分割效果;
图像增强与图像编辑:构建instruction应该明确说明要执行的功能,比如:“Make the image much sharper”、“Please remove the watermark on the image”、“add an apple in the woman’s hand”
为了增加instruction的多样性,作者首先对每个 任务写10个instruction,然后使用GPT-4重写并扩展多样性,
训练集重构
作者使用开源数据集,依据instruction重构目标图;InstructPix2Pix利用GPT-3生成instruction,Prompt2Prompt创建目标图;MagicBrush数据集有1万张人工标注的三元组样本,作者提出了IEIW,包括159000样本对,涵盖多种实体及分割粒度。
作者从以下三个源收集IEIW数据集:
目标移除:作者对PhraseCut数据集提供图片及对应短语,使用LAMA进行目标移除;同时翻转instruction及输入、输出图进行数据集扩充。
目标替换:作者提出一种生成训练集(特定目标替换)流程。作者使用SA-1B及Open-Images数据集,首先基于分割区域构建目标数据库,选择一个语义区域,从数据库中搜索最相似目标作为参考图,通过PaintByExample生成目标图,为了获得instruction,作者使用图像caption工具生成原图及目标图caption,通过LLM生成instruction。
网络爬虫:通过google关键词”photoshop request”,搜索P图人员修过的的图,共2.3万成对数据。
为保证训练集质量,作者进行质量评估。具体地,使用LAION-Aesthetics-Predictor进行美学评分,在LAION-600M数据集构建KNN-GIQA模型进行GIQA评分。作者剔除低质量得分数据、源图与目标图质量得分差异大的数据。
统一框架
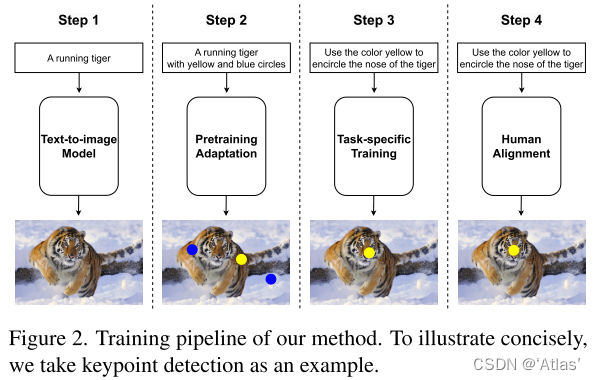
如图2,训练过程包括三个阶段:自适应预训练、特定任务训练、instruction调优。
自适应预训练
作者希望扩散模型可生成图像具有特定前景mask或者特别mark,因此使用现有的分割或关键点数据集产生这样的数据,主要挑战在于在保留文生图能力的同时,形成合适caption准确描述这些图像,通过对原始图像caption增加后缀实现,比如:”with a few different color patches here and there” or ”surrounded with a red circle.”
特定任务训练
第二阶段进一步finetune扩散模型,强化其理解不同任务各种instruction能力。对于不同任务所使用训练样本如表1。

扩散过程增加噪声
z
t
z_t
zt,微调模型,如式1,
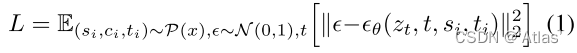
人工对齐
对于每个样本我们生成20个不同的编辑结果,人工挑选最好的0-2个编辑结果用作instruction微调数据集。整个数据集包括1k张图。
实验
训练集
关键点:COCO,149k,17个关键点;CrowdPose,35k,14个关键点;MPII,22k,16个关键点;AIC,378k,14个关键点;
分割:COCO-Stuff作为分割训练集、gRefCOCO和RefCOCO作为引用分割训练集;instruction使用固定模板:“place a color mask on object.”
图像增强:关注三个任务:
图像编辑:InstructPix2Pix,561k个样本;MagicBrush,8k个样本;GIER,5k;GQA,131k修复数据集;VGPhraseCut,85k样本;作者生成51k样本;
训练细节
训练集955k、batch 3072、200epoch、48 v100、分辨率 256*256,训练4天。
关键点检测
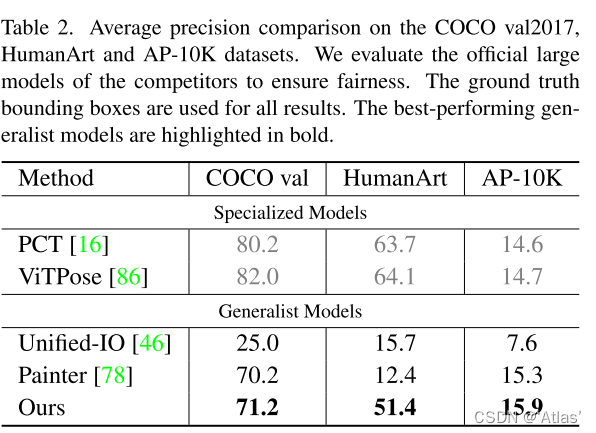
作者在COCO验证集、未见过数据集HumanArt、AP-10K(动物关键点)验证模型泛化性;
测试结果如表2,InstructDiffusion超过其他泛化模型,但与关键点检测模型有一定差距,归因于位置不准确。
在动物关键点数据集AP-10K展示不错效果,如图3.

分割
作者关注模型对开集词汇能力。表3展示引用分割结果,在RefClef数据集取得出乎意料成果。
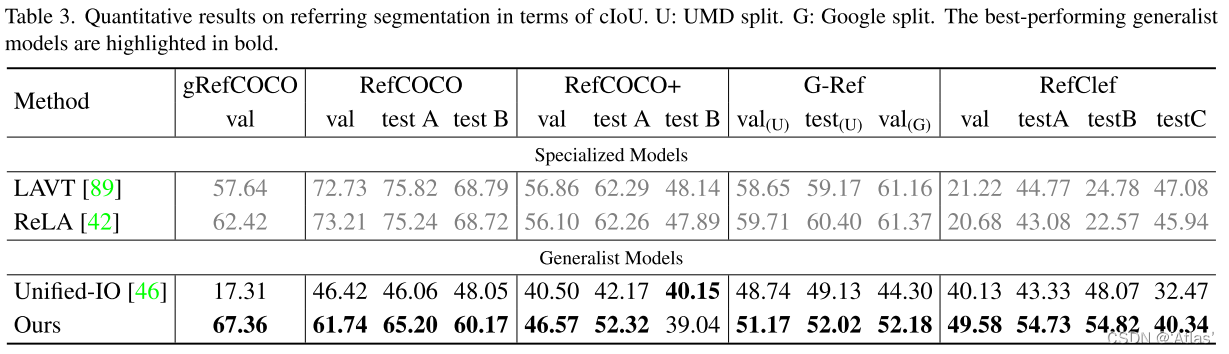
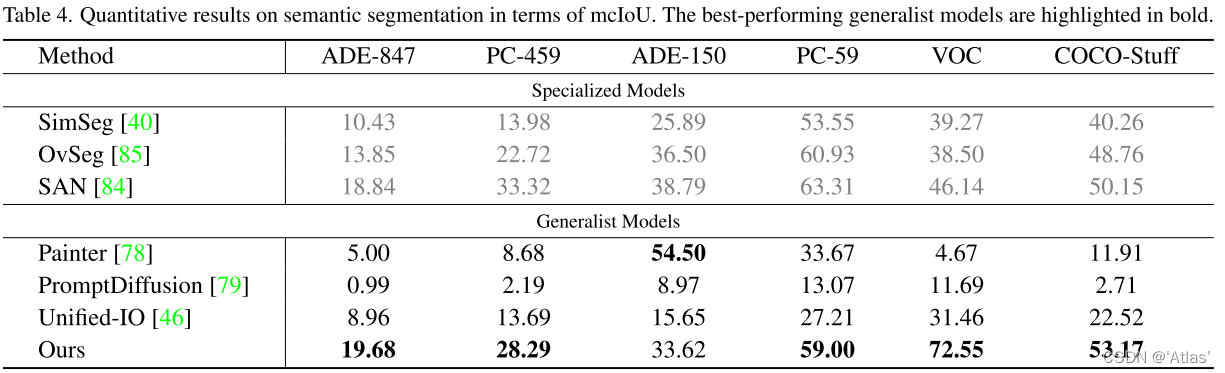
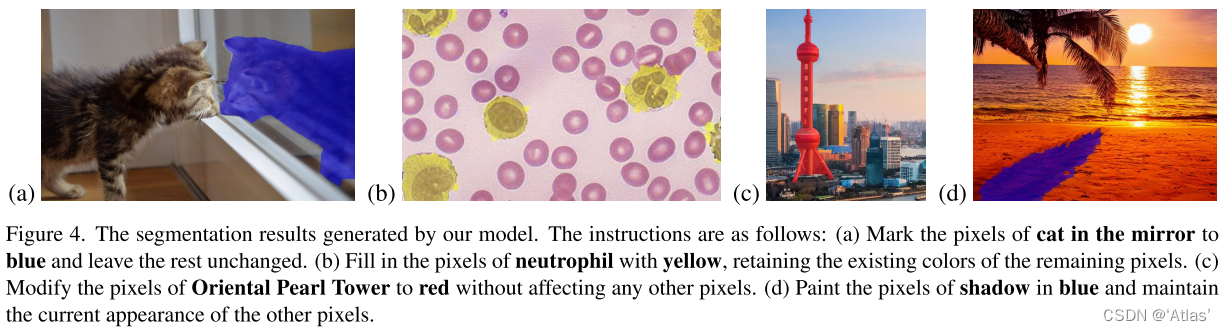
表4展示语义分割量化结果。InstructDiffusion不仅在闭集changjignCOCO-Stuff超过现有专家模型,同时在开集场景也取得有竞争力效果,但在ADE-150K上Painer效果更好,由于Painter在该数据集上训练过。但在Painter和PromptDiffusion难以将颜色与未见过类别联系,这是由于它们通过参考图引导模型将颜色与语义联系,而InstructDiffusion通过文本将它们联系。图4为可视化结果。
图像增强
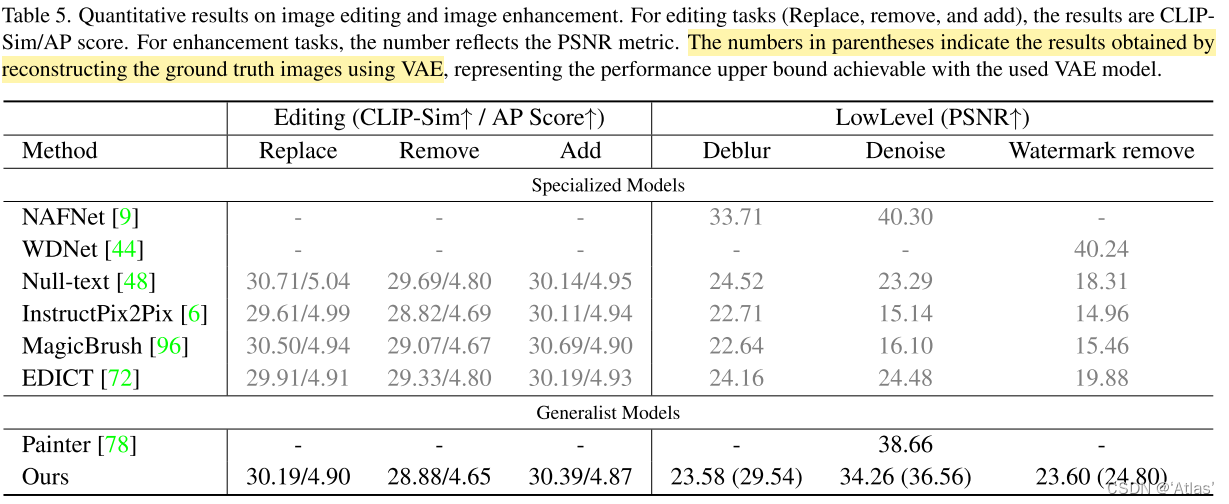
- 图像编辑任务的专家模型在图像增强任务有较差的泛化性;
- Painter在去噪任务表现较好,但在编辑任务遇到挑战;
- InstructDiffusion图像增强性能受限于VAE,括号中为送入VAE真值得到模型上限效果。
图5展示实际应用效果。

图像编辑
使用CLIP及美学预测AP评估生成结果。量化结果如表5,与Instruct-Pix2Pix、MagicBrush性能相当。可视化结果图6、图7,提供原图,可以添加、移除、替换目标。


详细instruction的优势
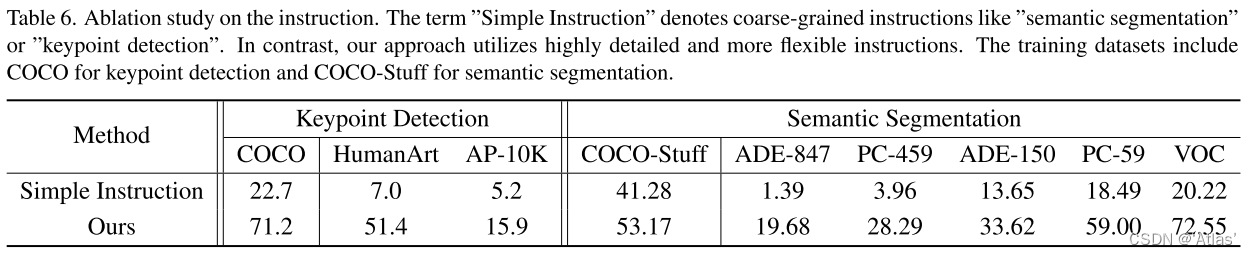
多任务训练优势
图8展示多任务联合训练效果远优于单分割任务训练效果;
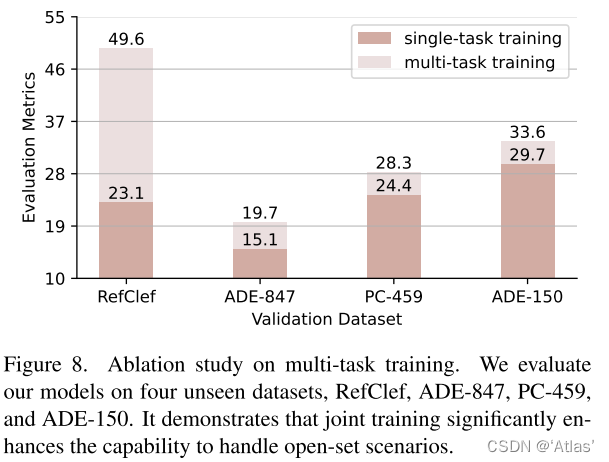
图9展示图像编辑也获得类似收益。

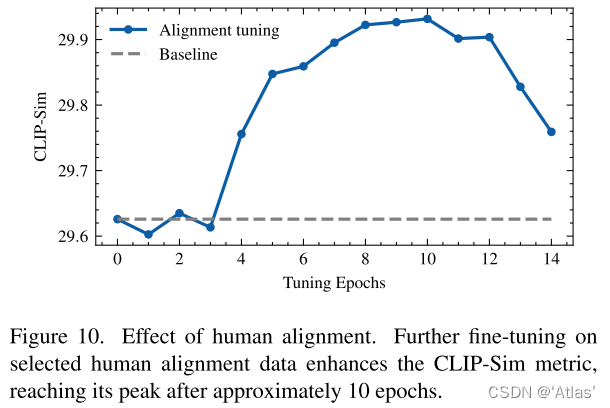
人工校准数据集影响
图10展示人工校准数据集的影响,从29.6提升到29.9
对未见任务的泛化性
图11展示模型对未见过任务的能力,包括检测、分类、甚至细粒度任务。

讨论与结论
本文提出的InstructDiffusion,一种统一框架对齐视觉与instruction,将所有视觉任务看做图像生成,作者证明在多个任务达到不错表现,同时多任务联合训练强化模型泛化性。
未来作者关注以下几点提升模型能力:
1、改进统一表征,可更好表征各种视觉任务输出;
2、研究自监督及无监督学习,使用大规模无标注数据,强化模型泛化性;
个人理解
InstructDiffusion基于InstructPix2PIx扩充训练集用于多种视觉任务,将多种任务看做生成任务,并且联合训练展示出一定泛化性,可用于未见过任务。虽然InstructDiffusion展示出一定通用性,但个人认为比较难超越专家模型。
原文地址:https://blog.csdn.net/qq_41994006/article/details/134688825
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_6299.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!